上证报中国证券网讯(记者杨翔菲温婷)1月21日,全球最大AI开源社区HuggingFace发布的最新数据显示,阿里千问衍生模型数已突破20万个,成为全球首个达成此目标的开源大模型;同时,千问系列模型下载量突破10亿次,平均每天被下载110万次,已完全超越美国Llama,稳居开源大模型全球第一。
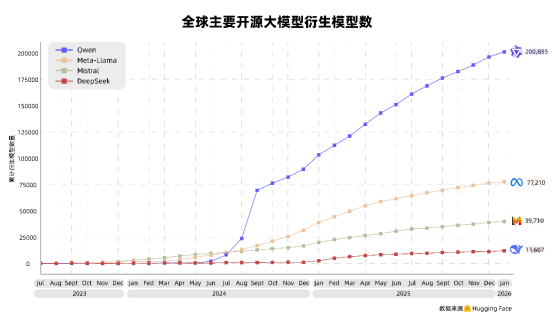
衍生模型数量通常被视为衡量开源模型影响力的最重要指标。
自2023年以来,阿里已开源近400个大模型,全球开发者基于千问模型再开发的模型也出现激增,这些模型又继续开源,反哺和激发出一批新技术和新应用。斯坦福李飞飞团队基于千问训练出新模型s1,进一步拓展了开源社区对AI推理的探索;美国艾伦AI研究所也将千问视为AI社区探索强化学习新技术的“事实基座模型”。
HuggingFace数据显示,全球开发者基于千问的衍生模型每天新增超200个,涵盖机器人控制、代码生成、漫画后期制作、多语种翻译等多个方向。fai.ai基于Qwen-Image-Edit-2511开源模型再训练的多角度相机控制LoRA,成为近期热度最高的AI开发者必备“镜头语言”工具。
模型下载量则是评判开源模型实际应用落地的核心指标。
千问大模型开源覆盖0.5B到480B等“全尺寸”,涵盖文本、视觉等“全模态”,千问3支持119种语言和方言,对于AI硬件落地、多模态应用探索、小语种AI开发尤为友好。
在中国,千问已内嵌入手机、音箱、眼镜等各种智能设备,凭借好用、免费等特性成为最受企业欢迎的开源模型。在海外,亚马逊、爱彼迎等硅谷公司都用千问模型训练机器人、发展新业务;新加坡国家AI计划放弃Meta模型而选择千问作二次开发并开源;在缅甸语、菲律宾语、印尼语、马来语、泰米尔语、泰语和越南语等7种东南亚语言上表现卓越,位列权威评测SEA-HELM中的开源模型第一。