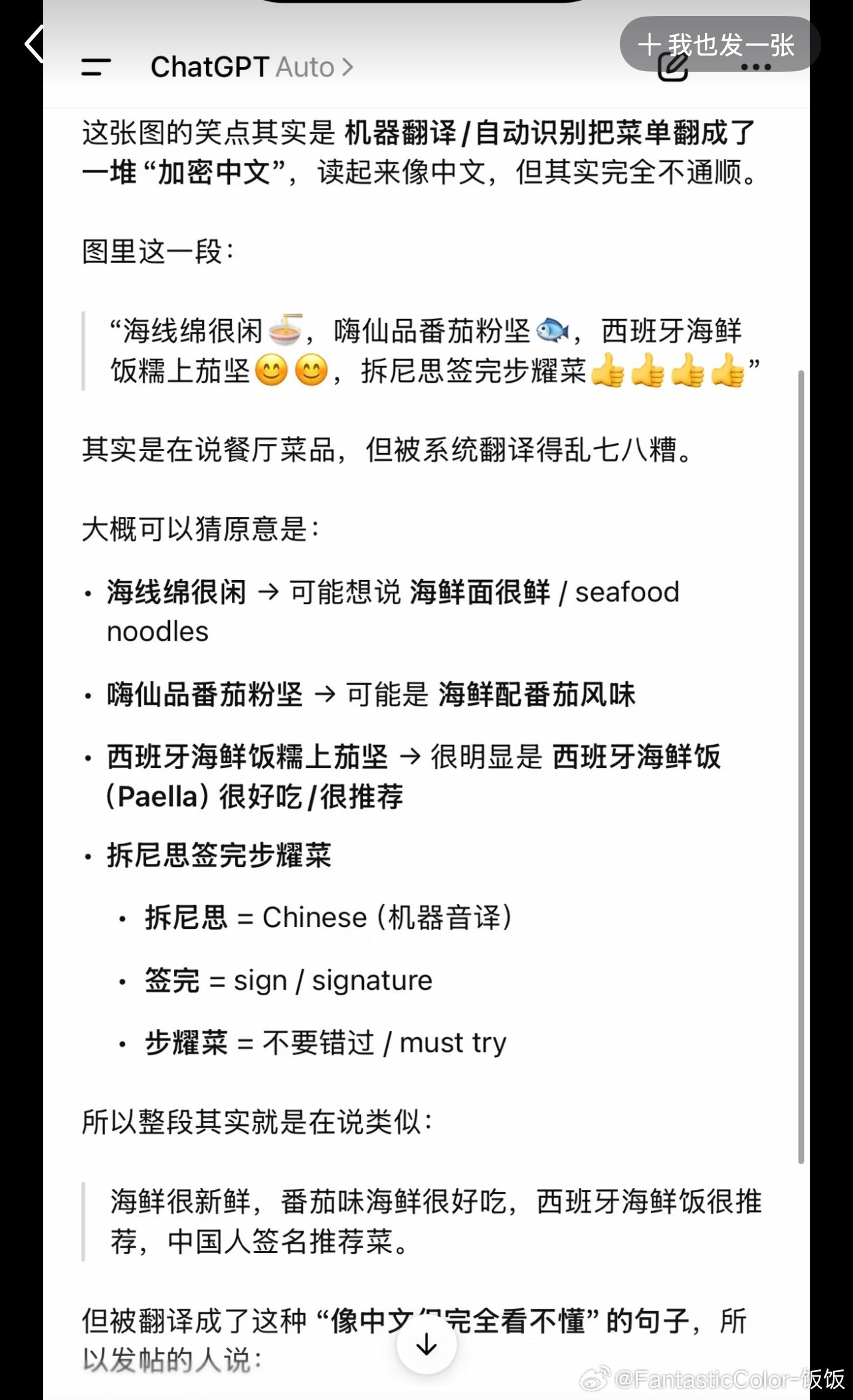
终于到日本用中国 AI 来冒充日本产 AI 的时代了!

