
大模型正在从“比拼智商”,变成一门“进厂打螺丝”的生意。
据财联社报道,OpenRouter最新周度数据显示,平台前十模型总token量约8.7万亿,中国模型独占5.3万亿,占比61%。
而当周token调用量前三模型均为国产大模型,分别为Minimax M2.5、Kimi K2.5、GLM-5,调用量环比上周分别变动增加197%、下降20%、增加158%。
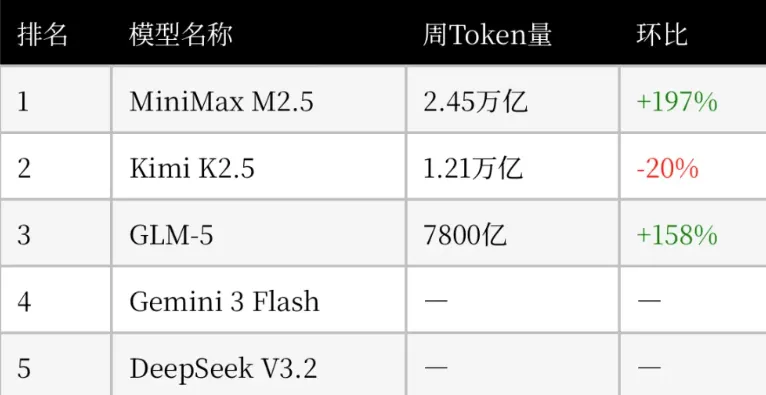
其中,MiniMax M2.5以2.45万亿token空降榜首,Kimi K2.5以1.21万亿紧随其后,智谱GLM 5和DeepSeek V3.2分列第三、第五。
要知道,作为全球最大的大模型API聚合平台,OpenRouter汇聚了全球开发者的真实调用需求,它的榜单堪称目前AI行业最硬核的“算力消耗晴雨表”。
看到国产大模型如此疯狂地“屠榜”,很多人的第一反应肯定是:难道在绝对能力上,国内大模型已经赶上GPT、Claude和Gemini了吗?
答案显然是否定的。如果真要死磕极度复杂的逻辑推理或硬核的代码工程,硅谷这几家闭源巨头依然是当下绝对的技术天花板。
那么,既然绝对智力并没有赶上北美顶尖模型,那为什么偏偏是国内大模型跑满了全网的调用量?对未来的AI竞争格局又意味着什么?
01大模型不是炼金术而是流水线国内大模型企业,正在用义乌做小商品的逻辑,降维狙击硅谷的赛博魔法。之所以中国大模型能够在Openrouter上“屠榜”,唯“便宜”尔。
过去,大模型的定价权在海外巨头手中。以GPT-4o或Claude 3.5 Opus为例,能力强,但价格也高。处理百万Token的数据,通常需要花费几美元甚至十几美元。
在AI爆发的尝鲜期,这个价格大家咬咬牙也就接受了。可一旦迈入Agent时代,情况彻底变了。
最近在科技圈闹得沸沸扬扬的“OpenClaw封禁事件”,就是这场算力成本危机的最直观切面。
作为一款爆火的开源AI智能体,OpenClaw能像“数字打工人”一样接管电脑、全自动处理文件甚至写代码。为了省钱,许多极客和开发者想出了一个“绝妙”的方案:他们利用代码接口,让OpenClaw去“白嫖”谷歌和Anthropic每月20美元的个人包月订阅服务(如Claude Pro),而不是老老实实去调用官方按量付费的昂贵API。
结果可想而知,当AI从“你问我答的聊天框”变成“自动规划、反复执行的数字打工人”时,它在后台每一次的搜索、试错、纠错和循环,都在疯狂燃烧Token。这种Agent级别的恐怖吞吐量,直接把原本号称“不限量”的包月服务给刷爆了。
面对被“薅秃”的算力资源,谷歌和Anthropic也坐不住了。他们不仅紧急下场,严禁第三方工具接入订阅制通道,谷歌甚至对部分高频调用的账号祭出了“永久封禁”的终极杀招。
巨头们这番“掀桌子”操作的核心逻辑其实只有一个:算力成本实在扛不住了。
在Agent时代,如果继续放任大家用20美元的包月订阅跑自动化任务,CSP巨头也一定会破产;但如果逼着开发者去走官方API,按照每百万Token十几美元的价格计费,那么最先进的高价大模型就不再是先进生产力,而是成了一个吞噬利润的无底洞,直接把无数AI应用和开发者的商业模式逼到了死角。
正是在大多数行业都陷入“用不起算力”的死局时,他们回头一看,发现大洋对岸的中国大模型企业,已经把价格卷到了一个令人发指的地步。
目前,像DeepSeek、GLM、Kimi或者是MiniMax等国产优秀大模型,其API的调用价格已经被硬生生打到了每百万Token只需要两到三美元。
而有些厂商为了抢占开发者生态,更是对百万级上下文或特定规模的模型实行长期的免费开放。这已经不是“打个八折”的促销,而是数量级的成本断层。
很多人可能会问:便宜固然好,但如果模型不够聪明,便宜又有什么用?但事实却是,绝大多数人高估了真实场景对“极限智商”的需求,却低估了“长尾任务”对算力吞吐量的恐怖消耗。
在真实的商业世界和极客开发圈里,90%的AI任务根本不需要用到“爱因斯坦级别”的智商。
想象一下我们日常使用AI的场景:把一本十万字的英文网络小说翻译成中文;丢给AI几十个PDF财报让它提取出所有的利润数据;写一段几百行的前端基础代码;又或者是目前OpenRouter上消耗量极大的“角色扮演”——玩家和AI扮演的虚拟角色进行几千轮的闲聊。
