一个让所有大语言模型都拿0分的评测:ProgramBench。(官网:programbench.com/ )
这个评测用来评估语言模型是否能“从零开始重建软件项目”的新基准。它关注的是模型能否像软件工程师一样理解一个程序的外部行为、做出整体设计决策,并搭建出一个功能相近的完整项目。
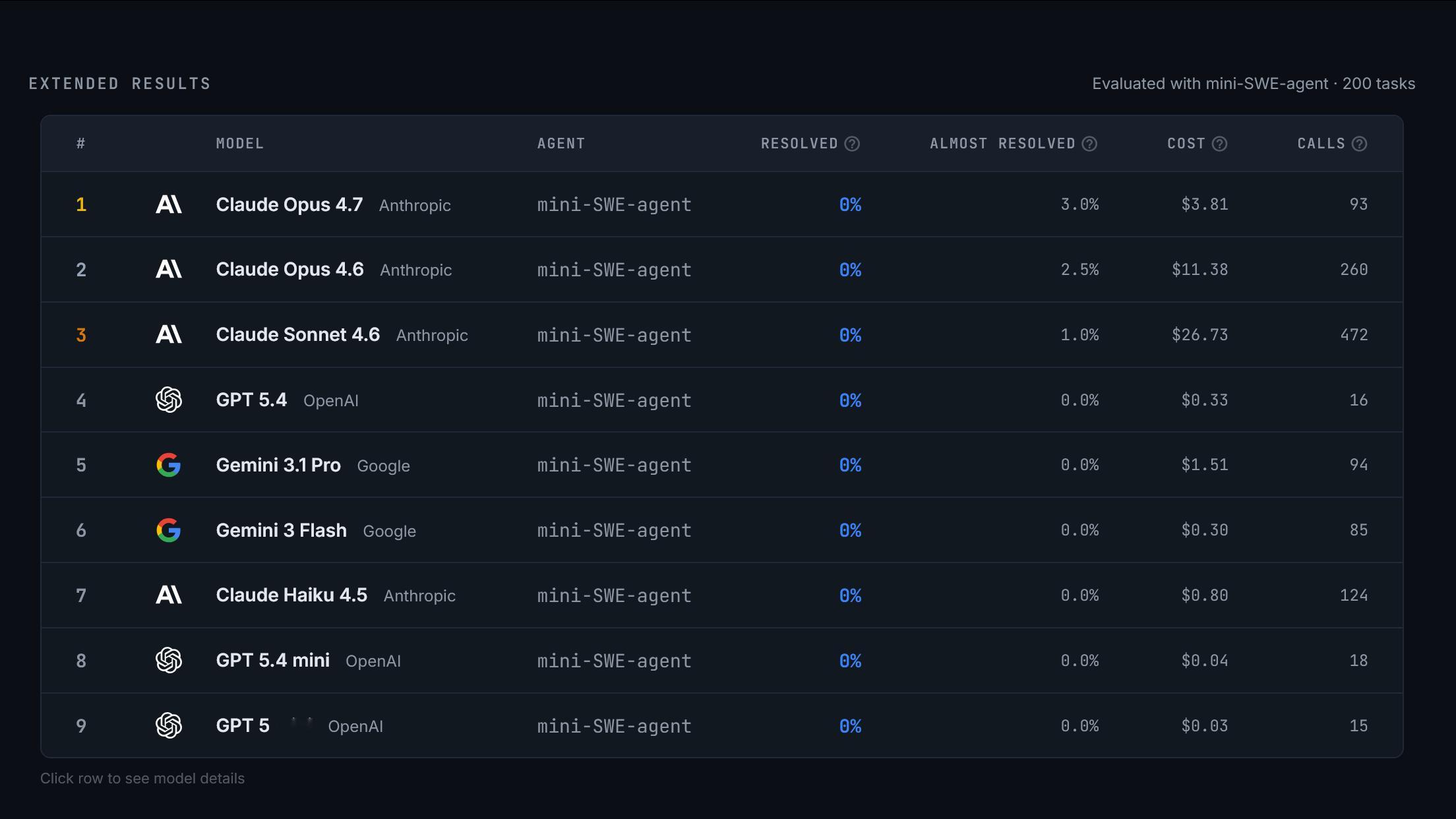
“在 ProgramBench 中,智能体只会获得一个程序及其文档,并必须设计和实现一个代码库,使其行为与参考可执行文件相匹配。端到端的行为测试通过智能体驱动的模糊测试生成,因此可以在不规定具体实现结构的情况下进行评估。我们的 200 个任务涵盖了从小型命令行工具,到 FFmpeg、SQLite 和 PHP 解释器等广泛使用的软件。
我们评估了 9 个语言模型,发现没有任何模型能够完全解决任意一个任务;表现最好的模型也只在 3% 的任务上通过了 95% 的测试。模型倾向于生成单体式、单文件的实现方式,这与人类编写的代码存在显著差异。”AI创造营