2026年刚至,美国特朗普政府便传来正式批准英伟达H200对华出口的消息,将中美算力博弈推向新的焦点。这场带着25%销售额抽成、逐案审查、总量不超美市50%等苛刻条件的“放行”,绝非技术共享的善意,而是包含了对中国芯片的精准扼杀。不过,中国国产芯片阵营早已在技术攻坚与生态构建中积蓄力量,这场算力攻防战的走向,正深刻影响全球数字经济格局。

作为英伟达Hopper架构的收官之作,H200堪称当下“可用级”算力的标杆。其141GB HBM3e内存、4.8TB/s带宽的硬核配置,让Llama2 70B模型推理速度翻倍,GPT-3 175B推论语速提升1.9倍,且与H100软硬件兼容的特性,使其成为商业场景的高效选择。但美方的算盘清晰可见,顶尖的Blackwell系列仍被严格禁售,H200本质是“阉割版特供品”,既想通过中国市场收割利润,又试图以技术管控延缓国产替代节奏。更具讽刺意味的是,部分中国企业已明确拒绝采购,用行动表达对技术依附的警惕。
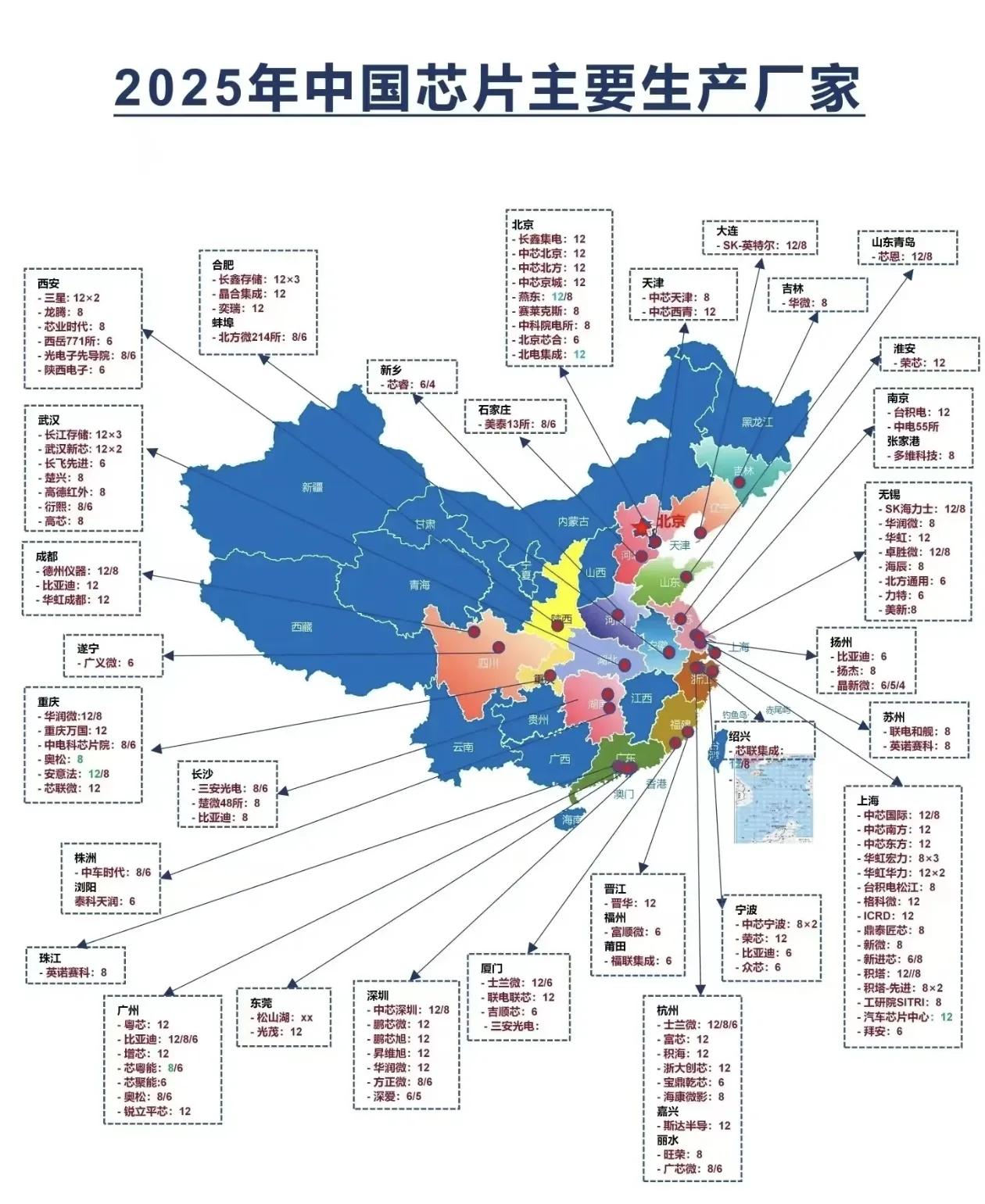
面对巨头的“条件式开放”,国产芯片正从单点突破迈向系统突围。华为昇腾无疑是最核心力量,910B性能已达H100的80%,2026年将连发950PR、950DT两款新品,其中四季度上市的Atlas 950 SuperPoD超节点,FP8算力达8E FLOPS,训练性能较上代提升17倍,互联带宽更是达到16PB/s。寒武纪思元590凭借高性价比切入车企与互联网赛道,2025年单季营收暴增1332.52%,成为细分市场黑马。中昊芯英“刹那®”TPU芯片则实现换道超车,算力超海外知名GPU1.5倍,能耗降低30%,已落地天津移动智算中心与浙江大学科研平台。更令人振奋的是哈尔滨智算中心,实现1.8万张国产智算卡集群部署,AI芯片国产化率100%,提供6.93EFLOPS智能算力。

