
过去两年,大语言模型在推理能力上的进展令人瞩目。
从数学与代码生成,到复杂逻辑与科学问题求解,模型不断刷新 benchmark 记录。随着 “推理模型”(reasoning models)概念的兴起,越来越多的研究将推理能力视为通向通用智能的关键标志。
然而,在能力快速提升的同时,一个更为基础的问题逐渐浮出水面:当模型在推理任务中出错时,这些错误究竟是偶然的波动,还是揭示出更深层次的结构性缺陷?
近期发表于 TMLR 的论文《Large Language Model Reasoning Failures》对这一问题进行了系统性梳理。该研究并未围绕 “模型是否真正理解” 展开哲学层面的争论,而是采取更加务实的路径 —— 通过整理现有文献中的失败现象,构建统一框架,系统分析大语言模型的推理短板。
 论文标题:Large Language Model Reasoning Failures
论文链接:https://arxiv.org/abs/2602.06176
论文标题:Large Language Model Reasoning Failures
论文链接:https://arxiv.org/abs/2602.06176 在当前以性能为导向的研究环境中,这样的工作显得尤为必要。
该论文的作者 宋沛洋 是加州理工学院计算机专业本科生,本工作为他在斯坦福大学人工智能实验室(Stanford AI Lab, SAIL)访问时所进行的研究;韩芃睿 是伊利诺伊大学香槟分校(UIUC)计算机系研究生,该工作为他在本科时所做;指导老师 Noah Goodman 是斯坦福大学计算机系和心理学系的正教授。
从 “性能提升” 到 “失败结构”
近年来,大模型研究的主旋律几乎始终围绕性能提升展开。规模扩展、提示工程、思维链、强化学习对齐等方法持续推动模型在标准基准上的成绩上涨。
相比之下,对失败模式的系统分析却长期处于碎片化状态。逻辑推理中的不一致、数学结构泛化困难、社会情境下的不稳定表现、物理推理中的常识缺失,这些问题分散在不同领域的研究之中,缺乏统一视角。
该论文的核心贡献,正是在于将这些看似零散的现象组织进一个系统化框架之中,从而揭示它们之间潜在的共性。
研究提出了一个二维分类结构。一条轴线刻画 “推理类型”,另一条轴线刻画 “失败性质”。通过这一结构,不同领域中的问题得以在同一坐标系下被理解与比较。
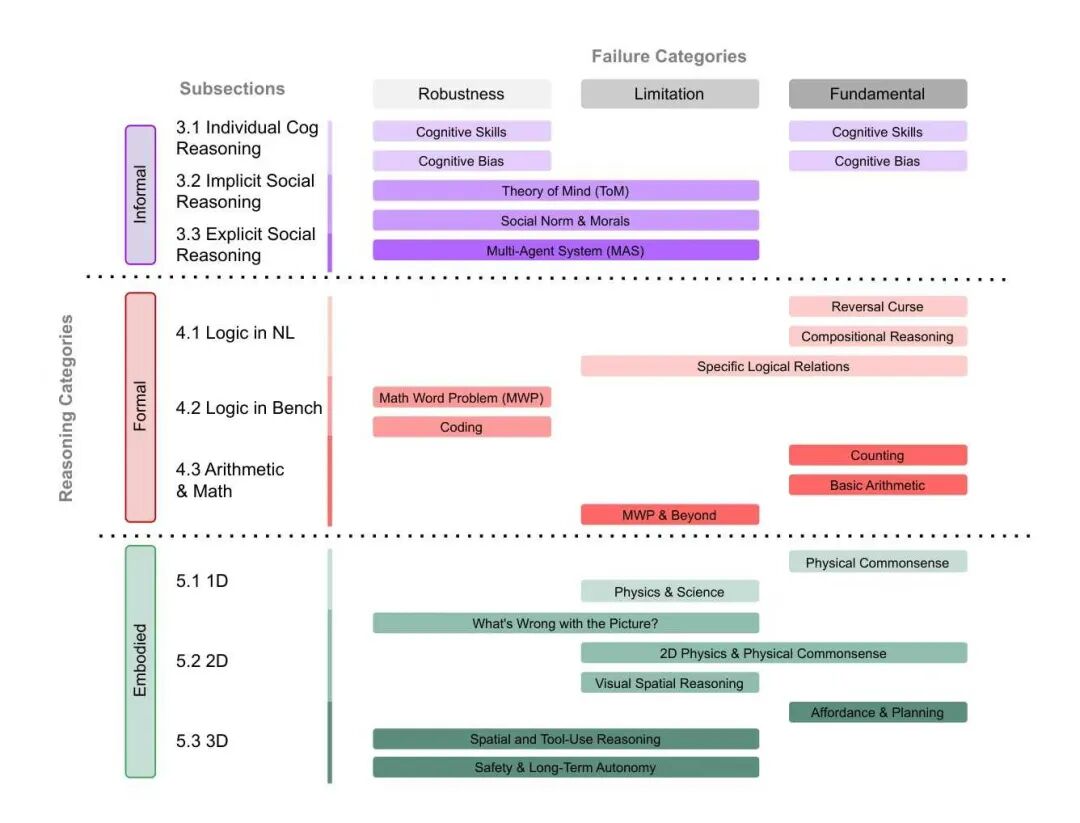
三类推理:从语言逻辑到具身环境
在推理类型维度上,论文区分了三种主要形式。
第一类是非具身的非正式推理,涵盖直觉判断、认知偏差以及社会语境中的推断能力。这类能力在人类认知发展中属于基础结构,但在大语言模型中往往呈现出高度不稳定性。
第二类是非具身的形式化推理,包括自然语言逻辑推断、组合推理、算术与数学问题求解以及代码生成等任务。这是当前推理模型竞争最为激烈的领域,同时也是结构性失败频繁暴露的区域。
第三类则是具身推理,涉及物理常识、空间关系理解、工具使用以及在真实或模拟环境中的行动规划。当模型从文本世界进入具身环境,这类问题变得更加突出。
这一分类并非简单罗列任务,而是试图揭示不同推理场景之间的认知结构差异。
