这些年,我参与过好几次把公司数据从一个地方搬到另一个地方的项目。说实话,每次接到这种任务,心里都挺有压力的。数据就像公司的“家当”,搬的时候要是丢了一件或者弄坏了,那可不是小事。
我知道,无论是技术同事接到迁移指令,还是业务部门听说要“系统升级”,大家心里都会犯嘀咕:这要弄多久?业务会不会停?搬过去的数据还能用吗?
听着是不是很熟? 这种担心特别正常。今天,我就不讲那些大道理,就想像朋友聊天一样,跟你讲讲数据迁移到底该怎么干,有哪些坑可以提前避开,还有哪些工具能让我们心里更有底。
一、先搞明白:咱们到底要搬什么?
在动手之前,我们得先想清楚一个最基本的问题:数据迁移,搬的到底是什么?
你可能会觉得,不就是把数据从老数据库复制到新数据库吗?这个说法没错,但不够完整。一次完整的数据迁移,其实至少要搬三样东西:
数据本身:就是那些一条条的客户记录、一笔笔的订单信息。这是最核心的。
数据的“架子”和“规矩”:数据库里不光有数据,还有表的结构、每个字段的类型(比如是数字还是文字)、还有索引、主键这些约束。新家的“户型”可能和老房子不一样,这些“架子”得重新搭好,还得适应新环境。
用数据的“方式”:原来那些访问数据库的程序、写的报表、跑的定时任务,它们的连接地址、查询语句可能都得跟着改,不然到了新家就打不开门了。
简单来说,一次迁移是“数据 + 结构 + 应用程序”一起动。 少了哪一样,新系统都可能跑不起来。
那,我们为啥要折腾着搬家呢?
通常是因为下面这几种情况:
系统太老了要换代:比如从MySQL 5.5升级到8.0,或者把昂贵的国外数据库换成国产的。
业务长大了,房子不够住:原来的数据库服务器撑不住了,得搬到更强大的分布式数据库上。
把东西搬到“云上”:从自己机房搬到阿里云、腾讯云这些云服务商那里。
公司业务调整:可能需要把两个系统的数据合并,或者把一个大系统里的部分业务数据拆分出来。
你懂我意思吗? 数据迁移往往不是没事找事,而是业务和技术往前走必须要做的一步。所以咱们不用怕,只要方法对了,就能稳稳当当地完成。
二、怎么搬?记住这个“六步走”的稳妥办法
