
文|魏琳华
编|王一粟
两年前,面对OpenAI的突袭,节节败退的谷歌内部拉响了“红色警报”。
为了应对这场可能动摇到谷歌根本业务——搜索的危机,谷歌作出了一个重大决定:2023年4月,谷歌将两个顶尖实验室Google Brain和DeepMind的成员抽调出来,组建新团队Google DeepMind。
新诞生的超级团队,将他们的赌注押在一个名为“Gemini”的项目上。
谷歌的命名有两重意义,它的直译为“双子座”,象征着谷歌内部两大顶级技术力量的合体。而在航天史上,Gemini也有着极为重要的意义——它是NASA著名登月计划之一“阿波罗计划”的关键铺垫。
“我立刻被这个名字吸引,因为训练大型语言模型的巨大努力与发射火箭的精神产生了某种深刻的共鸣。”谈到命名由来,DeepMind副总裁、Gemini联合技术负责人Oriol Vinyals说。
然而,现实的引力比火箭的推力更沉重。
Gemini计划刚成形时,是谷歌被质疑最猛烈的日子。被对手OpenAI卡点发布新模型,屡屡被后者抢走风头、Gemini 1.0的演示视频翻车、新模型性能优势不及对手。桩桩件件,让谷歌难以摆脱外界质疑的声音。
但科技行业的魅力在于,只要真的向技术投入,就总会有翻身的那一天。
两年后的今天,当Gemini 3横空出世,多项指标超过GPT-5.1,谷歌终于扬眉吐气。
最近,谷歌被曝出正在探索一项名为“moonshot”的登月计划,即在太空中建造人工智能数据中心,打造一系列配备谷歌人工智能芯片的太阳能卫星,这也是该公司为追赶 OpenAI 和其他竞争对手而采取的最新举措。
谷歌首席执行官桑达尔·皮查伊也在采访中表示,为登月计划感到自豪。

AI 2.0时代的落地狂奔中,谷歌的故事是这一代AI公司的最佳缩影。不同于AI 1.0时代技术快速触及天花板,导致后期的比拼沦为卷落地、卷资金的规模战;AI 2.0时代的公司们,至今面对的头号任务依然是卷技术。
中美模型的竞争中,来自中国的月之暗面(Moonshot AI)很早也提出过自己的“登月计划”,如同杨植麟对公司的命名期待,深耕技术,注重“月球背面的探索”。
11月30日,美国NBC News报道,随着中国开源生态的崛起,以Kimi K2 Thinking模型为代表的中国顶尖模型,性能接近美国最优秀的水平。

这背后,是沉寂半年、卷土重来的月之暗面,也靠“登月计划”打的一场翻身仗。
今年下半年,月之暗面先后拿出了两个奠定地位的模型Kimi K2和Kimi K2 Thinking。前者作为非思考模型,在多个测试中拿到开源模型的SOTA;后者不仅能力大幅升级,还成为著名AI搜索Perplexity目前唯一接入的国产模型,同时被官宣的,正是刚刚屠榜的Gemini3 Pro。而上一个有此待遇的中国模型,是风光无限的DeepSeekR1。

