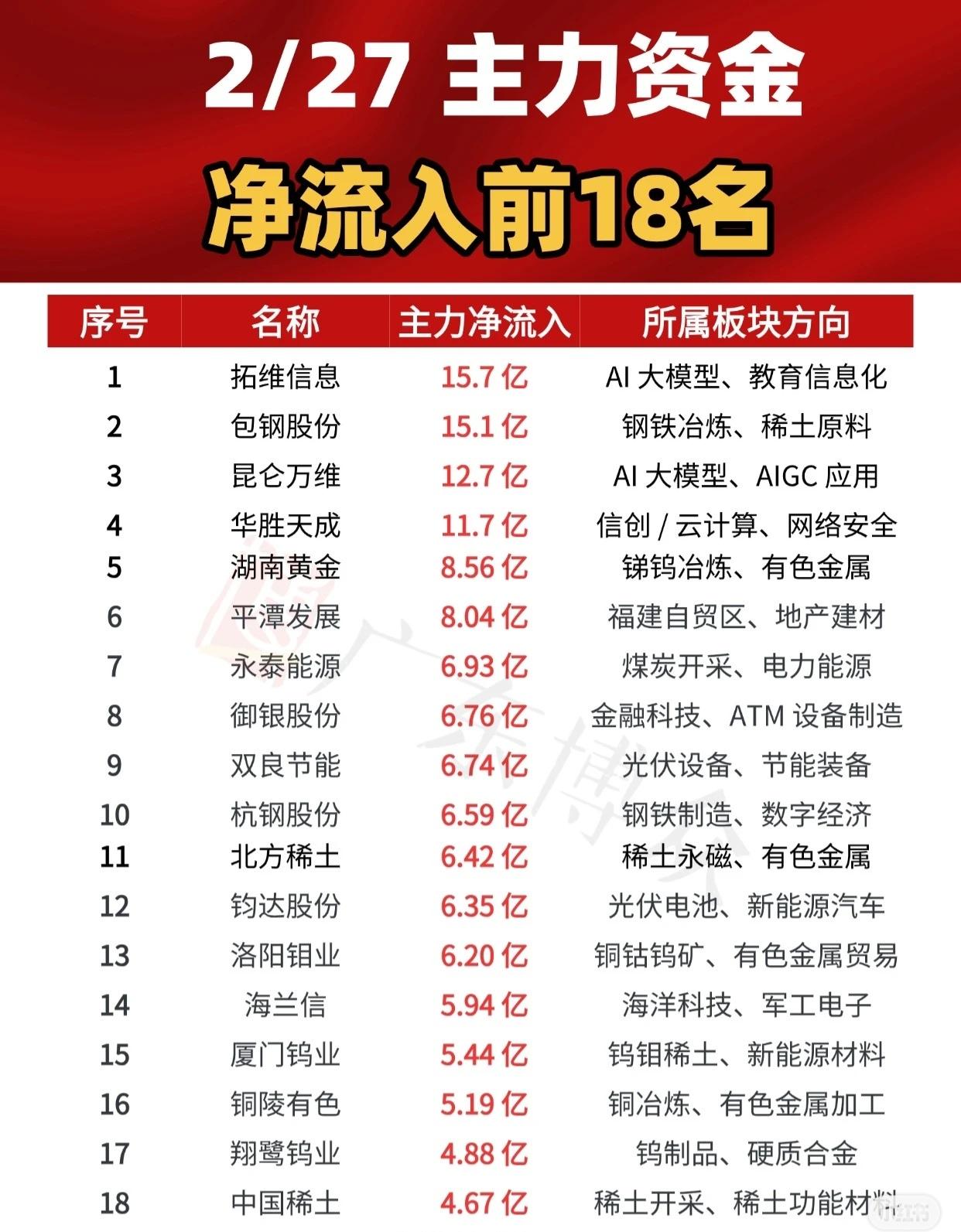
华胜天成(SH600410) 拓维信息(SZ002261) 润泽科技(SZ300442) 别被OpenRouter骗了,中国的真实Token输出是恐怖的天文数字 最近全网都在刷OpenRouter的Token排行榜,看着国内四款大模型霸榜全球前五,很多人把这组数据当成了中国AI的真实体量。但只要拆透统计规则和行业真实数据就会发现,这个榜单只展示了冰山一角,真正的Token规模,被严重低估。 OpenRouter作为全球最大的大模型API聚合平台,它的统计范围非常局限,只覆盖了通过其平台转发的B端开发者API调用量,仅此而已。而真正决定行业格局的几大块核心数据,它完全没有纳入统计。 首先是各家头部模型的自有C端用量。OpenRouter榜单里的MiniMax、Kimi、GLM、DeepSeek这四家,在自有App、官网、内置合作入口的C端用户对话量,一分钱都没被算进榜单里。从行业通用测算和多家券商研报交叉验证的数据来看,这些模型的C端Token消耗,普遍是OpenRouter上显示API用量的5到10倍。仅MiniMax一家,C端周Token用量就轻松突破12万亿到24万亿,四家头部文本模型的C端合计周用量,稳定在40万亿以上,是OpenRouter上统计值的近8倍。 更颠覆认知的,是视频生成模型带来的Token爆炸,这也是榜单完全忽略的巨量板块。很多人没意识到,视频模型消耗的Token和文本完全不是一个量级,行业通用测算显示,Seedance 2.0生成一条10秒720P的视频,就要消耗约35万Token,相当于几十万字的文本对话。春节前后C端爆发的峰值阶段,行业测算日均视频生成量约300万条,单日折算下来的Token消耗就达到10.5万亿,一周就是73.5万亿,这个数字,相当于OpenRouter当周所有模型统计总量的8.4倍。 和它同类型的OpenAI Sora,同样因为不走OpenRouter渠道、Token统计口径和文本不互通,也完全没有出现在榜单里。 