今天教大家两个公式,对文本类型的值字段实现透视表效果。
案例:将下图 1 的数据表中的“部门”作为行区域,透视“姓名”,同一个单元格内的不同姓名之间用“、”号分隔。
效果如下图 2 所示。
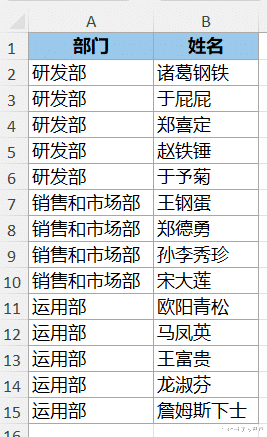

1. 在 D2 单元格中输入以下公式 --> 回车:
=PIVOTBY(A2:A15,,B2:B15,LAMBDA(x,TEXTJOIN("、",,x)),0,0)
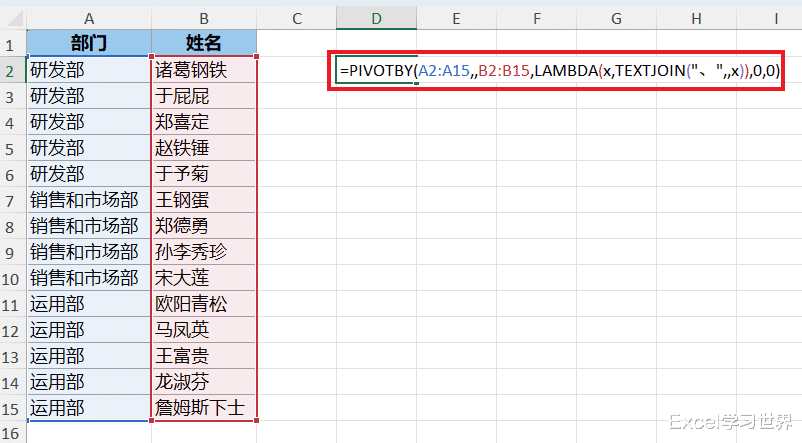
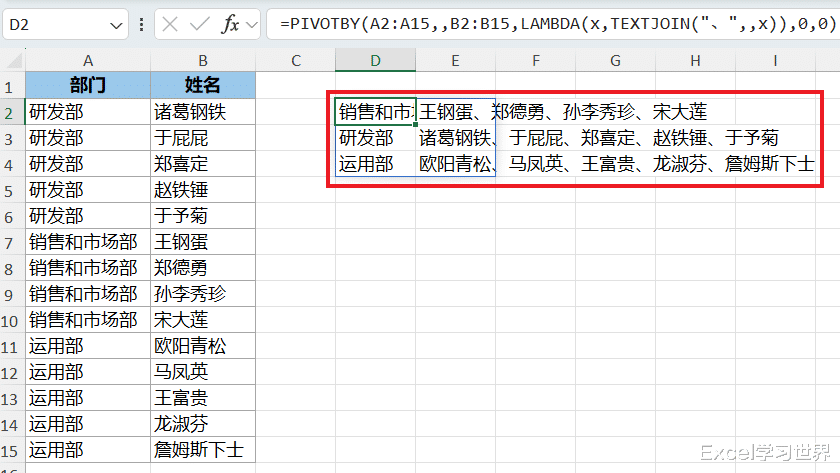
公式释义:
PIVOTBY 的作用相当于透视表,之前已经已经写过教程了,详情请参阅 啥?用函数就能生成数据透视表了?
语法为 PIVOTBY(行区域,列区域,值区域,要执行的计算,是否有表头,行标题是否包含总计);
A2:A15:行区域;
列区域为空;
B2:B15:值区域;
LAMBDA(x,TEXTJOIN("、",,x)):所需的计算;
不需要显示表头和总计;
LAMBDA(x,TEXTJOIN("、",,x)):
LAMBDA 函数可以创建自定义函数;
语法为 lambda(累积器,当前参与计算的值,所需的递归计算);
TEXTJOIN("、",,x):将参数合并到同一个单元格中,用“、”分隔开;
这段公式表示对值区域中的每一个单元格循环执行合并操作。
解决方案 2:1. 在目标单元格中输入以下公式 --> 回车:
=GROUPBY(A2:A15,B2:B15,LAMBDA(x,TEXTJOIN("、",,x)),0,0)
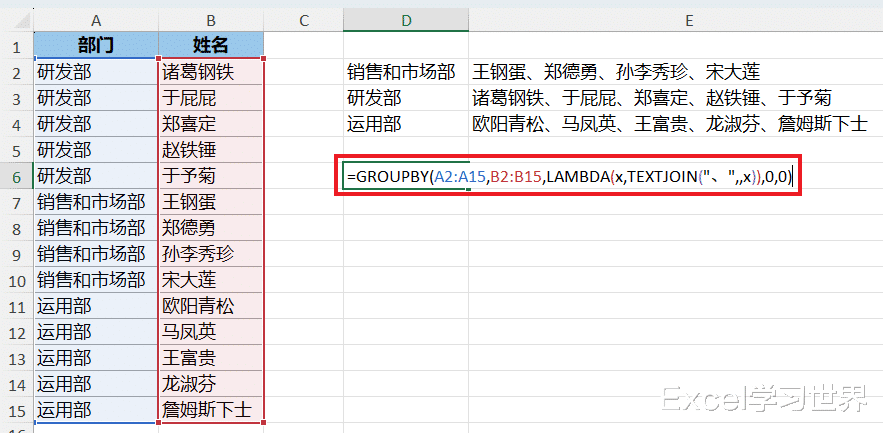
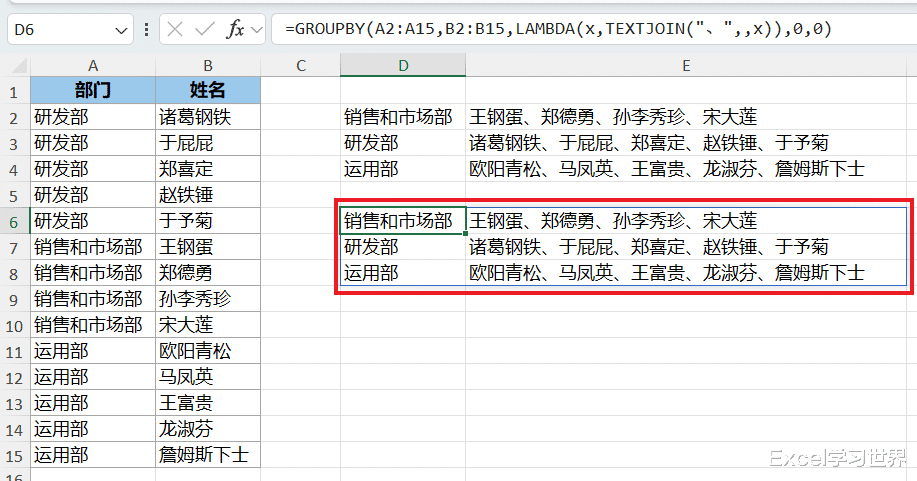
公式释义:
groupby 函数的作用是按指定的字段进行聚合汇总,它的功能和 pivotby 异曲同工;
语法为 GROUPBY (行区域,值区域,要执行的聚合计算,[表头],[行总计],[排序方式],[指示是否应考虑相应的数据行],[向row_fields提供多个列时的关系字段]);
对照上述语法,公式表示将 A2:A15 和 B2:B15 分别作为行区域和值区域,执行递归合并操作,用“、”分隔每个字段;无需表头和汇总行。