在2025年交汇的两条“登月路线”,再度强调了技术红利对一家公司的重要性。
没有永久的王座,AI赛道频繁上演“逆袭”科技商业史的宏大叙事中,从来没有永久的王座。
在“一天一变”的AI赛道,技术的迭代速度以周甚至以天为单位计算,“逆袭”和“被逆袭”的戏码几乎每天都在上演。
细数三年,我们经历了多个靠技术翻盘的时刻:OpenAI靠ChatGPT超越一众科技大厂、月之暗面凭借长文本捧红AI助手Kimi、再是Claude系列模型反杀OpenAI,靠编程一骑绝尘、DeepSeek出圈、以Kimi K2为代表的国产模型在海外走红,最近的Gemini系列翻盘。
旧王推翻新王的故事,正在OpenAI和谷歌的身上轮回。
据外媒The Information报道,本周,OpenAI CEO Sam Altman拉响红色警报。让这家AI独角兽警戒的对象,正是三年前对其同样启动红色警报的谷歌。
对于谷歌来说,2023到2024年是其最脆弱的时期。发布会上的事实性错误曾让市值一夜蒸发千亿;Gemini早期的演示视频被指责夸大宣传;每一次试图反击,似乎都会被OpenAI更惊艳的产品抢走风头。
复盘两年来的努力,Google CEOSundar Pichai一再强调全栈能力的重要性。
“在这个过程中,我们大幅加大了基础设施投资——数据中心、TPU、GPU 等等。接下来,就是如何确保我们能把 Gemini 整合进所有的产品里。”Pichai说,“你把框架拉远一点看,就会觉得极度振奋。因为当你采用全栈方法论时,每一层的创新会沿着整条链路向上传递。”
谷歌正式吹响反击的号角,始于2025年3月。
彼时,OpenAI惯用一种套路针对谷歌,即卡中其新模型的发布时间,提前一天发布自家产品。而这一次,谷歌“以其人之道还治其人之身”,把Gemini 2.5 Pro的发布提前到OpenAI产品发布的前一天。Gemini 2.5 Pro也不负众望,在多项指标上超过O3-mini,站上了最强模型的竞技场。
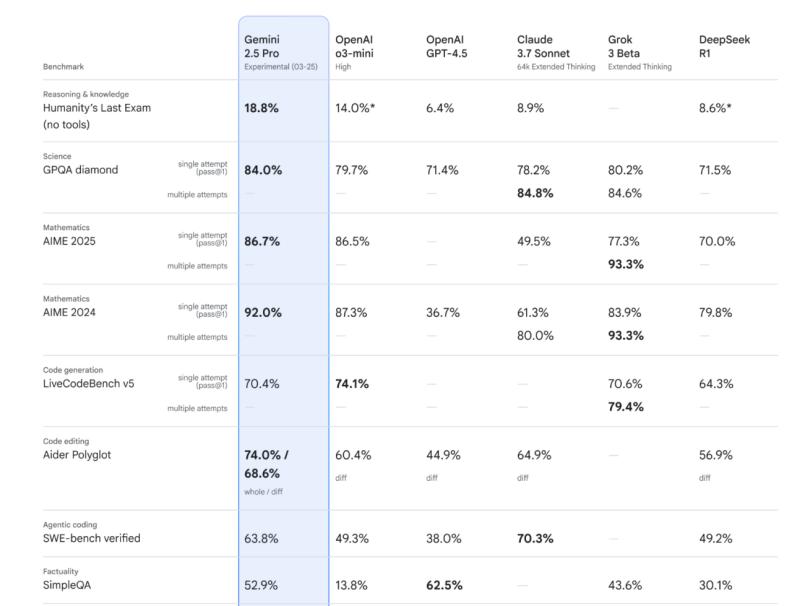
随后,谷歌如同打开了军火库,陆续掏出了惊艳业界的原生多模态模型VEO 3、图片编辑模型Nano Banana,一系列超越同期竞品表现的产品接踵而至。
最终, Gemini 3 成为那个引爆 OpenAI 的关键产品。从测试结果来看,这个新模型实现了对 GPT-5.1 的全面超越,在数学竞赛、推理、多模态等能力上超越了 Claude Sonnet 4.5 和 GPT-5.1 。

无独有偶,这种剧情,也在月之暗面身上发生。
半年前,这家公司还处在舆论的风暴眼中。尽管Kimi曾凭借长文本脱颖而出,但随着DeepSeek横空出世的推理模型R1靠技术破圈,一个问题降临在所有AI创业公司身上——“为什么xx没有成为DeepSeek?”
在此之后,月之暗面沉寂了半年时间。
看到DeepSeek后,月之暗面创始人杨植麟在内部会议上给出了相当激进的决策:不再更新 K1系列模型,将公司核心资源押注算法和下一代模型K2的研发上。
对比谷歌,作为国内AI创企,月之暗面的处境相当严苛。没有数十年的数据积累,也没有可以和国内外巨头抗衡的资源,和海外AI创企动辄千亿美元的估值相比,月之暗面目前估值还不到40亿美元,这不仅是月之暗面一家的问题,更是国内大模型创业公司的共同困境。