妮儿最近刷到这件事的时候,真的越看越觉得离谱。
咱们普通用户可能没太关注到这件事,我特意去核对了全流程的信息。
日本乐天集团前段时间,刚高调发布了自家的 Rakuten AI 3.0 模型。
官方对外宣称,这是日本规模最大、性能顶尖的大语言模型。
甚至还拿到了日本政府相关项目的算力补贴,妥妥的本土 AI “全村希望”。
结果没几天,这个所谓的自研最强 AI,就被开源社区直接扒了个底朝天。
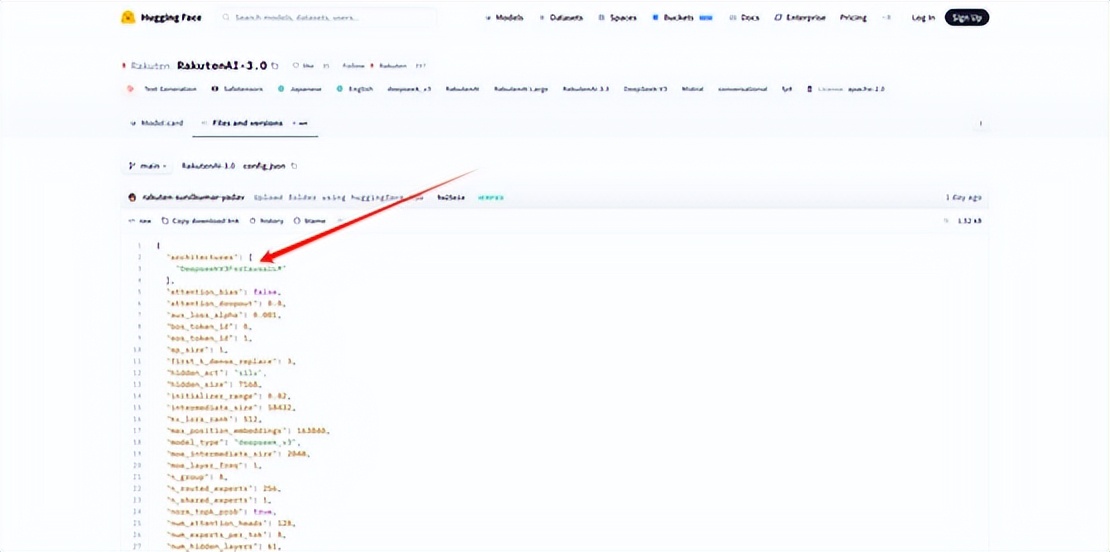
妮儿专门去 Hugging Face 平台,核对了相关的配置文件和提交记录。
这个号称日本全自研的模型,底层架构完全来自中国的 DeepSeek-V3。
乐天做的所有改动,仅仅是加了一层日文微调,核心代码基本没动过。
更让人无语的是,它发布全程,完全隐瞒了 DeepSeek 的技术来源。
妮儿翻遍了乐天当时发布的官方新闻通稿,全程都在堆亮眼的参数。
通稿里反复强调 7000 亿参数、MoE 架构,还有所谓的行业顶尖跑分。
对核心技术来源,只含糊提了一句 “融合开源社区精华”,半字没提 DeepSeek。
甚至最开始发布的时候,它直接删掉了 DeepSeek 原有的 MIT 开源协议文件。
转头就换成了 Apache 2.0 协议,明摆着想把开源成果直接据为己有。
妮儿身边做开源技术的朋友,特意帮我核对了完整的平台提交历史。
社区最早发现问题,就是在配置文件里看到了完整的 DeepSeek-V3 架构标识!

哪怕乐天后来被发现后,紧急补上了 MIT 协议,修改记录也全留在平台上。
更有意思的是,它对外晒的性能跑分,连对比的基准都藏着小心思。
要么是已经下架的旧版本模型,要么是参数远小于它的小模型,胜之不武。
就连这个模型的负责人,还是日本出了名的移民强硬派,本土网友都炸锅了。
说实话,开源模型加本土化微调,本来就是行业里很常见的合规做法。
妮儿之前也实测过不少同类型的二次开发模型,比如日本 ABEJA 的 QwQ 32b 模型。
人家就明明白白标注了底层来自 Qwen 开源模型,合规合理,没人会说半句不对。
咱们普通用户也都懂,站在巨人的肩膀上做优化,本身根本不是丢人的事。

这件事的核心争议,从来都不是它用了 DeepSeek 的开源技术。
而是它用了别人的技术成果,却拼了命想把来源藏起来,抹掉原作者的所有痕迹。
妮儿特意去核对了 MIT 开源协议的完整官方规则,这个协议真的已经非常宽松。
它允许任何人免费商用、修改、二次分发,唯一的硬性要求,就是保留原版权声明。
说白了,人家只要求你提一句技术来自哪,连这点最基本的要求,乐天都不愿意满足。
这件事背后,其实藏着日本 AI 产业现在面临的巨大尴尬困境。

妮儿核对过日本 GENIAC 本土 AI 项目的相关官方规划,初衷就是摆脱对外技术依赖。
结果拿着政府专项补贴的本土巨头,转头就套壳中国开源模型,还想瞒天过海。
这波操作,直接把项目的初衷,变成了一个彻头彻尾的笑话。
现在全球 AI 竞赛里,算力和研发成本的压力越来越大,想两头占好处真的太难了。
更值得咱们骄傲的是,DeepSeek 这些中国开源模型,早就成了全球 AI 发展的核心基础设施。
妮儿核对过第三方权威机构的统计数据,日本排名前十的开源大模型里,有大半都是基于中国开源模型二次开发的。
咱们中国的 AI 技术,早就不是跟着别人走的追赶者了。
现在已经成了别人要靠着咱们的技术,才能撑得起本土自研门面的存在。
说实话,开源圈子最看重的,就是规则意识和最基本的商业诚信。
你用了开源社区的成果,享受了别人免费开放的技术红利,就得遵守最基本的协议规则。
想靠着别人的技术给自己贴金,甚至偷换协议抹掉原作者的贡献,迟早都会被拆穿。
咱们普通用户看这些事,也能更清楚,真正的技术实力,从来都不是靠包装吹出来的。
对了,最近 DeepSeek V4 的相关消息,也已经有不少业内爆料了。
你们觉得,接下来还会有多少海外厂商,偷偷用咱们的开源模型搞包装?
欢迎在评论区聊聊你的看法,咱们一起蹲后续的相关进展!