日媒:中国超级计算机时隔8年再次登顶
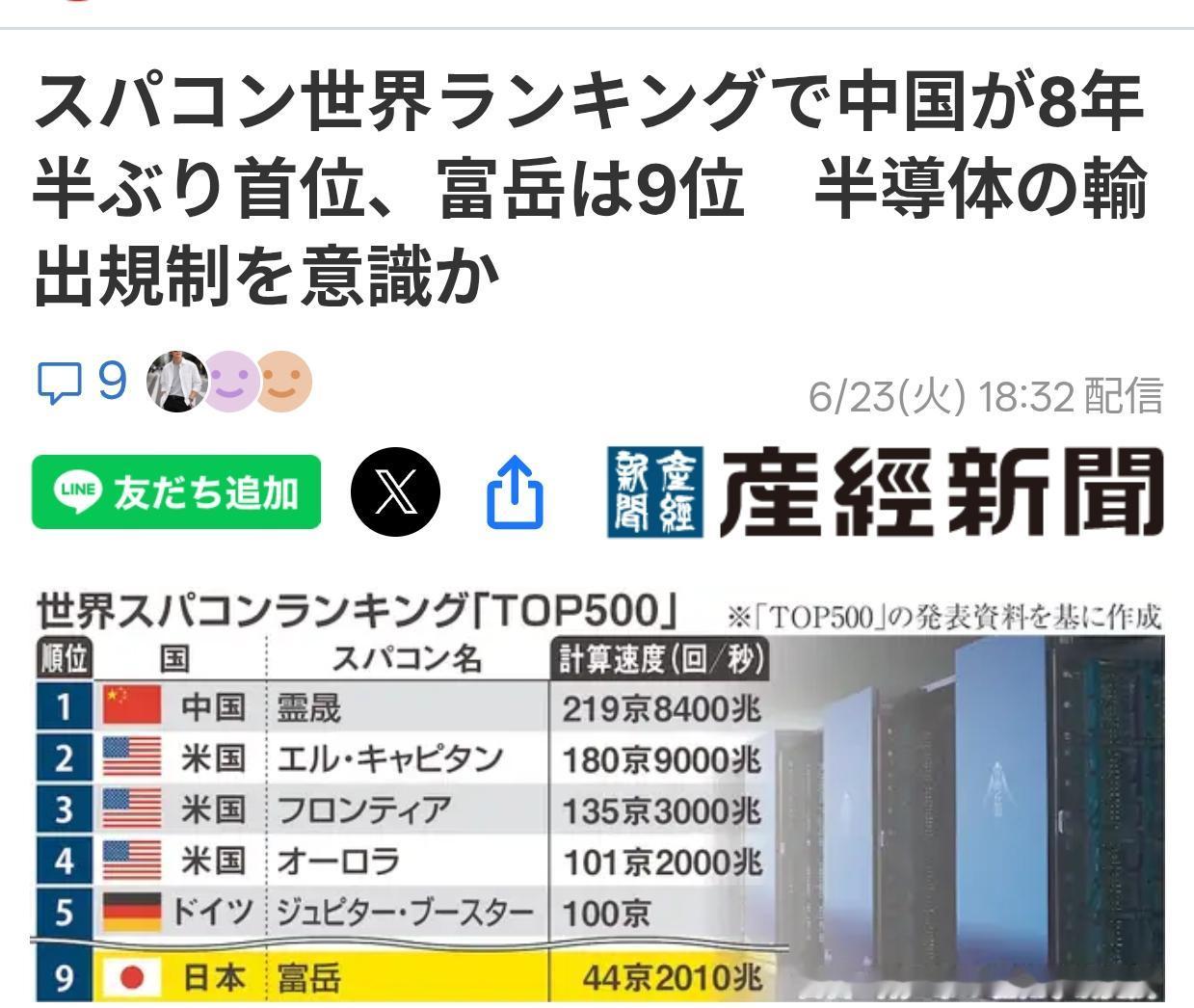
日本《产经新闻》6月23日刊发报道,最新一期全球超级计算机TOP500榜单于当天正式揭晓,中国全新研制的“灵晟(LineShine)”超级计算机拿下全球第一的位置。这是2017年11月之后,中国超算时隔整整八年再度站到世界算力之巅,而曾经长期霸榜的日本超算“富岳”,本期排名滑落至第九位。
这份榜单每半年更新一次,伴随国际超算大会同步发布。能进入TOP500的系统,都代表着当下全球最稳定、最成熟的高速计算能力,考核的是持续稳定运行的综合性能,不是实验室里单次极限测试的纸面数据,含金量一直被行业公认。
这次登顶的灵晟,实测持续双精度浮点性能达到2.198EFlops,也就是每秒能完成219亿亿次浮点运算,是人类历史上第一台持续性能突破2百亿亿次大关的超算系统。
这个数字对普通人来说很抽象,换个直观的说法:如果让全球80亿人每人拿一台计算器,不吃不喝每秒按一次运算键,要连续算近80年才能完成的计算总量,灵晟一秒钟就能全部处理完。
排在榜单第二位的,是美国劳伦斯利弗莫尔国家实验室的El Capitan系统,实测性能约1.8EFlops。灵晟的领先幅度超过21%,优势相当明显。在此之前,美国已经凭借E级超算系统连续多年把持着榜单头名的位置。
最值得关注的核心亮点,是灵晟走了一条和欧美主流超算完全不同的技术路线。
现在全球顶尖超算几乎都靠堆砌高端GPU加速卡来堆叠算力,不管是美国的El Capitan还是欧洲的JUPITER,核心算力都离不开AMD、英伟达的顶级GPU产品。
但灵晟全程没有使用任何一块国外GPU加速卡,完全靠国产LX2 CPU撑起了全部算力,从处理器芯片、高速互连网络,到操作系统、编译工具链,实现了全栈全国产。
这套自研的LX2处理器,单颗就集成了304个计算核心,还内嵌了AI矩阵加速单元,把传统科学计算和AI加速的能力整合在了同一块芯片上。
它同时集成了首颗国产高带宽内存,内存带宽比传统CPU高出10倍,从根源上解决了纯CPU架构数据传输慢、算力调度卡瓶颈的老问题。
整套系统一共用上了近4.7万颗国产CPU,总核心数接近1400万,靠自研的“灵启”高速互连网络串联在一起。
