在目前的硬件圈子里面,有一个趋势已经变得越来越明显:AI正在从云端往我们手边落下来。随着英伟达GB10 Grace Blackwell芯片的落地,桌面级设备开始真正具备跑通大模型的能力。在最近一段时间里,技嘉AI TOP ATOM这台机器被拿来做了几轮测试,也实际用它做了一些开发工作,这里可以具体聊一聊它的实际表现。

先明确一个观点:它的核心目标只有一个,就是让开发者能在本地流畅地运行大语言模型,不需要折腾环境配置,也不用受限于显存容量。把机器从包装里拎出来的那一刻,确实很让人意外。150毫米的立方体,比预想中要小一整圈,高度还不到一瓶常规可乐。银灰色金属外壳,表面处理得挺细腻,没有任何一条RGB灯带,也没有那种张牙舞爪的散热开孔。把它往显示器底座旁边一放,视线扫过去几乎注意不到多了个东西。整机功耗控制在140W左右,配的是240W的电源适配器,运行起来非常安静,哪怕连续跑模型,风扇也只是维持在一个稳定的低噪状态。

但真正让它和普通PC拉开差距的,是内部的硬件架构。GB10芯片通过NVLink-C2C技术把CPU和GPU整合在一起,双向带宽达到传统PCIe 5.0的五倍左右。这意味着CPU和GPU之间不再需要通过PCIe通道来回搬运数据,而是可以直接共享同一块内存空间。这台机器配备了128GB的统一内存,没有“显存”和“内存”之分,Blackwell GPU需要多少资源,就从这片池子里取多少。消费级显卡哪怕核心算力再强,一旦上到70B或者百亿级别的参数,就必须做量化或者模型切分,甚至直接放弃本地推理。而在AI TOP ATOM上,这个问题被绕开了。