三类失败:结构性、领域性与鲁棒性问题
在失败性质维度上,研究将现有文献中的问题归纳为三类。
第一类是根本性失败。这类问题通常源于模型架构或训练目标本身,具有跨任务的普遍性。它们往往在不同推理场景中反复出现,难以通过简单的数据扩充或规模提升彻底消除。
第二类是应用特定限制。模型在某些特定领域或任务中表现出明显短板,即便在其他领域已有显著进展。这类问题通常与任务结构、领域知识或推理深度相关。
第三类是鲁棒性问题。在语义保持不变的情况下,任务形式的轻微扰动即可导致模型输出出现显著波动。这种现象在标准 benchmark 评测中尤为常见,也在社会推理与多智能体协作情境中频繁出现。
通过这一分类可以看到,不同领域中的失败现象并非彼此孤立。许多根本性问题会跨越推理类型反复出现,而鲁棒性问题则揭示出模型内部推理结构的不稳定性。
结构性共性:从训练目标到内部机制
论文进一步指出,多个失败现象可以追溯到相似的结构根源。
自回归训练目标使模型更倾向于进行局部的模式补全,而非全局结构建模。这种偏置在形式化逻辑推理与长程规划任务中尤为明显。注意力机制在复杂任务中的分散效应,也可能导致组合结构整合能力不足。
在具身推理场景中,由于模型缺乏真实世界的感知与反馈闭环,其内部表示难以形成稳定的物理因果模型。这种缺失并不会在纯文本 benchmark 中立即显现,但在动态环境中会被放大。
值得注意的是,随着模型规模扩大,部分能力确实得到显著提升,但某些结构性问题并未同步消失。这一观察提示,仅依赖规模扩展,或许不足以解决所有推理缺陷。
走向成熟阶段的必经之路
论文发布后,很快在海外社交平台引发热议。
在 X(原 Twitter)上,有评论直言这是“近年来最令人不安的一篇 LLM 推理论文”。所谓“不安”,并非因为提出了夸张的结论,而恰恰相反——它并未展示新的 SOTA 模型,也未公布新的 leaderboard 成绩,而是系统梳理了大语言模型在推理方面反复出现的失败模式。
当社区沉浸在性能跃升的叙事之中,这种对结构性缺陷的全面回顾,无疑具有某种冷静甚至反思的意味。
回顾计算机系统发展的历史可以发现,系统性能提升的同时,对故障结构的分析始终是成熟阶段的重要标志。早期计算机工程依赖 fault tolerance 研究不断改进架构设计,安全关键行业则通过事故复盘建立可靠机制。
在大语言模型迈向推理模型时代的背景下,对失败模式进行系统整理,同样具有基础性意义。
论文指出,未来的研究应更加重视失败基准的长期更新与跨模型比较机制。与其仅关注单点性能提升,不如建立能够追踪顽固失败模式的评测体系,从而观察哪些问题在模型代际迭代中持续存在。
同时,推理评估也需要逐步从静态分数导向,转向结构稳定性与行为一致性的综合衡量。只有当具体的推理崩溃现象能够被追溯至内部机制层面,改进路径才会更加明确。
理解失败,才能构建可靠推理系统
大语言模型的推理能力仍在快速进化之中。但一个成熟的推理系统,不应仅在理想条件下取得高分,更应在复杂环境中保持结构稳定,并在失败时具有可预测性与可解释性。
《Large Language Model Reasoning Failures》所做的,正是为这一方向提供基础框架。
在能力竞赛之外,系统理解失败,或许将成为下一阶段人工智能研究的关键课题。