群发资讯网
孤鸿泽的文章
来兰州拉面吃饭,不要点面加肉,而是纯拉面配一盘拌牛肉。
2026-06-17 13:35
来兰州拉面吃饭,不要点面加肉,而是纯拉面配一盘拌牛肉。
美股多头斩,全靠流动性撑着击鼓传花的游戏,在哪其实都一样。
2026-06-06 09:14
美股多头斩,全靠流动性撑着击鼓传花的游戏,在哪其实都一样。
轻仓吃肉,重仓挨打
2026-06-01 16:11
轻仓吃肉,重仓挨打
一定要注意防骗,有几个骗子长期冒充我拉人入群。所有购买课程的用户,会在guda.
2026-06-01 14:00
一定要注意防骗,有几个骗子长期冒充我拉人入群。所有购买课程的用户,会在guda.
注意防骗,这个是骗子号。
2026-06-01 13:24
注意防骗,这个是骗子号。
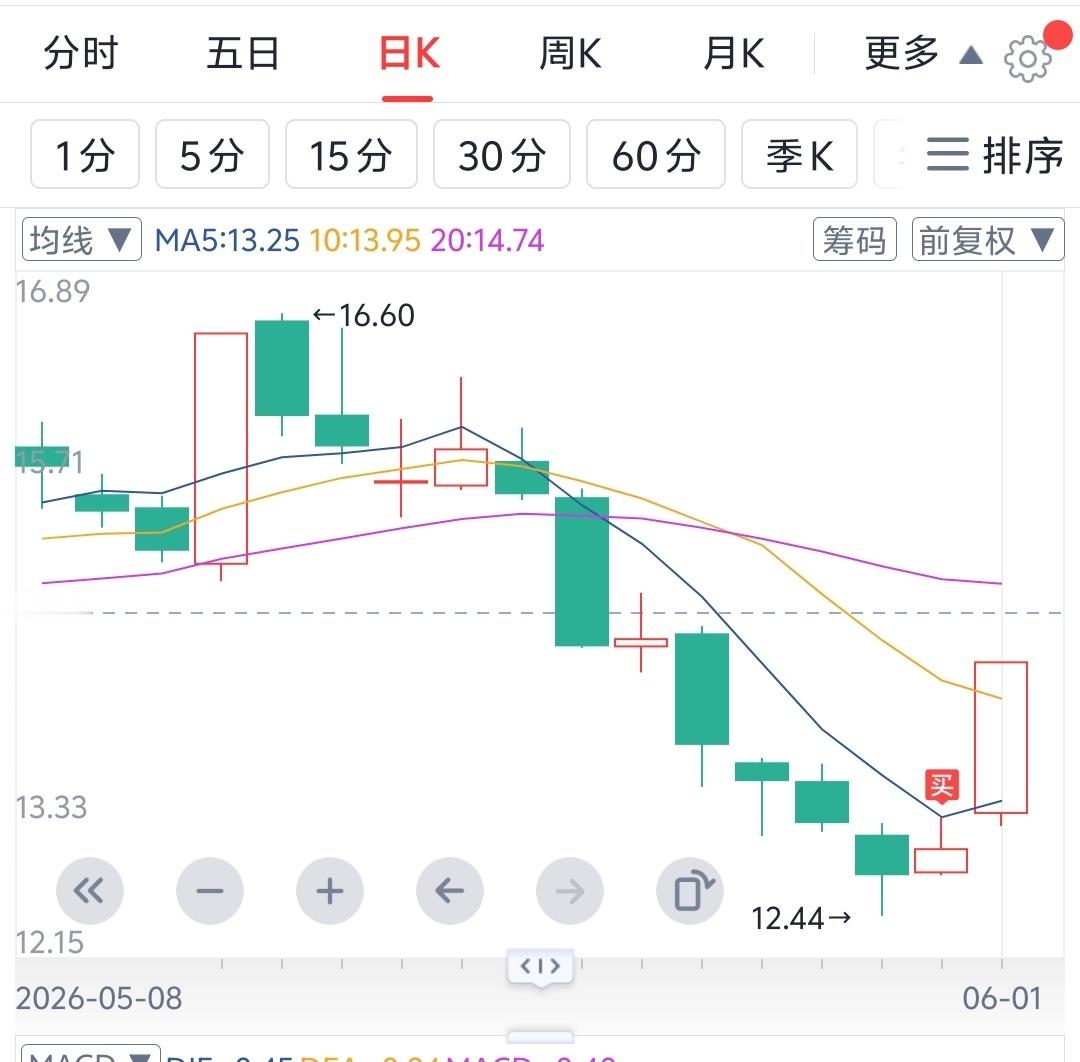
该撤退不能恋战,调整好了再回来。
2026-05-29 15:04
该撤退不能恋战,调整好了再回来。
看我这双鞋好看不,我现在已经提前进入老年生活节奏
2026-05-29 15:04
看我这双鞋好看不,我现在已经提前进入老年生活节奏
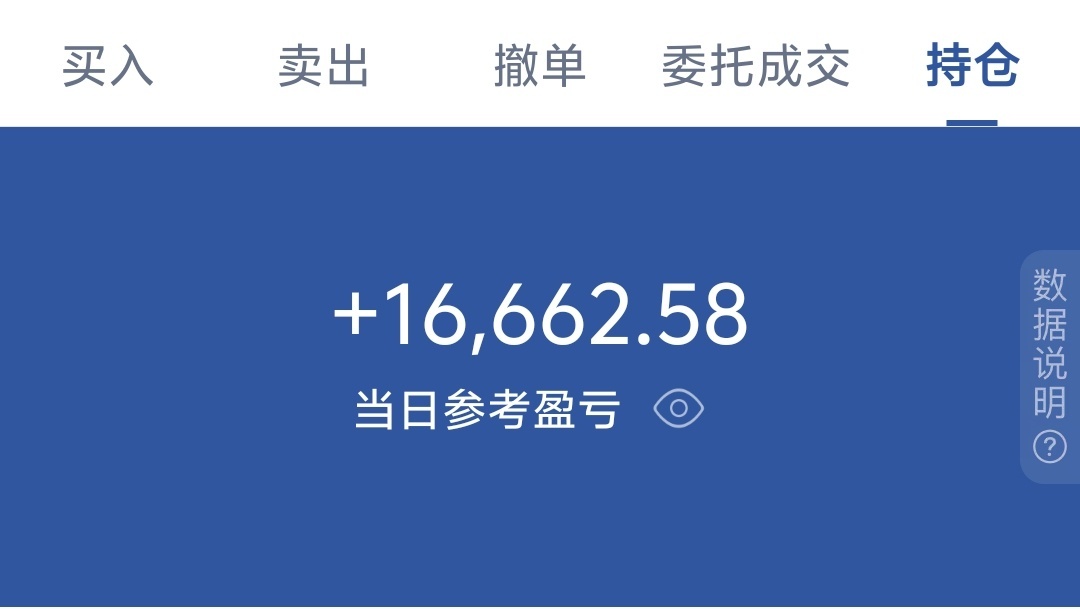
账户都靠良心想撑住了,这会是真良心
2026-05-29 15:04
账户都靠良心想撑住了,这会是真良心
这个号粉丝过50万了,有点太招摇了,哈哈。我对大V不感兴趣,主要喜欢低调。咱这回
2026-05-28 12:51
这个号粉丝过50万了,有点太招摇了,哈哈。我对大V不感兴趣,主要喜欢低调。咱这回
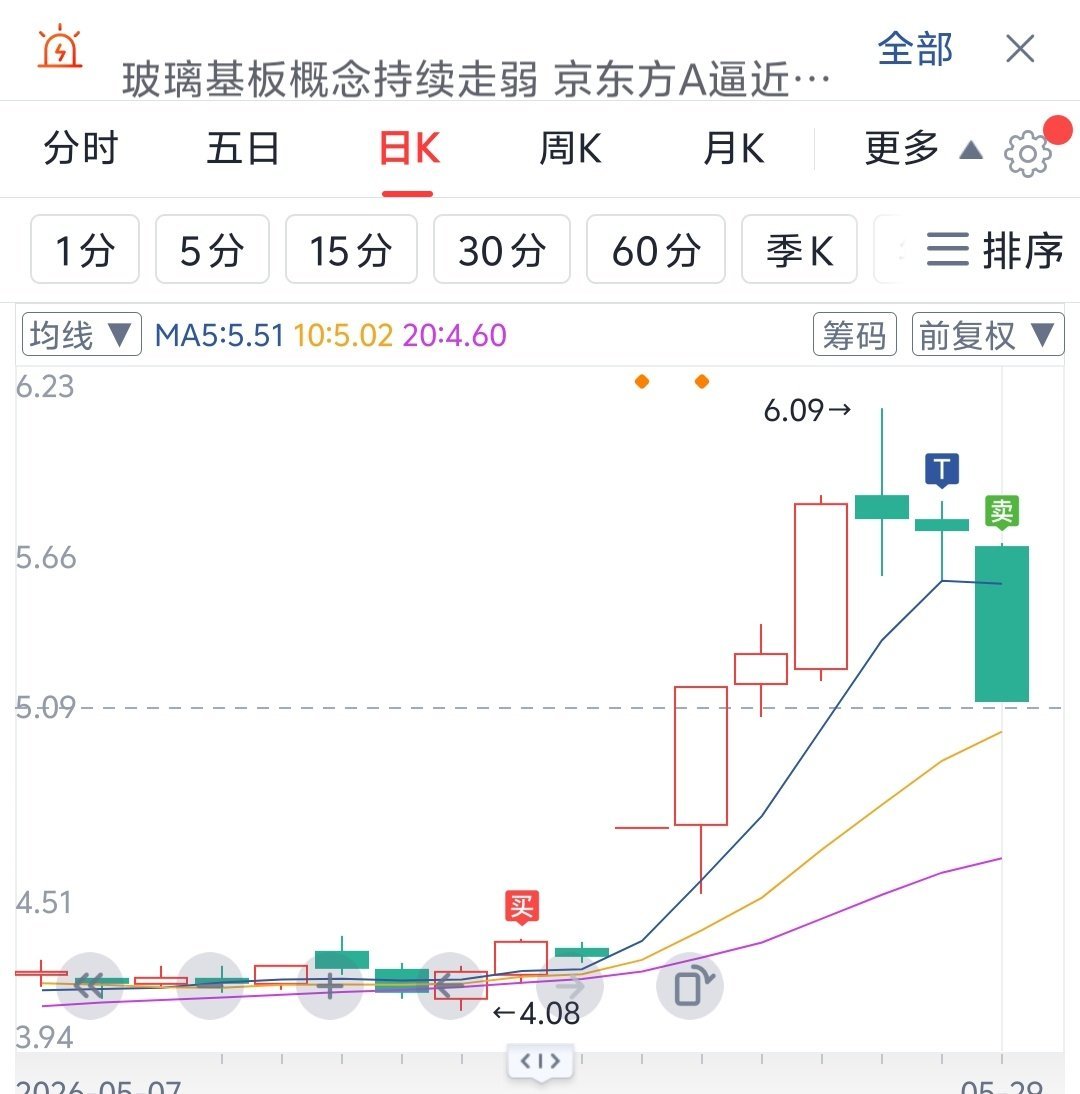