实测跑了GLM-4.5-Air,一个106B参数规模的模型,在NVFP4精度下显存占用稳定在69GB左右,推理过程非常流畅。生成速度维持在每秒20个token以上,这个吞吐量对于调试代码、验证想法、做本地推理来说,已经完全够用。如果你愿意,甚至可以同时拉起多个实例,几个团队成员一起接入,各自跑自己的任务,互不干扰。Blackwell架构针对低精度计算做了专门优化,FP4精度下能释放出高达1000 TOPS的算力,这意味着在一些特定任务上,这台小机器可以跑出接近数据中心级设备的效率。
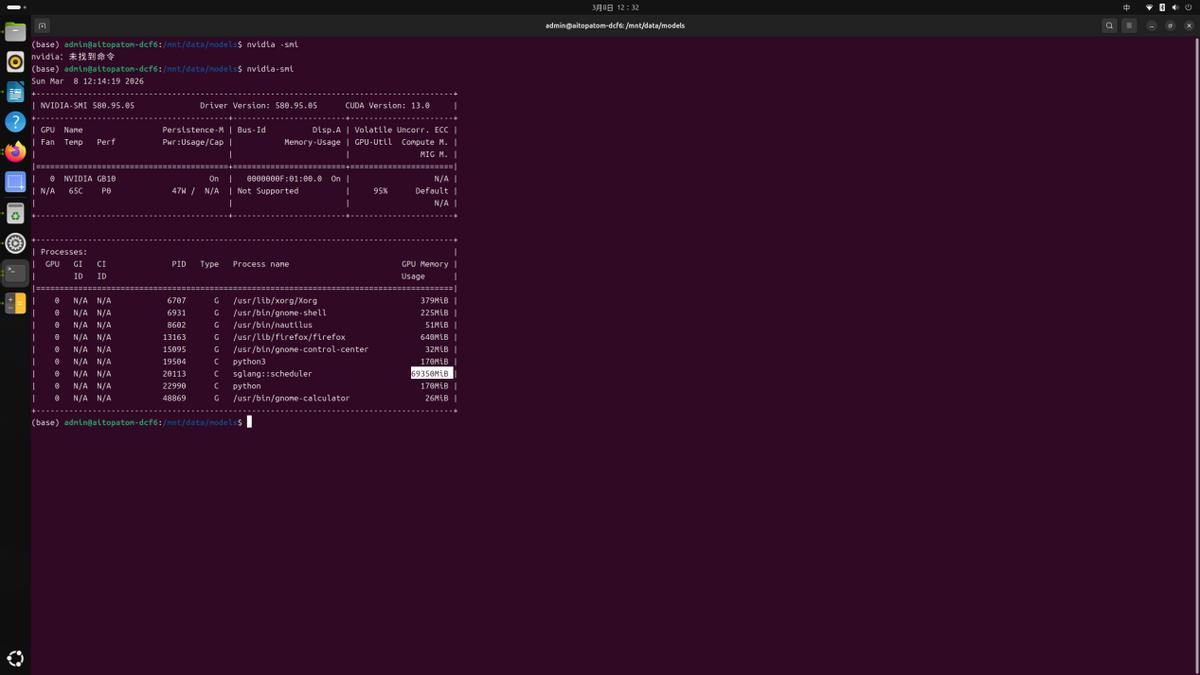
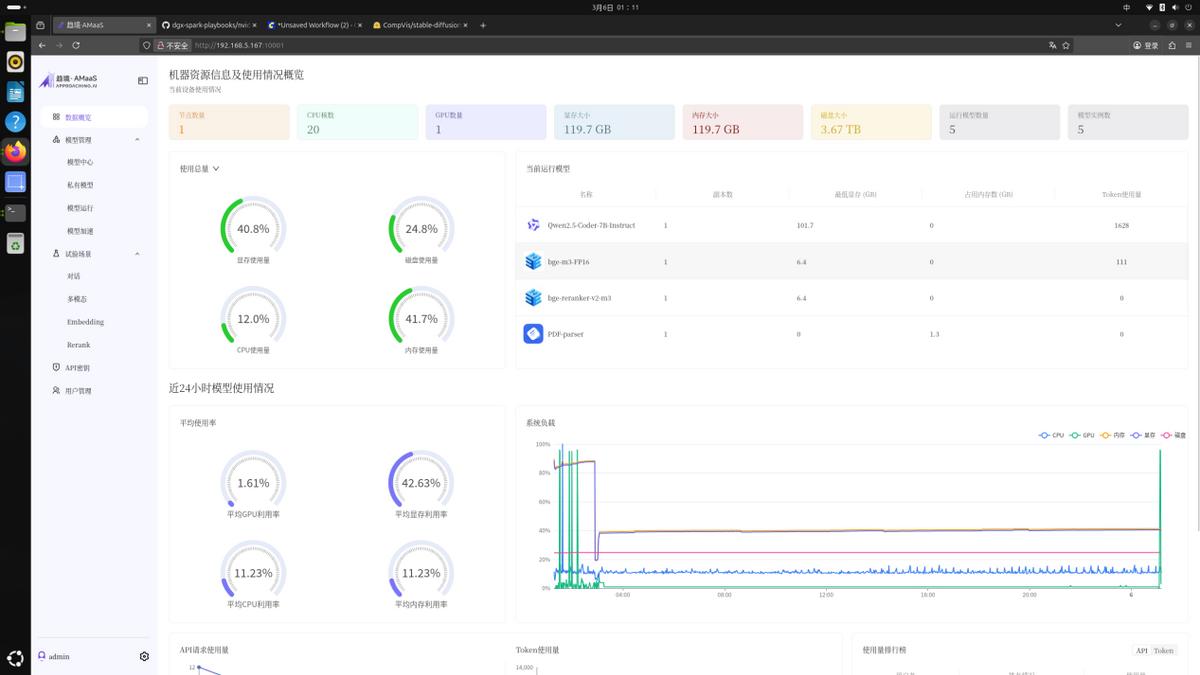
硬件只是基础,真正让我觉得它可以成为生产力工具的,是软件层面的整合。机器预装了趋境智问系统平台,开机之后不需要敲任何一行Linux命令,直接在浏览器里输入IP加端口号,就能进入一个图形化的AI工作台。后台界面做得非常干净,趋境AMaaS管理平台把GPU负载、显存占用、token消耗这些关键指标全都可视化,谁在跑模型、吃了多少资源、有没有爆显存,一眼就能看清。对于小型团队或者实验室来说,这个后台不仅能监控资源,还能管理多个模型实例,避免互相抢占。