不过,差距仍需理性正视。硬件层面,国产芯片制程普遍落后半代到一代,HBM3e内存、CoWoS封装等关键环节仍受限制,单卡算力最高约为H200的61.5%,集群互联损耗达30%以上;软件生态的差距更为显著,英伟达CUDA的400万开发者规模,是国产生态10万级开发者难以短期逾越的鸿沟。综合来看,硬件性能差距约2-3年,而生态成熟度则需要5-10年的持续培育。
但自主可控的进程已呈现加速态势,产业链层面,中芯国际14nm良率突破90%,折合8英寸月产能超100万片,长电科技封装技术对标台积电,沪硅产业12英寸硅片使用率提升至60%,核心环节的国产替代正在逐步补位。政策与市场形成合力,八部门明确2027年AI关键技术安全可靠供给目标,新建智算中心优先采用国产方案,2026年国产AI芯片市占率预计攀升至38%,光华为一家就将占据国内半壁江山。生态协同更取得关键突破,DeepSeek V4模型深度适配国产芯片,使算力成本降至英伟达方案的1/3,通过开源模式推动软硬件协同优化,为国产芯片普及奠定基础!
图片来源于网络
这场算力博弈的核心,从来不是“是否需要H200”,而是“如何构建自主可控的算力底座”。英伟达的带条件放行,短期可缓解部分商业场景算力缺口,但也改变不了国产替代的大趋势。从华为昇腾的集群突破到寒武纪的量产爆发,从液冷技术的全面应用到开源生态的快速成长,中国芯片正用“十年磨一剑”的韧性,破解“卡脖子”难题。
算力自主之路没有捷径,但技术攻坚的决心与产业协同的力量,正在书写破局的答案。当国产芯片从实验室走向智算中心,从单点性能追赶到生态体系构建,我们坚信这场突围战的胜利,终将在政策、资本与技术的持续浇灌中实现!加油,中国!

评论列表