这些任务有一个共同特点:逻辑深度一般,但文本吞吐量巨大。对于这类“蓝领型”的认知工作,排名前列的中国模型已经不仅是“及格”,而是做得非常出色。
这就好比你要给公司几万份快递单号录入表格,你完全没有必要去花重金聘请一位诺贝尔奖得主(顶尖闭源模型),你只需要雇佣一批勤奋、踏实且工资极低的实习生(高性价比模型)就能完美解决。
更何况顶尖闭源模型与高性价比模型之间的差距,在蒸馏技术的存在下,两者的差距最多只有半个身位。
因此,全球的开发者们极其理智地选择了“智能路由”策略:把海量的、繁琐的、容错率高的基础任务和长文本阅读,全部路由给便宜的中国模型;只有到了需要做最终的复杂逻辑判断,或者碰到了极难的算法题时,才会精打细算地调用GPT或Claude。
这,才是国内大模型能跑满全网调用量的原因。
02算力争霸战,变压器才是底牌
便宜的大模型,从来都不是天上掉下来的馅饼。
很多人误以为,国内大模型的白菜价是靠着国内厂商“烧钱补贴”砸出来的。但这其实低估了中国工程师在技术落地上的恐怖压榨力。
当硅谷还在迷信“大力出奇迹”、疯狂堆叠万亿参数时,国内大模型企业早就在“抠门”这门艺术上做到了登峰造极。
在这个赛道上,中国厂商展现出了极其恐怖的制造业基因和工程化压榨能力。
众所周知,受制于相关禁令,国内大模型企业往往无法像硅谷巨头那样,轻松买入数以十万计的最顶尖GPU。在“算力贫穷”的逼迫下,国内工程师们别无选择,只能硬生生地在工程优化的泥沼里进行极限微操。
为了降低单次推理的算力消耗,他们把MoE玩到了极致。
一个拥有上千亿参数的庞大模型,在回答一个简单的日常问题时,系统会精准地只激活其中几十亿参数的“专家网络”,让剩下的大部分网络保持休眠。这就好比一个巨大的工厂,不再是为了生产一颗螺丝钉而让所有车间灯火通明,而是精准控制产线,极大地节省了算力和电力消耗。
为了应对百万级超长上下文带来的显存问题,中国工程师们在底层框架上死磕,对KV Cache进行像素级的压缩和优化,把庞大的数据极其严密地打包塞进有限的显存里,硬是在相对劣势的硬件上,跑出了比肩甚至超越世界前列的超长文本处理能力。
这种对底层算力近乎变态的压榨,加上国内极其成熟的硬件适配工程,硬生生把大模型推理的物理成本砍掉了几个数量级。
相比之下,大洋彼岸的北美巨头们就算想打价格战,也是心有余而力不足,因为他们已经被沉重的物理基建彻底锁死了。
在这个问题上,马斯克早在2023年就给出了预言:“我的预测是,我们将从……今天的硅极度短缺变成……两年内的电力短缺。这大致就是事情的趋势。”
而现实也确实如此,北美老旧的电网系统和漫长的环评审批,根本无法支撑新建超大型数据中心的用电狂飙。昂贵的工业电价、奇高的人力运维成本,甚至有钱都买不到的高压变压器,最终全都化作了高昂的沉没成本,均摊到了每一次的API调用里。
换句话说,北美顶尖大模型的“贵”,有一大半是替落后的基础设施和高昂的本地要素买了单。
于是,当高昂的物理成本遇上全球对算力的无限需求,一个属于中国AI的全新定位诞生了。
过去四十载,我们吃透了人口红利和完善的供应链,成为了向全球输出实体商品的“世界工厂”;而今天,随着大模型进入应用落地的深水区,告别人口红利的中国,正在依托着世界顶级的特高压电网、极其稳定的低价工业电力,以及首屈一指的工程落地能力,转型为新时代的“世界Token工厂”。
至此,未来的全球AI大分工已经非常清晰:那些海量的文档精读、初级代码生成、高并发的长文本翻译和虚拟人闲聊,统统会作为“赛博代工订单”,顺着海底光缆,源源不断地路由给国内大模型集群。
电能一旦在AI芯片中被转化为Token,它就彻底脱离了物理形态的束缚。它不像需要漫长的港口装卸和远洋货轮运输的产品,而是以光速通过海底光缆,在毫秒之间传输到世界的每一个角落。
因此,与其说是全世界的极客跑来“薅”国内大模型的羊毛,不如说是中国正在以绝对的成本与基建优势,悄然接管AI应用时代的底层命脉。
当硅谷巨头们还在为摘取AGI的终极王冠不计代价地烧钱、深陷物理基建的泥沼时,国内大模型企业已经化身为新时代的“基建狂魔”,用这源源不断、跨越山海的廉价Token,稳稳当当地做起了全球智能革命最不可或缺的“水电煤”生意。