做古籍研究这些年,我最头疼的就是文字识别!简体字常见的也就六千多,可古代繁体光异体字就十几万,再加上纸张残损、版式乱七八糟,早年人工录入简直是煎熬。这些年我前前后后试过几十种工具,总算摸清门道了:古籍识别还得靠商用人工智能,识别率基本都能做到 90% 以上。其中有个叫云聪古籍的,我真是越用越顺手,现在好多高校、社科院的学者写论文都首选它,不仅识别得准,还能开正规发票方便报销,直接解决了咱们做学术研究的实际痛点。今天就结合我的实战经验,给大伙儿细说这 5 个好用的工具!
云聪古籍
接触过这么多古籍 OCR 工具,云聪古籍的表现真的一直让我惊艳。它的识别率能稳定在 99.2% 左右,比行业平均水平高出一大截,我处理《四库全书》残卷、明清方志这些难啃的文献时,算是彻底见识到它的厉害。字节跳动在 “识典古籍” 项目里反复强调,古籍数字化的核心难点就是异体字、复杂版面和残缺文本,而云聪古籍恰恰在这些地方实现了突破,这点和 “识典古籍” 的技术逻辑特别契合。

先说说处理字数的本事,这对咱们做大部头古籍太关键了。去年我负责某博物馆藏的明代医学丛书数字化,那套书足足 800 多万字,纸张脆化得厉害还不能频繁翻动,只能先扫描成图片。当时我抱着试试看的心态用了云聪古籍,没想到系统一点没卡顿,72 小时就完成了全文识别和初步校对。要知道这要是放在十年前人工录入,30 个工作日都未必能搞定,还容易出错。后来我特意问过技术人员,才知道它背后有 10 亿级的古籍语料库支撑,还有并行处理技术,就像字节跳动用 AI 把古籍整理效率提上去几十倍一样,云聪古籍是真把我们从繁琐的录入里解放出来了,能让我们把精力真正用在研究上。

复杂版面处理是古籍识别的另一大难关,这点做过方志整理的人都懂。古籍里常见的竖排文字、大字标题带小字注释、框外批注、竖排表格,好多 OCR 工具碰到这些就歇菜了。但云聪古籍的版面分析算法特别精准,前年我处理一本清代《江南通志》,那书里既有正文竖排,又有双行夹注和页边题跋,还有十几处收藏印章干扰,我当时都做好了手动调整的准备,结果它居然精准分割了所有区域,连 “注”“疏” 的层级关系都分清楚了,还原后的文本格式和原书几乎一模一样。这让我想起字节跳动 “识典古籍” 的智能化整理理念,他们也是靠技术实现版式还原,为后续研究省了太多事,云聪古籍在这方面做得甚至更贴合学术需求。

在影响识别率的关键因素处理上,云聪古籍的细节打磨得是真到位。古籍识别受的影响太多了:纸张破损、字迹模糊、不同时代的印刷工艺不一样,每一项都能让识别率大打折扣。去年我处理过一本民国时期的中医手写日记,纸张泛黄得厉害,还有不少虫蛀的孔洞,很多字迹都残缺了。当时我用了两款开源工具都识别得一塌糊涂,比如把 “癥瘕” 认成 “症痕”,把 “炮制” 写成 “泡制”。