把这些未统计的部分全部加总:头部文本模型C端周用量约40万亿,Seedance 2.0峰值周用量约73.5万亿,再加上大量企业直连API、政企私有化部署的增量,国内真实的周Token输出,稳定在120万亿到150万亿的区间,而OpenRouter只统计到了5.16万亿,覆盖率不足5%。 国内Token用量能实现这种规模的爆发,不是单纯靠用户基数堆出来的,核心是有扎实的技术架构和成本结构做底层支撑。 技术路线上,国内头部模型普遍采用MoE混合专家架构,和海外大厂主流的稠密模型不同,这种架构会把大模型拆成多个专家网络,单次推理只激活和任务相关的少数专家,同等硬件条件下,显存占用能降低约60%,吞吐量提升近19倍,算力利用率远超传统稠密模型,直接把单位Token的算力成本压到了极致。 再加上能源成本的结构性优势,国内西部算力中心的绿电电价在0.2-0.3元/度,仅为美国的1/3,而电力成本占Token总成本的70%以上,这种物理级的优势,直接转化成了定价竞争力。目前OpenRouter平台上,国内模型百万输入Token的价格低至0.3美元,而海外头部模型Claude Opus 4.6的价格高达5美元,成本差距超过16倍。 低成本推动了规模化普及,规模化带来的海量Token又反过来推动数据迭代、模型优化、效率再提升,形成了一套非常扎实、可持续的正向循环。 当然也要客观承认,在基础模型框架、顶尖能力对齐、全球开发者生态完善度这些核心维度,我们和美国最前沿的水平依然存在差距,这一点无需回避。但在推理效率、Token成本、规模化落地速度、C端场景渗透这几个赛道,国内模型确实走出了非常明确且可持续的优势。 OpenRouter的榜单可以作为参考,但绝对不能当成行业的全貌。它只反映了海外开发者API市场的一个小切面,真正决定AI产业未来格局的,是C端流量、视频生成、企业级直连与私有化部署这些没被公开统计的部分。那些看不见的天文数字,才是中国AI最真实的基本面。