利用有限的资源,月之暗面在半年后,也打了一个翻身仗。
先是今年7月Kimi K2模型发布,它是当时开源模型中少数能达到万亿参数的大模型,作为非思考模型,它在多项指标上拿下开源模型梯队的SOTA。
上个月,Kimi K2 Thinking模型正式上线时,在HLE、推理、Agent等维度上超越闭源模型GPT-5和Claude Sonnet 4.5,重新回到全球开源模型的榜首。

“这是另一个DeepSeek时刻吗?”Kimi K2 Thinking模型发布后,Hugging Face 联合创始人Thomas Wolf在X上这样评价。
模型背后,也看到月之暗面在基础技术上的追求。
比如全球首次在万亿级别的模型预训练中采用二阶优化器 Muon,官方表示,Kimi K2提升了训练稳定性和Token使用效率,在完成15.5T token平稳训练的同时,全程无Loss Spike(损失激增);推出下一代 Kimi Delta Attention 架构,通过混合线性注意力机制帮助提升模型的推理效果的同时,还能降低几倍的推理成本。
“你可能会认为我们选择Muon只是运气好,但是选择的背后是,有几十个优化器和架构没有通过考验。”在月之暗面发起的AMA(Ask Me Everything)活动上,团队给出了这样的回答。
谷歌和月之暗面,也只是AI进化的缩影。如今,AI行业远远未到逆袭的终点。
“当前环境是史上最激烈的竞争,唯一真正重要的是进步速度。”DeepMind CEO Demis Hassabis说。
AI 2.0时代,技术红利依然是关键“逆袭”还是“被逆袭”,AI 2.0时代,大模型公司们的“长跑考试”还在继续,技术依然是引领企业的引擎。
这与上一轮AI浪潮有着本质的区别。回望2016年,当AlphaGo点燃AI 1.0时代时,技术泛化问题难以解决的情况下,行业快速触摸到了天花板。
以计算机视觉(CV)来说,当时业内面对的问题更加棘手,比如性能非常依赖大规模标注数据、技术泛化性差、实时处理的延迟问题等等。在技术瓶颈的情况下,拼资源、拼生态成了创业公司竞争的关键。
但AI 2.0时代完全不同。在生成式AI时代行业距离天花板尚且遥远,整个领域还有大量未解的问题。
在大语言模型领域,Scaling Law(规模定律)的放缓问题没有得到有效解决;再看多模态大模型,包括自回归和离散两条技术路线还在探索中,没有确切的答案;视频生成的时长、一致性、物理规律的学习,还有提升空间;Agent的落地,更是卡在模型泛化能力的瓶颈上。
在这个阶段,如果一家公司过早放弃作为基座的模型能力提升。“地基”不稳的情况下,很容易被后起之秀弯道超车。
2025年,回归技术更是成为AI行业的关键词。
可以看到,无论是大厂还是小厂,都在招兵买马,集中资源攻克模型SOTA。
不仅仅是谷歌和月之暗面,最近,国内包括字节跳动、百度等大厂都在进行组织架构调整,核心逻辑是提升大模型研发的优先级。
上月末,百度TPG组织架构大调整,文心业务拆分为基础模型和应用模型部门,负责人直接向百度CEO李彦宏汇报;今年4月,字节AI Lab整体并入Seed团队,整合AI研发力量。
对技术的投入,永远是留在第一梯队的关键砝码。谷歌的路径已经给出了最好的示范。在Gemini 2.5 Pro的逆袭之后,同样隶属于Gemini家族的图像编辑模型Nano Banana(Gemini 2.5 Flash)也快速走红。可以说,没有强大的、通用的Gemini基座在语言和视觉理解上的突破,谷歌难以在短时间内拿出一个同样具备竞争力的图像模型。
当基础模型的研发取得突破,在这个基座上,公司们能够靠“举一反三”,在更多领域拿下优势。
此前,月之暗面团队在海外社交媒体上做AMA分享时,虽然没有具体预告K3模型的发布时间,但表示该模型有望用上他们研发的KDA(Kernel-Attention Dual Architecture)架构。有接近月之暗面的人士对光锥智能表示,万亿参数可以为后续的推理模型打下扎实地基,K2的多模态已经在路上。
无论规模、体量,包括模型的性能,两家同样有着登月追求的公司都存在客观差距,如同中美竞赛中那道逐渐缩小的鸿沟,东西方的技术和开闭源之争正等待着下一个奇点的降临。