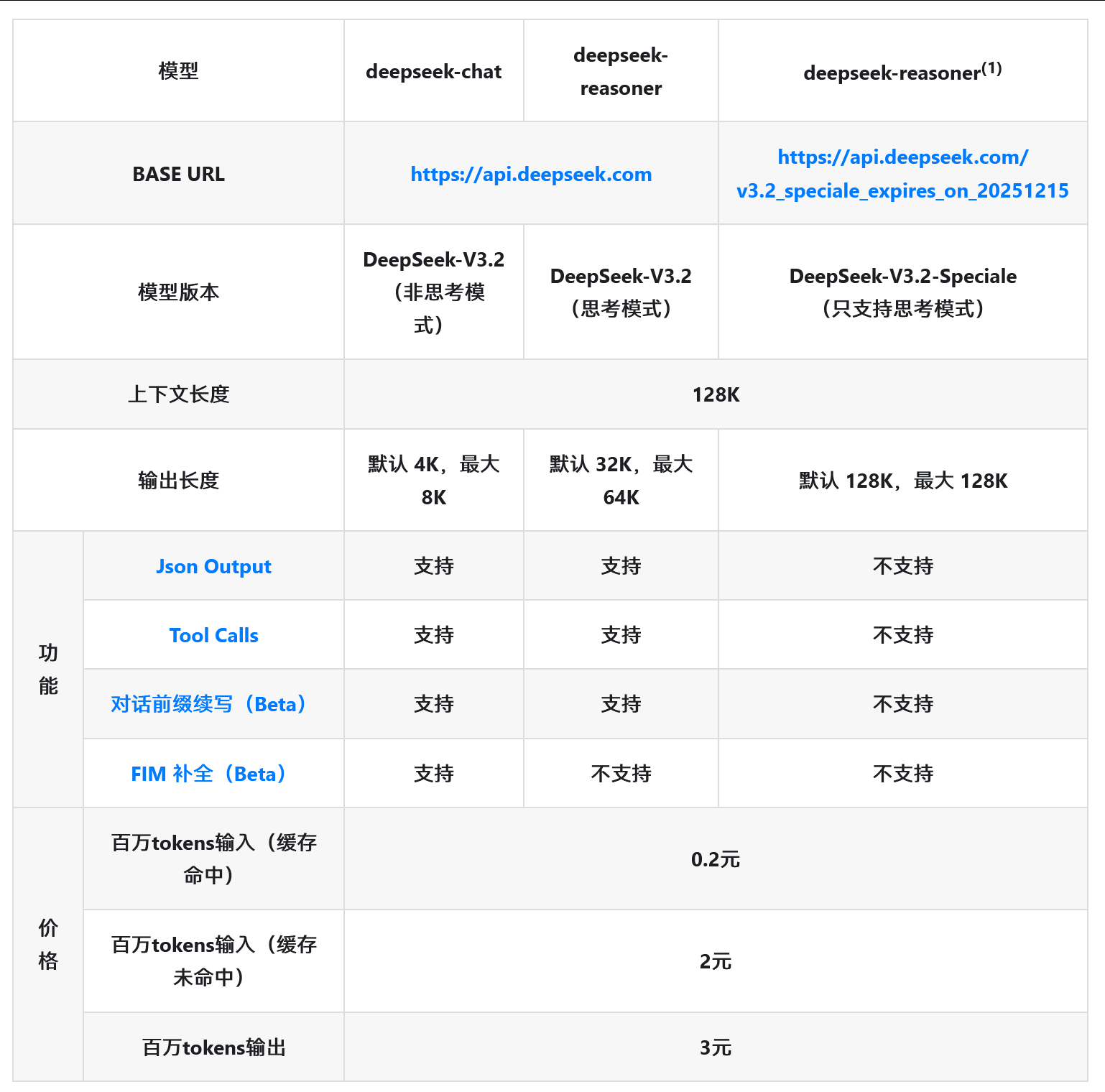
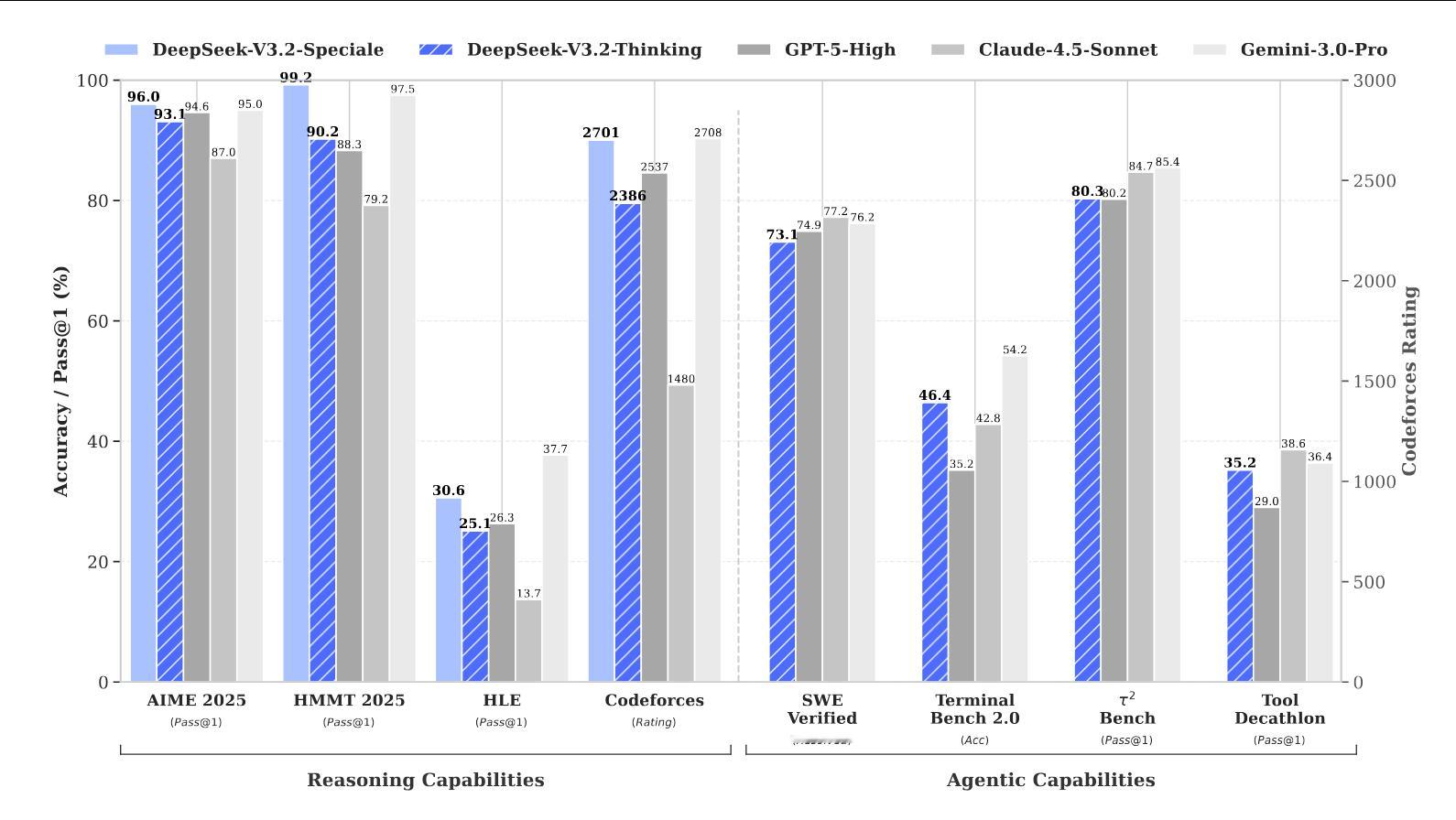
DeepSeek刚发了两个新模型!DeepSeek同时发布2款新模型 DeepSeek-V3.2 是该系列中兼顾高性能与部署成本的旗舰全能模型。它继承了 DeepSeek-V3.2-Exp 验证过的架构,也就是 DeepSeek Sparse Attention (DSA) 机制,在保持长上下文处理能力的同时显著降低了计算复杂度 。该模型采用“混合强化学习(Mixed RL)”策略,将推理、智能体和人类对齐任务统一训练,并利用大规模合成的智能体任务数据(Synthetic Agentic Tasks)极大增强了工具使用能力 。它优化了“工具调用中的思考(Thinking in Tool-Use)”机制,避免了像 DeepSeek-R1 那样在每轮交互中丢弃推理上下文的低效问题,从而在拥有比肩 GPT-5-High 综合性能的同时,实现了更优的 Token 效率 。DeepSeek-V3.2-Speciale 则是为了探索开源模型智能上限而打造的高算力推理专用版。与标准版不同,它在强化学习阶段仅使用推理数据,并专门集成了 DeepSeek-Math-V2 的高难度数学证明数据集与奖励机制,以此强化复杂逻辑处理能力 。为了换取极致的准确率,该模型放宽了生成长度限制(Length Constraints),允许模型进行极长思维链的“扩展思考” 。这一策略使其在 2025 年的 IMO(数学奥赛)和 IOI(信息学奥赛)中均斩获金牌表现,成功超越 GPT-5 并在推理能力上与目前最强的闭源模型 Gemini-3.0-Pro 分庭抗礼 。科技先锋官