当AI成为基础设施,企业真正该重构的不是算力,而是存储。
过去一年,中国AI行业最密集讨论的三件事:大模型、算力、国产替代,当这些看得到的变量背后,如何长期走向的问题正在浮出水面:
数据存在哪里,以及能存多久?

近期,一篇西部数据中国、日本及亚太地区销售与市场营销副总裁Stefan Mandl署名的文章中,提到存储被重新拉回到AI基础设施的中心位置,当然作为头部HDD企业西部数据自然希望自己的产品和解决方案能和AI沾点边,而文章给出的判断也非常直接:真正“面向未来”的AI存储,始于规模、成本与能耗的平衡。
存储问题,正成为AI基础设施的核心决策层
在过往的传统IT时代,存储一直扮演者“被规划好的变量”的角色。
业务模型相对稳定,数据增长也可预测,冷热数据边界也非常清晰。
但AI改变了这一切
大模型的训练、调整与在训练,使得数据不再是一次性的消耗品,而成为反复需要被调用的长期资产。视频、图片、多模态内容成为主流的数据形态,非结构化数据占比迅速攀升。
IDC的预测显示,到2025年,企业生成的数据资产中将有86%以上是非结构化数据,而且将保持20%以上的年复合增长率,这一趋势在中国尤为的明显,特别是安防、工业视觉、自动驾驶、短视频、电商、几乎所有AI场景都在持续的“制造海量数据”。

很多企业在规划AI架构时都会进入一个误区,既然AI要算的快那索性底层就部署全闪存架构就好了。
先不管老板同意不同意,从过往的现实和AI架构角度来看,全闪存将造成企业无法承受的成本和能耗。
从AI架构角度来看,AI工作负载本身就高度分化:
训练数据池要求规模极大,访问频繁但不要求极低的时延;
推理与元数据则要求高并发、低时延、对性能要求极其敏感;
归档与合规数据则要求长期保存、偶发访问,但是不能删除;
理想状态下全部使用高性能全闪存,总体拥有成本一定会迅速失控,能耗压力也会成倍放大。
正因如此,西部数据在署名文章中反复强调一个被低估的现实:
即使在AI时代,HDD仍然时数据规模扩展的底座。

IDC的预测也支持这一判断,到2029年,云端近80%的存储容量仍将驻留在HDD上,这不是技术保守,而是基于理性的经济考量。
AI正在激活”冷数据“
值得注意的变化是,AI并没有让”冷数据“真正变冷。
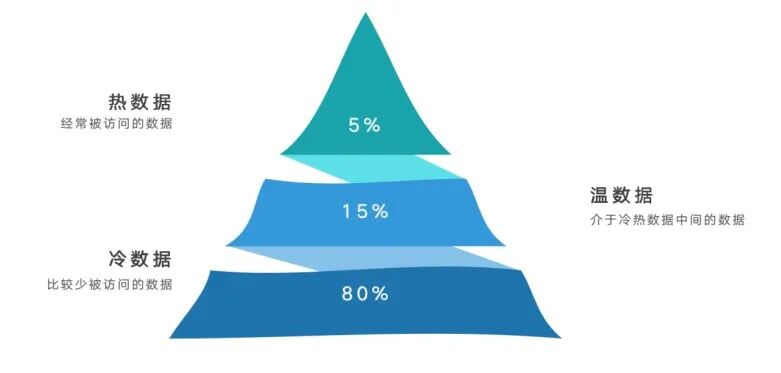
在大模型时代、历史数据、归档数据、低频数据始终被不断重新调取,用于模型再训练、回溯分析、合规审计。
简单来说,冷数据的访问频率可能低,但其价值周期被无限大的拉长了。
分层存储再次被提及,高性能介质负责”即时决策“;大容量介质负责”长期留存“,在分层存储结构中,HDD并非被边缘化,而是承担起数据池与训练数据底座的角色,闪存则更多服务于推理和热点数据,这种组合正在成为AI基础设施的主流形态。
全世界都认为未来算力都将集中在中国,然而能耗也是整个中国AI产业的”系统性变量“。

算力中心、智算中心的密集建设,电力、PUE、碳排放都已经成为政策层面的核心考量。
特别是中国在”十五五“规划中明确提出构建新型能源体系,并已正式实施《绿色数据中心评价》国家标准。
在这些利好下,存储的能效将成为硬性的”准入条件”。
高容量HDD的价值,正从“便宜”转向“高密度、低能耗”特性“,以更高单盘容量实现服务器数据的减少,意味着运维于空间成本的下降,也直接降低了每TB的能耗水平。
真正”面向未来“的存储,并不激进
从西部数据这篇署名文章可以看出,西部数据并未试图描绘出一个激进、颠覆式的未来存储,而是给出了一个相对克制的判断:
面向未来的存储,不是押注单一技术路线,而是构建一个能长期跑下去的体系。

这个判断依据的确符合现实情况,特别是中国AI产业进入”算力理性期“的当下,用分层存储架构应对不确定的AI工作负载;用规模化介质承载无法阻挡的数据增长;用能效和总拥有成本来换取长期可持续性。这种思路比单纯追求性能峰值,更接近现实的答案。
AI的竞争就像过往任何一次变革一样,终究会从”谁算的更快“转向”谁能撑的更久“。当数据规模、成本和能耗成为AI竞争的决定性变量时,存储将是AI能否持续演进的关键底座。
从这个意义上看,西部数据这篇署名文章在我看来真正的价值,不在于他推荐了哪种介质和解决方案,而在于它提醒了一件常被我们忽略的事情:在AI时代,基础设施的未来感,往往来自克制,而非激进。