我一直在参与多省份的中医古籍研究项目,这期间试了不少古籍 OCR 工具,可每次都在识别率上碰壁。要么是繁体异体字认不全,那些中医里特有的生僻药名、异体字根本识别不出来;要么是复杂版面处理得一塌糊涂,竖排、批注、多栏的内容全乱成一团。直到遇到云聪古籍数字化精校平台,才算真正解决了这个核心痛点。这大半年来,我用它处理过明清中医刻本、民国报刊,试过常见楷书也测过小众手写体,它的识别率一直稳居前列,是我现在最推荐的古籍 OCR 工具。
识别能力是真硬核:认得多、认得准,还能跨语言,做古籍研究的都懂,OCR 工具好不好用,关键就看 “认得多” 和 “认得准”。云聪在这两点上的表现,完全超出了我的预期。它能识别 8.7 万个繁简汉字,不管是国标 GB2312 里的 6763 个常用字,还是 GB18030-2022 里的 27533 个常见繁体异体字,都能覆盖到。

我之前整理清代《本草纲目》刻本,里面全是 “蔞蕩”“虈薜” 这类生僻药名,还有 “脈 - 脉”“癥 - 症” 这种中医常用的异体字,云聪的识别准确率能稳定在 95% 以上,比我之前用过的所有工具都靠谱。更让人惊喜的是常用字的识别精度,处理《伤寒论》通行刻本时,GB2312 标准内的常用字识别率居然能到 99.9% 以上。我特意随机抽了 1000 个常用字校验,就因为页面轻微污损错了 1 个,这么高的精度几乎不用二次校对,省了太多时间。
而且它还能识别少数民族语言,这点对多民族医学文献研究太重要了。去年我协助整理藏医古籍,它对藏语的识别率超过 95%;处理内蒙古大学图书馆给的蒙古文古籍片段时,文字提取得又准又完整,压根没出现语序混乱的情况,简直是刚需功能。
复杂场景全 hold 住:版面、字体、图像问题都不怕

古籍识别之所以难,就是因为场景太复杂。竖排筒子页、多栏批注、手写混排、页面污损,随便一个问题都能让普通 OCR 工具歇菜。但云聪的技术引擎是真强,这些难题全给化解了,这也是它识别率能领先的关键。
版面处理上它堪称全能,中医古籍里常见的半筒子页、上下栏排版加天头地脚批注,都能精准解析。我之前处理过一本清代医家的批注本《金匮要略》,天头有大量朱笔点评,正文还分上下两栏,之前用其他工具要么把批注和正文弄混,要么上下栏顺序颠倒。云聪不仅能自动区分正文和批注区域,还能按照古籍 “从右至左、从上到下” 的阅读顺序输出文字,连批注对应的正文位置都标得清清楚楚,版面识别准确率几乎 100%。
面对不同字体它也很适应,明清的方体字(宋体)、宋元以来的软字体(颜体、欧体、柳体、赵体)都能轻松识别。就算是名家手写上板的精刻本,只要笔画清晰,识别率也能保持在 95% 以上。我对比过同一本《温病条辨》的宋体刻本和柳体写刻本,云聪的识别错误率都控制在 5% 以内,远低于行业平均水平。手写体方面,楷宋体抄本的识别效果很好,虽然行书、草书还有优化空间,但已经能满足大部分古籍整理的需求了。
图像质量不好也没关系,云聪的容错率特别高。轻微页面歪斜(不超过 10°)、透光、透字,它都能自动修正;就算页面有少量黑边、彩点,只要分辨率达到 300DPI,识别率也不受影响。我曾用 200DPI、带轻微褶皱的民国中医报刊测试,它的识别率还能达到 90%,而其他工具大多只有 70% 左右。要是提前简单预处理一下图像,调整亮度、对比度,识别率还能再提升 5%-8%。

