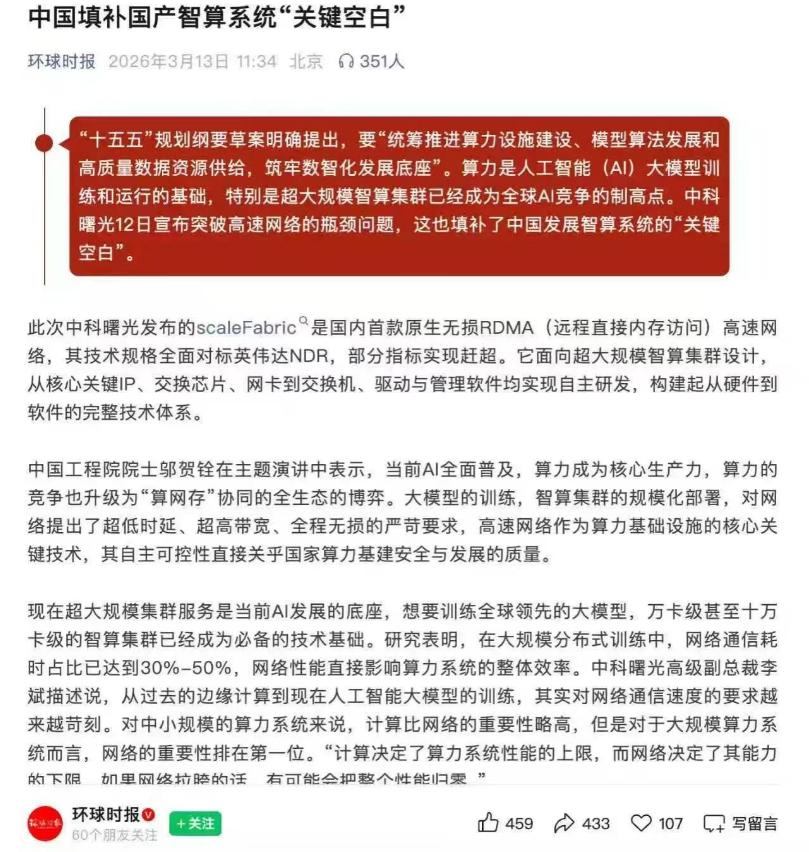
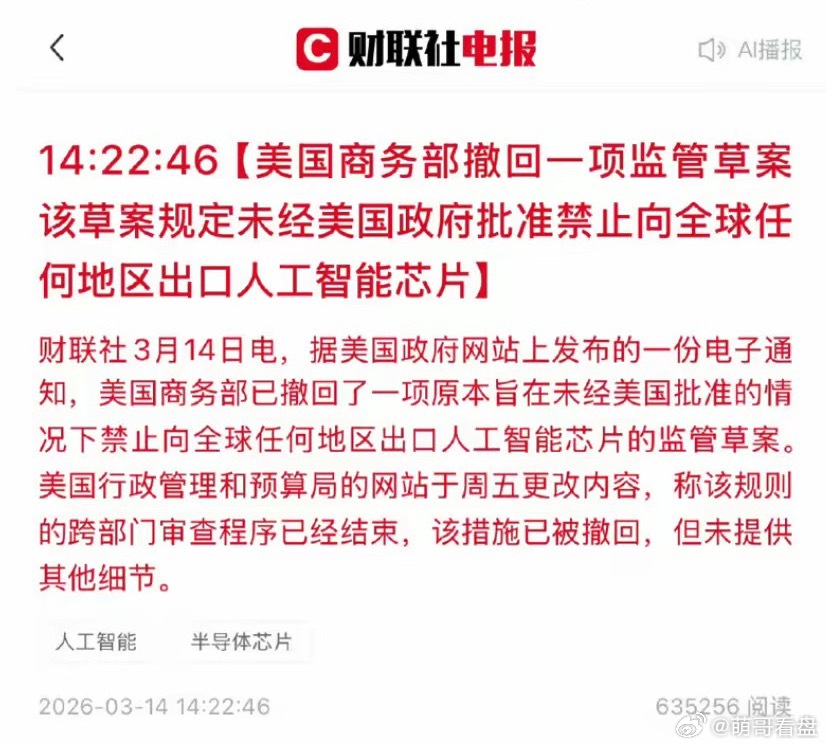
不但美国震惊了,日本、德国等西方列强也震惊了,就连马斯克也弄不明白,中国在西方构筑的铜墙铁壁之下,也能取得突破性的成就! 西方国家已经认识真相,中国已经从当初的”追赶者“变成了”引领者“,他们不得不承认,只有与中国合作才能取得突破,这是谁也无法改变的事实。 中科曙光这次发布的scaleFabric,绝不仅仅是一款网络设备的更迭,而是一场迟到已久的“血管疏通手术”,更是中国AI算力大厦彻底摆脱“脑缺血”风险的关键一步。 西方多年来在高端科技领域构筑的壁垒,曾被认为是难以逾越的铜墙铁壁。尤其是在AI算力的核心支撑环节,高速网络作为连接计算资源的关键脉络,长期被海外厂商垄断。 从底层的核心芯片、传输IP,到上层的交换机硬件和管理软件,整条产业链都被少数西方企业把控,形成了技术和市场的双重封锁。 中国此前在超算和智算领域的发展,始终绕不开这道坎,只能依赖进口的InfiniBand网络方案,不仅采购成本高昂,还时刻面临供应链被切断的风险,这成为制约中国AI算力发展的隐形枷锁。 随着AI大模型迈入万亿参数时代,算力集群规模迅速升级到万卡、十万卡级别,网络的重要性被无限放大。 在大规模分布式训练中,网络通信耗时占比能达到30%到50%,如果网络性能跟不上,再强大的计算芯片也无法发挥作用。 传统以太网的延迟和丢包问题,根本满足不了低时延、高带宽、全程无损的严苛需求,而西方的专用网络方案又不断抬高合作门槛,这让中国AI算力的进一步突破陷入瓶颈。 中科曙光scaleFabric的发布,彻底打破了这种僵局。这款产品最关键的突破在于全栈自研,从底层的112G SerDes IP、网卡与交换核心芯片,到硬件设备,再到上层的驱动和管理软件,实现了100%自主研发,完全摆脱了对海外技术的依赖。 这不是简单的设备更迭,而是对整个高端高速网络产业链的重构,相当于为中国AI算力大厦做了一场精准的“血管疏通手术”。 在核心性能上,这款产品全面对标甚至超越国际顶尖水平。网卡端到端通信时延低至0.9微秒,交换机转发时延仅260纳秒,这种极致的速度让数据在算力节点间的传输几乎没有延迟。 