从我自己的经验来看,想把数据迁移这事儿办稳妥,可以按下面这个“六步走”的框架来。这几步有前后顺序,每一步都挺重要。
第一步:先盘算清楚——别急着动手
这一步最关键,相当于搬家前的“测量和规划”。你需要弄明白几件事:
到底要搬多少东西:是整个数据库全搬,还是只搬最重要的几张表?总共有多少数据(是几十个G还是几个T)?
搬家的时候生意受不受影响:迁移的时候业务系统要不要停?能停多久?有没有大家都休息、业务量最小的时间段(比如深夜或者节假日)?
新房和老房有什么不一样:两个数据库类型一样吗?版本一样吗?里面的字段类型、编码格式、甚至是时间格式有没有细微差别?这些不同点就是后面要重点解决的技术问题。
想好怎么搬:根据上面这些信息,决定是“一次性全部搬完”,还是“先搬旧家具,同时同步新添置的东西”(也就是全量+增量迁移)。如果业务不能停很久,通常就得选第二种。
第二步:画好图纸,准备好工具
规划好了,就开始设计具体怎么操作,并把要用的工具准备好。
画出搬家路线图:把每一步都写清楚。比如:1. 在新数据库里把表结构建好;2. 把过去所有的历史数据搬过去;3. 在搬老数据的同时,把老数据库里还在不断产生的新数据变动也同步过去;4. 暂停业务,把最后一点新数据追平;5. 让所有程序连接到新数据库。
准备好新家:把新的数据库环境准备好,确保它的性能、存储空间、网络都没问题。
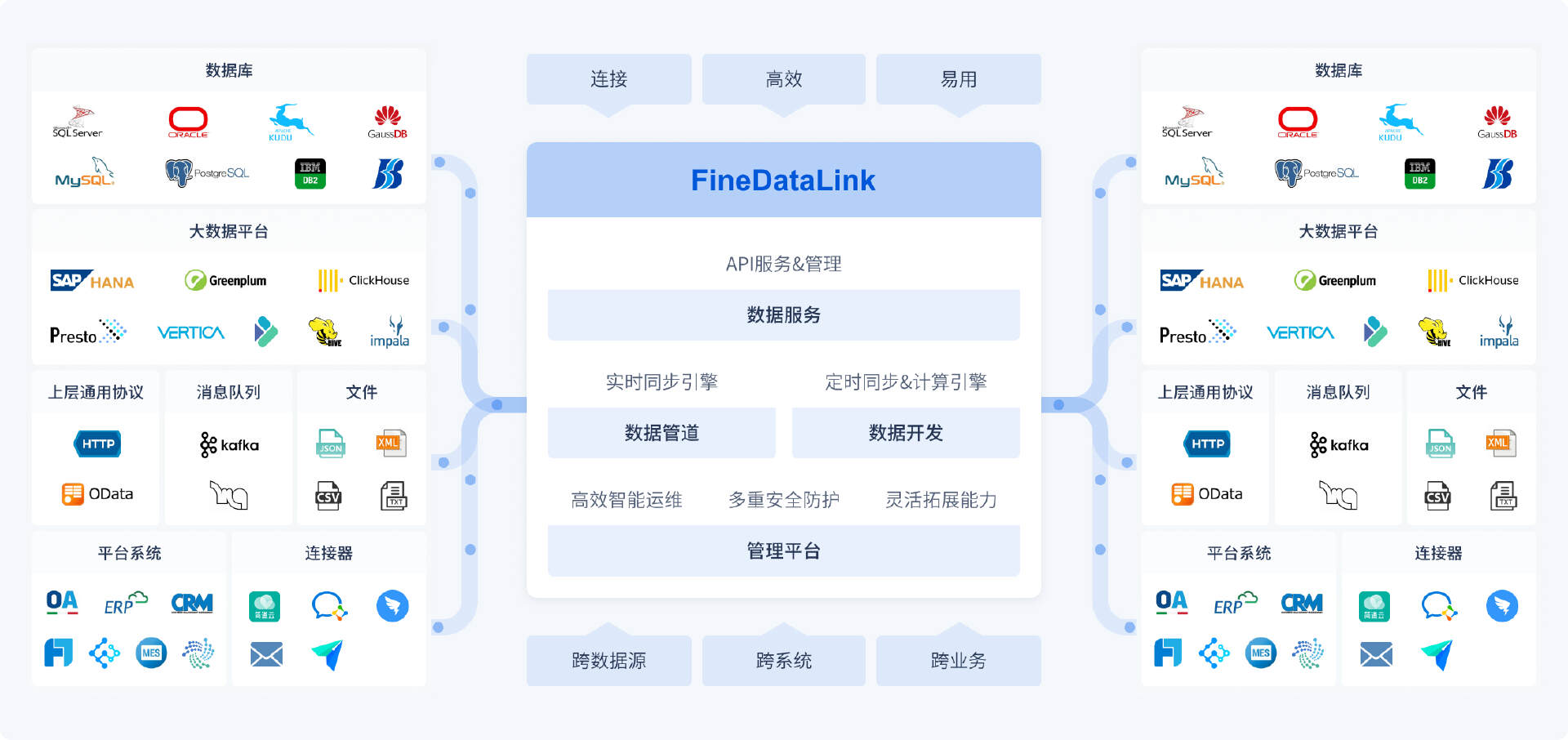
选好搬家工具,并试用一下:这是核心环节。你是用数据库自带的导出导入命令,还是用更专业的第三方工具?用过来人的经验告诉你,如果数据量比较大,或者两个数据库类型不一样,或者你希望业务停的时间越短越好,那么一个专业的数据集成工具会帮上大忙。比如,你可以用 FineDataLink 来设计和执行迁移任务。它不仅能帮你搬历史数据,更重要的是,它可以在你搬家的同时,实时“盯住”老数据库里发生的新变化(比如新增的订单、修改的电话号码),并把这些变化也同步到新家。这个功能能大大缩短最后需要停业务的那段时间。
想好怎么验收:提前想好,搬完家怎么检查东西没丢没坏?是数一下两边记录条数对不对,还是算一下关键数据的总和是不是一样?