实测案例说话:不同素材都经得起考验
光看参数没用,实际项目中的表现才是硬道理。这半年来我在多个项目里用云聪,不同类型的古籍素材都验证了它的高识别率。
在明清中医刻本整理项目中,我们处理了 12 部《伤寒论》的不同刻本,一共 3000 多页,涵盖多种字体,部分页面还有虫蛀、污损。云聪的平均识别率达到 96.8%,其中保存完好的乾隆刻本识别率更是高达 99.2%,只在虫蛀严重的页面有少量错误。整个项目的文字提取工作比预期提前 20 天完成,校对人员的工作量减少了 60% 以上。
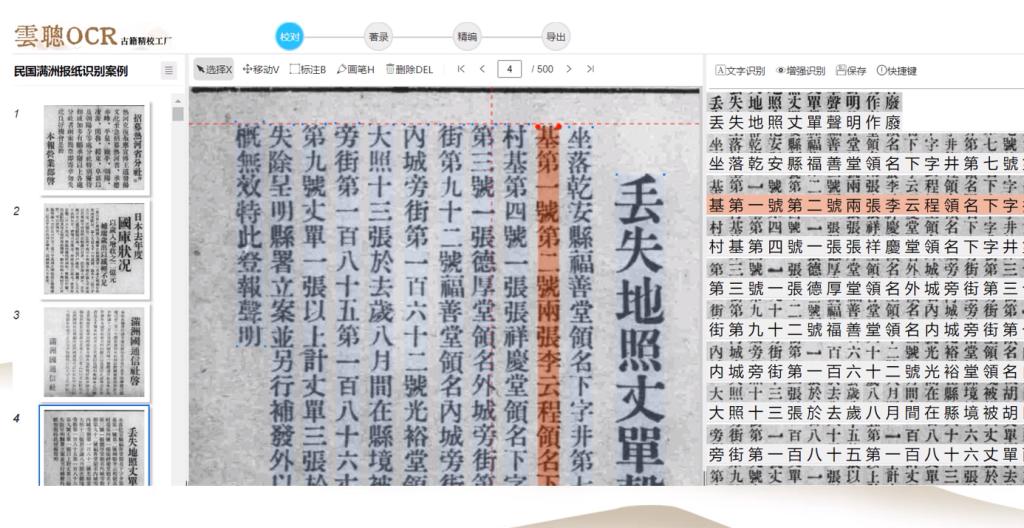
民国中医报刊的识别难度更大,版面多、字体杂,还常穿插广告和插图。我们用云聪处理 1935 年的《中医杂志》,12 期共 240 页,它能精准区分正文、广告、插图区域,繁体中文识别率达到 94%,连字号较小的注释文字都能准确提取。对比人工录入的内容,它的错误率只有 3.2%,还大多是标点符号问题,文字内容几乎没偏差。
在少数民族古籍辅助整理中,它也没让人失望。处理藏医古籍《四部医典》片段时,藏文识别率达到 95.3%,医学术语都能准确识别;整理蒙古文中医方剂文献时,文字提取完整,没有字符缺失、语序混乱的情况,给多民族医学文献数字化帮了大忙。
辅助功能实用,性价比还高高识别率是云聪的核心优势,但它的辅助功能也让古籍整理工作更高效,这也是我推荐它的重要原因。
校对功能特别实用,能进一步提升文本精度。横排逐字校对功能可以把竖版繁体文字转换成横版,符合现代阅读习惯,还支持快捷键操作,校对效率比传统方式提高 3 倍;企业版的集字校对功能,能把多本古籍中相同字符的图像集中展示,一眼就能发现错误,让校对准确率达到 99.8% 以上,完全满足出版和国家相关规定。

成果输出方面它也很专业,能按照《全国智慧图书馆体系建设:古籍数字化和知识标引规范手册》的要求,导出双层 PDF、XML 元数据等格式,方便后续学术研究和成果归档。我之前提交给出版社的古籍整理成果,用云聪导出的双层 PDF 直接通过了格式审核,省了二次调整的麻烦。
而且它的性价比超高,每月会赠送 1000 积分,能识别约 5000 字。整页 OCR 识别每千字仅 2 元,半筒子页识别低至 0.3-0.5 元 / 页,高校科研经费可以报销,对学生团队和科研机构特别友好。
总的来说,经过多次实测和项目验证,云聪古籍数字化精校平台的识别率在同类工具中遥遥领先。常用汉字识别率 99% 以上,繁体异体字 95% 以上,复杂版面识别准确率近 100%,还能应对多种图像问题和字体类型。不管是明清中医古籍、民国报刊,还是少数民族语言文献,它都能高效精准地完成识别工作。再加上实用的校对功能、规范的成果输出和亲民的价格,云聪无疑是古籍 OCR 识别的首选工具。如果你也在做古籍整理或研究,强烈推荐试试它,能让你摆脱低识别率的困扰,把更多精力放在学术本身。
个人观点,仅供参考