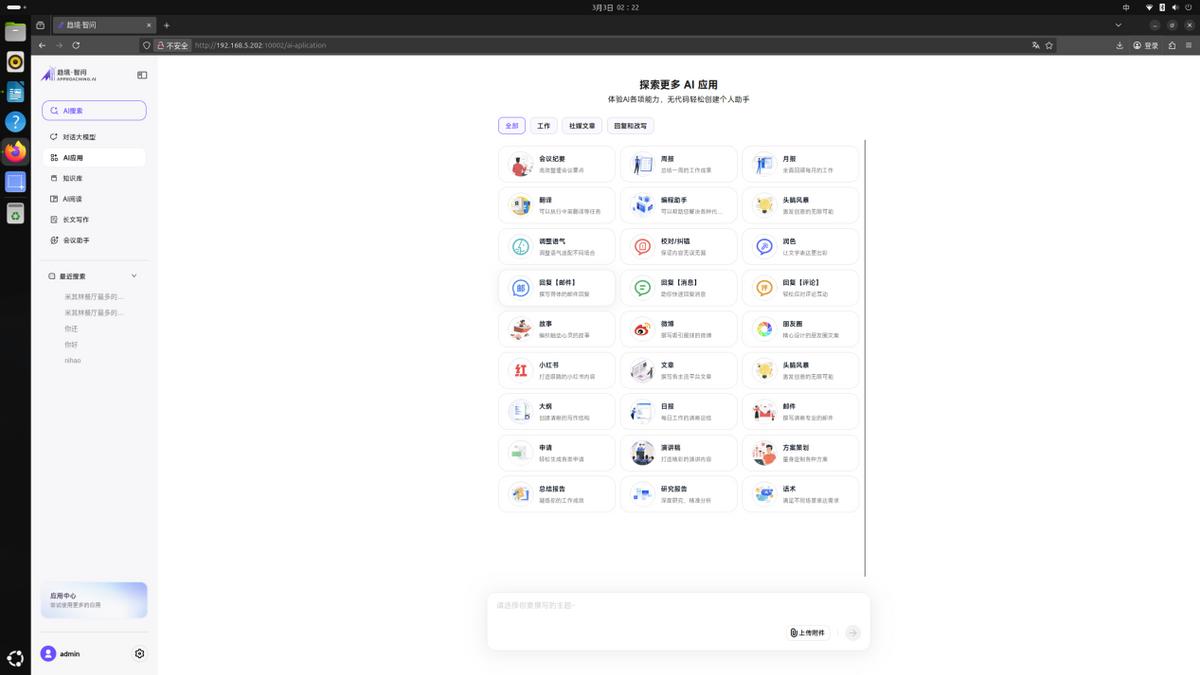
如果是纯粹的应用层用户,不想关心底层调度,只想让AI帮忙干活,趋境智问平台也提供了完整的工具链。它不是一个简单的对话框,而是一套覆盖文档处理、写作辅助、会议纪要生成、本地知识库问答的办公套件。上传一份技术文档,它能快速提炼摘要;把会议录音丢进去,它能自动整理出行动项。这些功能虽然听起来不复杂,但全部跑在本地,数据不出内网,对于有隐私保护需求的团队来说,价值非常明显。
扩展性方面,技嘉也没有因为体积小而妥协。机身背部留了一个NVIDIA ConnectX-7接口,这是DGX SPARK同款的互联方案。如果你有两台AI TOP ATOM,可以直接通过这个接口把它们连起来,实现算力和显存的池化。对于需要跑4000亿参数以上超大模型的极客用户来说,这种拼接方式比一次性投入买大型服务器要灵活得多,可以根据项目需求逐步堆叠,乐高式的升级路径。

这台机器不是用来对标数据中心里几千核的GPU集群的,它的定位非常清晰:在桌面级的功耗和体积限制下,给开发者提供一个能跑通大模型的本地环境。它把AI算力的门槛从专业团队拉低到了个人开发者层面,不需要学全套运维知识,不需要租昂贵的专属服务器,插上电,打开浏览器,就能动手实践。如果你一直在等一台不用折腾环境、不用抢云端资源、能安安静静放在桌面上跑大模型的设备,技嘉AI TOP ATOM确实值得放进备选清单。