第三步:先演习一遍——在安全的环境里试错
千万别直接就在正式系统上操作!一定要搭建一个和真实环境很像的测试环境,完整地走一遍流程。
功能试试看:搬完后,用测试程序连上新数据库,看看基本的查询、新增功能正不正常。
压力测一测:对新数据库模拟一下很多人同时访问的情况,看看它反应快不快,会不会卡。
认真对一对数据:这是测试的重中之重。运行你准备好的比对脚本,仔仔细细地检查测试环境里,老库和新库的数据是不是完全一致。这个过程里,你可能会发现工具配置不对、中文乱码、时间差8小时等等各种问题,正好在正式操作前把它们都解决掉。
演练怎么“撤回”:模拟一下万一搬家失败了,怎么快速把业务切回老数据库。知道有安全的后路,心里才不慌。
第四步:正式行动——按计划精细操作
经过充分测试,就可以安排正式迁移了。一定要选那个业务量最小的时间窗口。
发通知,做准备:提前告诉所有相关部门,什么时候开始切换,可能会有什么影响。
按路线图执行:一步步来。先在新库建好结构,再开始搬历史数据。在搬历史数据的同时,就启动工具的实时同步功能,让它开始捕获和同步老库的新变化。
暂停业务,追平数据:关掉连接老数据库的业务程序。等实时同步工具把老库最后一点变动数据同步完,确保两个库的数据此刻一模一样。
切换连接,快速验证:把业务程序的数据库连接地址改成新库的,然后重启程序。马上做个快速的业务验证,比如登录一下系统、试着下一个测试订单,确保核心流程是通的。
盯紧监控:切换完成后,眼睛盯紧新数据库的各项指标(CPU、内存、连接数)和程序日志,看看有没有报错。

第五步:搬家后观察——保驾护航几天
成功切换不是终点。接下来几天,要有一个“护航期”。
继续密切监控新数据库的运行状态。
收集业务同事的反馈,看看有没有什么之前没想到的边角功能出了问题。
根据实际情况,可能还需要对新数据库做一些优化调整,比如加个索引让查询更快。
第六步:收尾和总结——关好老房子,留下经验
确认新库完全稳定后,就可以收尾了。
安全地关掉老库:确定再也不需要回退了,就可以停掉老数据库的服务(但数据备份建议再保留一段时间)。
更新所有文档:把新的数据库地址、新的架构图更新到所有相关文档里。
开个复盘会:把项目组的同事叫到一起,聊聊这次哪里做得好,哪里踩了坑,把这些经验记下来。这对公司以后做类似的事情,价值巨大。
我一直强调,数据迁移能不能成功,九成取决于前面三步——规划、设计、测试。最后正式切换的那几小时,其实就是把排练过很多遍的戏,稳稳地演出来而已。
三、有哪些好用的搬家工具?
工具选得好,搬家没烦恼。我介绍几类常用的,你可以根据自己的情况选。
1. 数据库自带的工具(简单直接,适合小活儿)
MySQL的 mysqldump:这是最经典的,它把数据变成一堆SQL语句导出来,再导进去。适合数据量不大,可以接受停半天或一天工的情况。优点是简单,谁都会用;缺点是数据量一大就慢。
PostgreSQL的 pg_dump:和上面类似,是PostgreSQL自家的工具。
Oracle的 Data Pump:Oracle数据库的高效搬家工具。

说白了,这类工具像是“万能螺丝刀”,家常小活儿都能应付,但要是遇到特别复杂的搬家(比如跨不同类型的数据库、要几乎不停机),它就有点力不从心了。
2. 专业的数据集成平台(功能全,适合大工程)
这类工具是处理企业级复杂迁移的“专业团队”。它们通常能:
在不同类型的数据库之间搬家:比如从MySQL搬到PostgreSQL。
一次性搞定“搬旧货”和“送新货”:全量迁移和增量同步在一个工具里就能完成。
用图形界面配置任务:操作起来更直观。
在搬家途中顺便整理数据:比如清洗一下脏数据、转换一下格式。
FineDataLink 就属于这类工具。在迁移这个事上,它可以这么帮你:
搬历史数据:快速地把老库的所有数据读取出来,写到新库。
同步新增和变化:用它里面的CDC(变更数据捕获)功能,可以在你搬家的同时,实时“监听”老库。一旦有新的订单进来,或者有客户的电话被修改了,这个变化马上就能被捕捉到,并同步到新库。这样就能实现我之前说的,把最后停业务的时间缩到非常短。
自动处理表结构:它能读取老表的“架子”(表结构),然后自动在新库里创建一个差不多的,很多字段类型都能自动匹配好,省心不少。

3. 云服务商提供的迁移服务(要上云,首选这个)
如果你决定把数据搬到阿里云、腾讯云、亚马逊云这些“云上”,那首先要看看它们自家提供的数据传输服务(DTS)。
好处:和它们自家的云数据库是“亲兄弟”,搭配起来最稳定、兼容性最好;操作界面通常很友好,几步就能配好;很多都有免费的额度可以试用。
最适合:从你自己的机房或者其他云,搬到这个云服务商的数据库里。
4. 开源的同步工具(适合技术团队自己折腾)
Apache SeaTunnel:一个非常活跃的开源数据集成项目,能处理批量和实时同步。
Debezium:它特别擅长像“窃听器”一样,把数据库里每条数据的变化事件抓取出来,发到消息队列里。技术团队可以用它结合其他流处理工具,自己搭建一套灵活的同步管道。这套东西很强大,但要求团队的技术能力比较高。
怎么选呢?