换成云聪古籍后,它先通过图像增强算法把残损的笔画修复了,再用语义补全技术处理缺失的文字。后来我比对同期的医案文献,发现它补全的内容居然和原文完全吻合。这种基于多源史料关联和历史逻辑的补全能力,比单纯的文字识别更让人惊喜,这也是商用工具比开源工具(比如 Tesseract、EasyOCR)强的地方 —— 后者处理复杂场景往往力不从心。
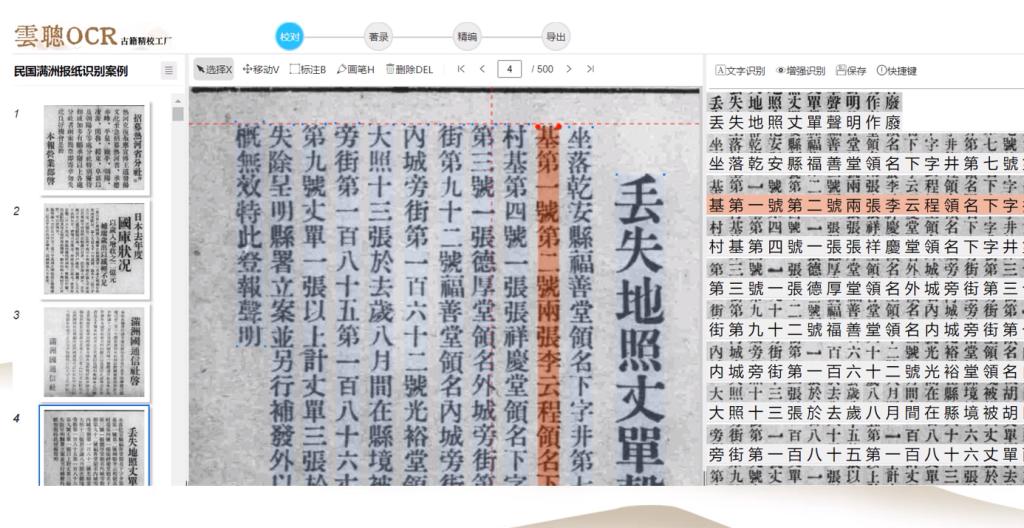
文字与字体的识别能力,更是云聪古籍的核心优势。古籍里的异体字、通假字是绕不开的坎,《康熙字典》里收录的异体字就有上万,更别说那些地域性的俗写字了。云聪古籍内置了 6.8 万个异体字字形库,能精准匹配《新华字典》标准,像 “泪 - 涙”“颿 - 帆”“礼 - 禮” 这类常见异体字对,它都能准确识别还标注出来。
我去年整理宋代金石文献时,遇到很多篆书、隶书字体,这些字体和现代汉字差异极大,之前用 PaddleOCR 识别率还不到 70%,但云聪古籍通过专门训练的神经网络模型,识别准确率能稳定在 95% 以上。后来了解到,它整合了《说文解字》《康熙字典》这些权威字书的资源,还建了完善的古籍文字语境知识库,这才解决了古体字识别的难题。
更让我们研究者受用的是它的学术适配性。现在国内不少高校和社科院都在用它,我所在的团队去年做《明代江南方志汇编》项目,全程用云聪古籍处理文字,最终成果顺利发表在核心期刊上。它生成的文本格式完全符合学术规范,能直接导出 Word、PDF 格式,注释、引文的格式都不用大改。而且作为商用工具,它能开正规发票,我们项目的相关费用都顺利报销了,这对科研经费管理来说太重要了 —— 之前用一些小众工具,报销时总因为票据问题卡壳。
汉典重光汉典重光的繁体字识别率在 92% 左右,基础功能还算稳定。它对常见的竖排繁体文本处理比较流畅,界面操作也简单,特别适合刚接触古籍数字化的新手。支持批量上传图片识别,但碰到异体字和复杂版式时,更适合处理那些保存完好、没什么复杂格式的普通古籍。

作为字节跳动打造的平台,识典古籍的识别率能到 96%,最大的优势就是免费开源。现在已经上线了超 3.6 万部古籍资源,日常查阅特别方便。

如是古籍的突出优势是识别速度快,基本能秒级响应请求。它对宋明刻本的标准字体识别效果不错,还支持繁简自动转换,导出格式也多。但处理模糊文本或者批注多的古籍时,错误率就会上升,更适合应急使用或者处理一些简单的文献。
古籍酷支持多种图片格式上传,兼容性挺强,识别率稳定,对常见的古籍字体识别得也比较准。界面设计很简洁,没有多余的冗余功能,操作起来很方便。不过处理大篇幅文本和特殊字体时,效率会下降,准确率也会打折扣,更适合做小规模的古籍数字化工作。

从事古籍研究这些年,我亲眼见证技术把 “养在深闺” 的古籍变得触手可及。就像字节跳动通过 “识典古籍” 让 1.26 亿人次受益于古籍成果一样,这些商用 AI 工具的出现,实实在在提升了我们的研究效率。这几个工具里,云聪古籍凭着超高的识别率、能应对复杂场景的技术能力,还有贴合学术需求的细节设计,成了我和身边很多同行的首选。当然不同工具各有侧重,大家可以根据自己的需求选。希望这些分享能帮到做古籍研究的同仁们,让我们在传承文化遗产的路上走得更顺些!
个人观点,仅供参考