这套网络最多能支持10万个节点、200万个端口的超大规模组网,把海量芯片之间的数据传输延迟压到了极低水平,保证上千万核心能协同高效工作。
能耗表现上灵晟也没有掉队,它首创了100%全液冷的机柜散热方案,能效比达到每瓦51GFlops。在算力冲到世界第一的同时,没有靠盲目堆功耗硬拉性能,在绿色计算上也做到了行业前列。
上一次中国超算站在TOP500榜首,还是2017年的神威·太湖之光。
那之后的八年里,全球超算正式迈入E级时代,美国先后拿出Frontier、El Capitan等系统长期占据头名,加上高端计算芯片出口管制持续收紧,中国超算有很长时间没有在公开榜单上冲击头名位置。
这次灵晟的正式亮相,相当于直接用全自主的技术路线,跨过了E级超算的门槛,还直接冲到了全球最前面。
另一边,日本的“富岳”超算曾经在2020到2022年连续霸榜两年多,是日本超算产业的标杆之作。
本期榜单中它以442PFlops的性能排在第九位,和巅峰时期的排名相比逐步下滑,也侧面反映出全球超算算力迭代的速度正在不断加快。
很多人会觉得超算就是跑个分争排名,离日常生活很远,其实完全不是这样。超算是高端科研和工业研发的“国之重器”,从精准的气候模拟、台风路径预报,到航空航天的气动外形仿真,再到新材料研发、新药分子模拟,甚至脑科学研究、AI大模型训练,都离不开顶级超算的支撑。
灵晟从部署到现在,已经在大气海洋、工程仿真、材料科学、药物发现等多个领域落地应用,千万核心规模的并行任务平均扩展效率能达到84.4%。
它不是只能跑基准测试的“跑分机器”,而是真真切切能给科研和产业赋能的算力基础设施。
这次登顶的分量,远不止一个排名第一那么简单。
在全球高端计算芯片管制不断收紧的大背景下,灵晟用纯国产CPU的路线跑出了全球第一的算力,直接打破了“没有顶级GPU就做不出E级超算”的固有认知,证明中国已经具备从底层硬件到上层软件,全链条自主构建顶级超算的能力。
就连图灵奖得主Jack Dongarra也评价称,灵晟让全球看到了超算走向AI赋能科学研究的新方向。
对普通大众来说,超算可能不会直接出现在生活里,但每一次超算技术的突破,最终都会转化为更精准的气象预报、更快的新药研发、更强的工业产品性能。
时隔八年重回榜首,不是中国超算的终点,而是自主技术路线上的一个全新起点。