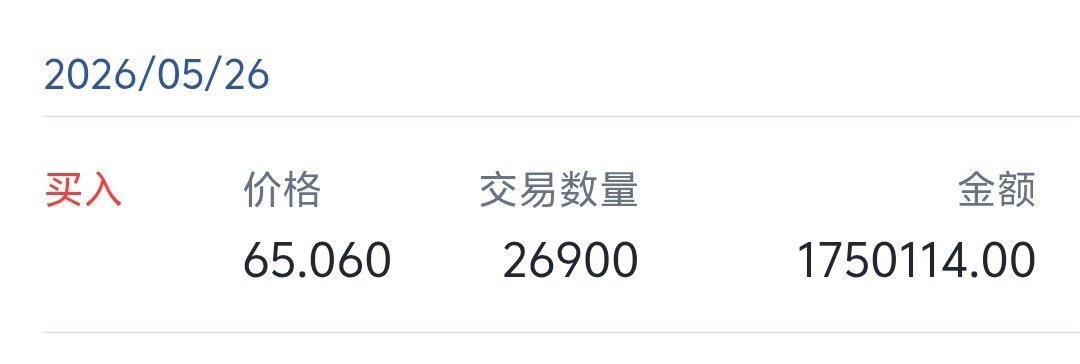
昨天这个板就是送钱,这就叫必然性。
2026-05-28 10:51
昨天这个板就是送钱,这就叫必然性。
服务器环境可以选择不用英伟达,用华为昇腾解决方案也可以,能提供服务就行。但个人生
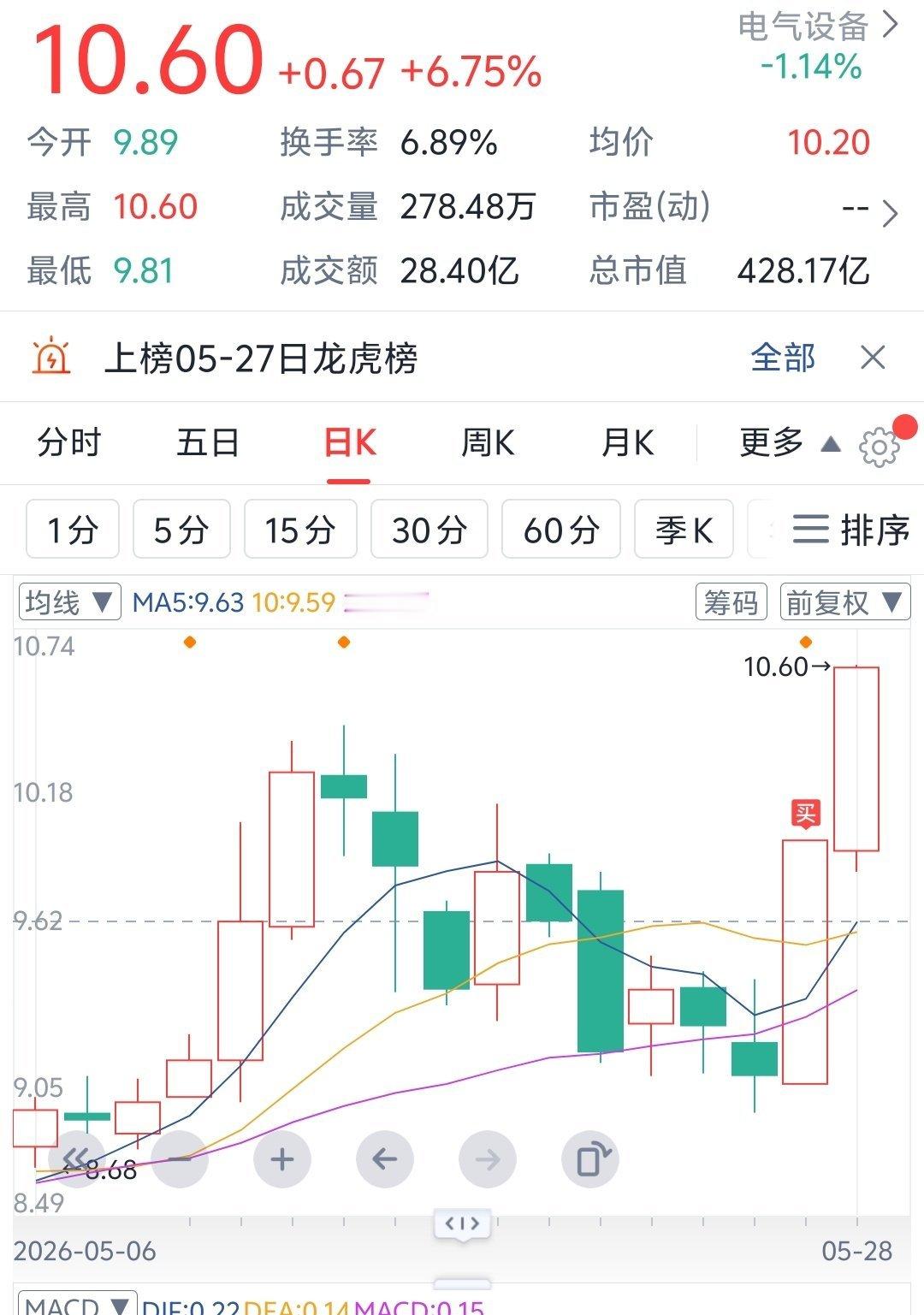
2026-05-27 22:50
服务器环境可以选择不用英伟达,用华为昇腾解决方案也可以,能提供服务就行。但个人生
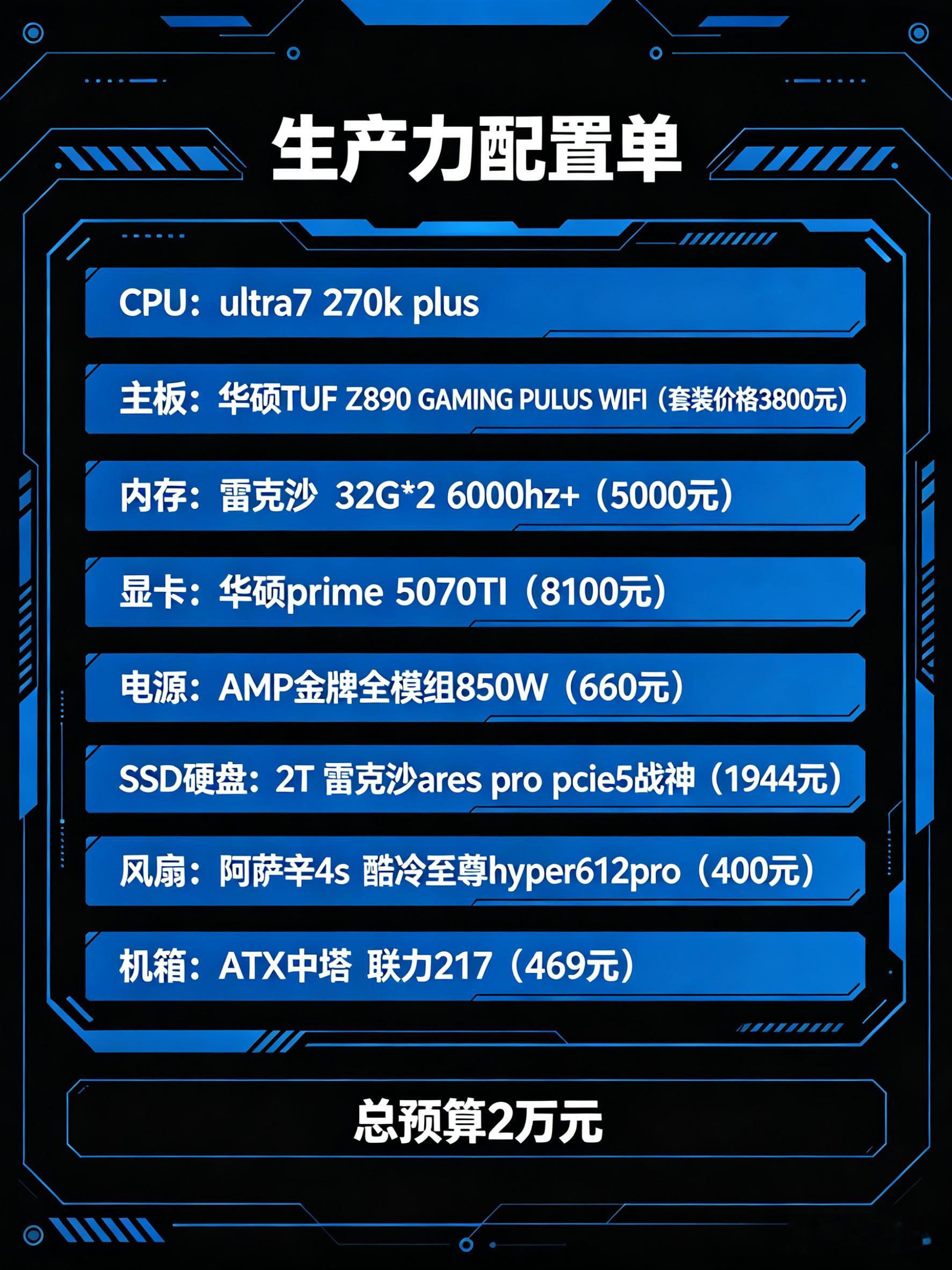
本地AI的几个推荐配置,入门级预算1.3万,生产力级2万,专业级3.6万,工作站
2026-05-27 17:50