同时,它的交换容量达到双向64Tbps,单端口带宽最高支持800G,能轻松承载万卡级集群的海量数据传输需求。 更重要的是,它解决了传统网络的拥塞丢包问题,通过硬件层面的无损流控机制,实现全程零丢包,让算力资源不再因网络瓶颈而浪费。 扩展能力和成本控制上的优势,更让这款产品具备了大规模普及的基础。它单子网最大可支持11.4万卡集群部署,是传统方案的2.33倍,能满足未来算力集群持续扩容的需求。 交换机端口密度提升25%,整体组网成本却下降30%,既保证了性能,又打破了西方产品的高价垄断。 而且它还实现了与现有IB生态的全面兼容,应用无需修改代码就能直接迁移,大大降低了用户的使用门槛。 这款产品已经不是实验室里的概念,而是实现了量产现货交付的成熟方案。在国家超算互联网郑州核心节点,它已经完成了3万卡规模的万卡级集群部署,仅用36小时就完成了三套集群的网络搭建,至今已稳定运行超10个月,累计服务上万客户、承载十万级以上作业。 这种快速落地和稳定运行的表现,证明了中国在高端高速网络领域的技术已经完全成熟,不再是纸上谈兵。 这一突破让西方世界不得不重新审视中国的科技实力。曾经他们以为通过技术封锁就能遏制中国的发展,却没想到中国用三年时间完成了,全栈自研的跨越式突破。 随着中国智能算力规模的高速增长,预计2026年将达到2024年的两倍,这样庞大的算力需求,只有自主可控的网络系统才能提供可靠支撑。 西方企业逐渐发现,封锁不仅没能阻挡中国,反而倒逼中国建立了完整的自主产业链,而他们自己却失去了巨大的市场机会。 更重要的是,中国的突破不再是单点技术的赶超,而是形成了“算、存、传”一体化的自主架构。 通过高速互联、分布式存储、GPU直连通信等技术的深度协同,让整个算力系统的效率得到质的提升。 这种系统性的突破,标志着中国已经从过去的技术追赶者,真正变成了规则制定者和引领者。 西方国家的态度也随之转变,从最初的封锁打压,逐渐转向寻求合作。 因为他们清楚,在AI算力爆发式增长的时代,没有任何一个国家能独善其身。中国的自主技术不仅解决了自身的“脑缺血”问题,还能为全球算力网络提供更高效、更经济、更安全的解决方案。 拒绝合作,就意味着错失算力革命的机遇,这是任何国家都不愿承担的代价。