数据不多,结构简单,停半天一天没关系 → 用数据库自带工具。
要在不同类型的数据库间迁移,希望业务停的时间越短越好 → 重点看看像 FineDataLink 这样的专业数据集成平台。
已经决定搬到某个特定的云(比如阿里云)→ 优先用那个云的 DTS服务。
你们技术团队很强,喜欢自己掌控一切 → 可以去研究 SeaTunnel、Debezium 这些开源方案。
最后想说的:保持敬畏,充分准备
数据迁移,说到底是个需要极度细心和周密计划的工程活儿。它最怕的就是“想当然”和“碰运气”。
用过来人的经验告诉你,前期把困难想得足一点,把方案准备得多一点,把测试做得彻底一点。选择一个能cover住你核心需求的、靠谱的工具,真的能让整个过程的焦虑感下降一大截。当你在深夜的切换窗口,看着数据一条条平稳地流动,所有验证都顺利通过的时候,你就会觉得,之前所有的精心准备,都值了。
这个过程,不仅是技术的升级,更是对整个团队协作和风险应对能力的一次大考。祝你的下一次迁移,一切顺利。
Q&A常见问答
Q1:我们最怕业务停太久,怎么才能让停机时间最短?
A: 这几乎是所有人的核心诉求。关键就是用 “全量搬家 + 实时追增量” 这套组合拳。
提前搬走所有旧家具:在业务完全不受影响的时候,先把历史上所有的数据搬到新库。
同时,派个快递员随时送新东西:在搬老数据的同时,就启动工具的实时同步功能(比如 FineDataLink 的CDC),让它时刻盯着老库,一有数据变动(新订单、修改信息),就立刻把这个“变化”同步到新库。这样新库就一直在“追”老库。
最后只停一小会儿,做最终交接:到了正式切换的深夜,只需要短暂地停一下业务(可能就几分钟),等那个“快递员”把最后几秒产生的“变化”送过去,让两边数据完全一致,然后切换程序连接就行了。 这个办法能把停机时间从几个小时甚至一天,缩短到喝杯咖啡的功夫。
Q2:怎么才能确保搬过去的数据百分百没错?万一有差错怎么办?
A: “百分百”是我们的目标,但得靠方法去无限接近。
一定要对比验证,不能光靠相信:除了核对两边的记录总数是不是一样,一定要核对核心数据的总和是不是一致(比如把所有订单金额分别加起来对比)。最好还能随机抽一些具体的记录,逐条字段对比。
分阶段验证:全量数据搬完,验证一次;实时同步过程中,定期验证一下;最终切换前,再做一次终极验证。
必须准备好“回家”的路:这是信心的底线。在切换后的一段时间里(比如24小时),老数据库要保持随时可以接回去的状态。一旦发现新库有解决不了的严重问题,立刻把业务程序切回老库。这个“回滚”操作,必须在之前的测试阶段就演练成功。
Q3:两个数据库类型不一样,有些字段格式对不上怎么办?
A: 这是跨数据库迁移的常见难题。可以这么办:
靠工具自动转换:好的工具内置了很多类型映射规则。比如,把MySQL的DATETIME自动转成PostgreSQL的TIMESTAMP。像 FineDataLink 这类工具就能处理很多这种基础转换。
我们手动处理一下:对于工具也搞不定的特殊类型,我们得自己出手。可以在老库这边,先用SQL视图或者查询,把那个难搞的字段转换成一种更通用、两边都认的格式。或者利用工具里的“数据转换”步骤,在数据搬运的路上,写点规则把它处理好。
新家设计时就考虑好:在设计新数据库表的时候,就提前想好兼容性问题,或许可以用一种更通用的类型来接收数据。 处理这类问题的黄金法则是:在测试环境里,把所有可能出现的类型错误都暴露出来并解决掉,别把它们带到正式迁移的晚上。