本地AI的几个推荐配置,入门级预算1.3万,生产力级2万,专业级3.6万,工作站
昨天梭哈错了,大盘连续吃面,我在这种局面下能稳住持仓,就问你狠不狠
2026-05-27 14:54
昨天梭哈错了,大盘连续吃面,我在这种局面下能稳住持仓,就问你狠不狠
能让你赚钱的票不会让你亏钱,多么朴素的规律啊。也就是说当一只票长期让你账面浮亏,
2026-05-27 11:50
能让你赚钱的票不会让你亏钱,多么朴素的规律啊。也就是说当一只票长期让你账面浮亏,
有同学问《AI应用课》的推荐配置清单,我下午发一个系列推荐配置,覆盖不同价位。报
2026-05-27 08:50
有同学问《AI应用课》的推荐配置清单,我下午发一个系列推荐配置,覆盖不同价位。报
guda.cn上架了全新课程《AI应用班》的报名通道。招生简章详见 网页链接培训
2026-05-27 08:50
guda.cn上架了全新课程《AI应用班》的报名通道。招生简章详见 网页链接培训
如果一个人啥也没干,先造出一堆玄乎名词出来,那准是忽悠。我们老家那里的牛逼匠子造
2026-05-26 23:49
如果一个人啥也没干,先造出一堆玄乎名词出来,那准是忽悠。我们老家那里的牛逼匠子造
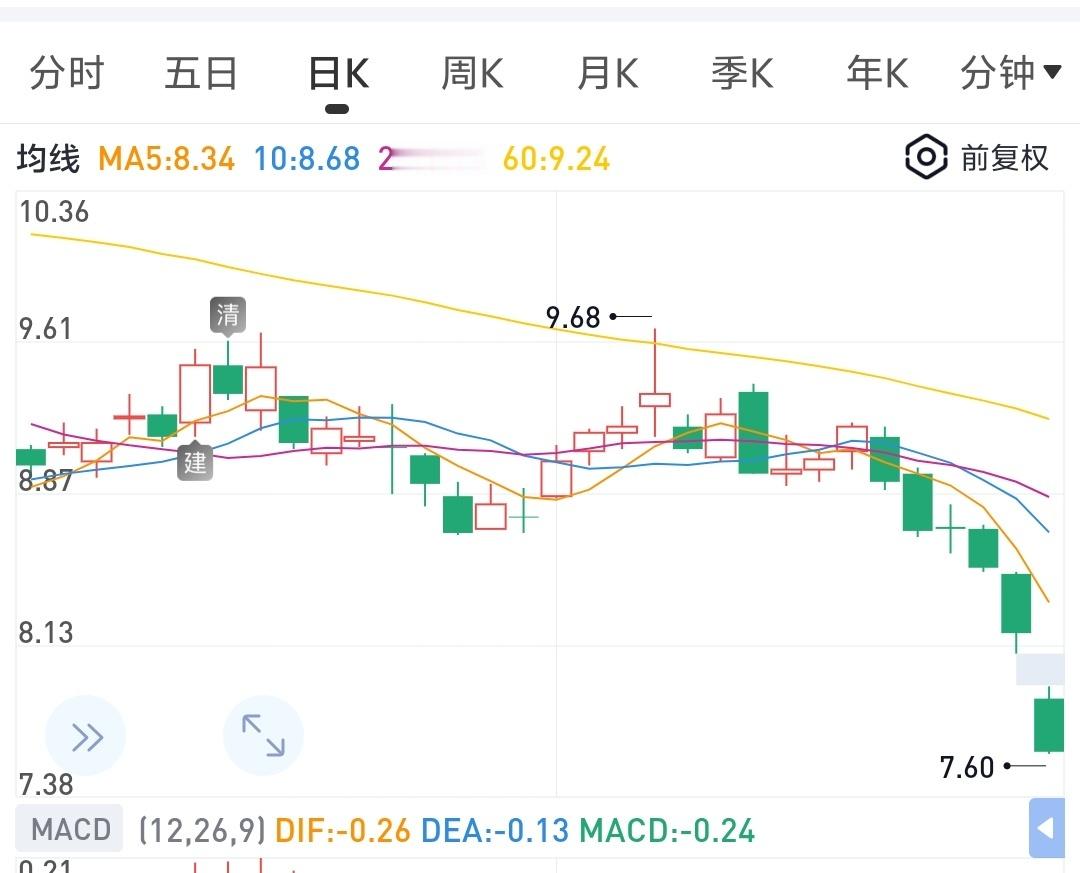
看看美股的存储,在看看A股的存储,都不知道在那咋呼啥呢。
2026-05-26 23:49
看看美股的存储,在看看A股的存储,都不知道在那咋呼啥呢。
AI的需求是真实的,股价高到难以理解是很客观的,但不要把这两件事混为一潭。AI的
2026-05-26 19:49
AI的需求是真实的,股价高到难以理解是很客观的,但不要把这两件事混为一潭。AI的
在四千点之上,很多人开始亏去年的利润了。我的建议是,该歇就歇,调整下状态,账户一
2026-05-26 14:51
在四千点之上,很多人开始亏去年的利润了。我的建议是,该歇就歇,调整下状态,账户一
第一页
下一页
作者信息
孤鸿泽
感谢大家的关注
分类: 财经
热门分类
推荐
热榜
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
房产
家居
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点
中国军情
武器
中国南海
中国足球
亚洲杯
科比
综合体育
CBA
投资
楼市
大咖秀
外汇
创业
风口
SUV
豪车
概念车
优惠
新能源
美国
欧洲
朝日韩
俄罗斯
孕期
街拍
恋爱攻略
婚姻
正能量