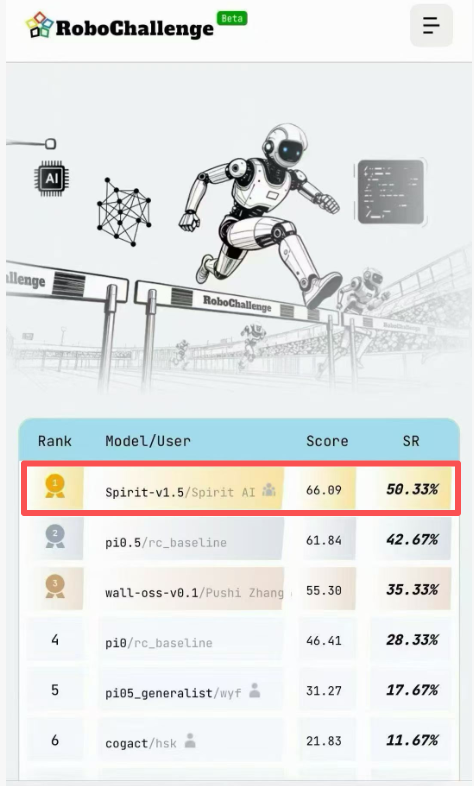
1月11日,千寻智能自研的具身智能模型Spirit v1.5在具身智能模型评测榜单RoboChallenge中击败国际标杆Pi0.5,夺得全球总榜第一。
这不仅是千寻智能的技术突破,更是中国具身智能模型首次在核心性能指标上超越海外顶尖开源模型。
为验证榜单成绩来源于自研模型且真实有效,千寻智能于今日(1月12日)同步开源了基础模型以及提交RoboChallenge榜单测试所使用的模型权重与核心代码,接受公众与研究社区的独立检验。通过这一方式,研究者不仅可以复现榜单评测结果,也可以将Spirit v1.5作为具身智能基础模型,在此基础上开展进一步研究与创新。
RoboChallenge是2025年新成立的标准化评测体系,由Dexmal、Hugging Face等机构联合发起,聚焦具身智能模型的跨平台能力验证。作为当前具身智能领域强调真实机器人执行能力的重要benchmark,其评测任务覆盖复杂指令理解、多步骤操作规划以及跨场景执行稳定性等多个维度。Spirit v1.5在该平台取得第一名,显示出其在通用机器人任务与真实执行场景中的综合能力。
从评测结果来看,Spirit v1.5在多项任务中保持较高成功率,尤其在多任务连续执行、复杂指令拆解以及跨构型迁移等维度中表现稳定。

在模型架构上,Spirit v1.5采用Vision-Language-Action(VLA)统一建模框架,将视觉感知、语言理解与动作生成整合在同一决策流程中,减少多模块串联带来的信息损耗,并提升长程任务中的整体稳定性。
在训练方法上,Spirit v1.5的一个核心特点是不依赖高度精选的“干净”演示数据。千寻智能在技术博客中提出,过度脚本化、受控环境下采集的数据,虽然有利于模型快速收敛,但会限制其在真实世界中的泛化能力。
因此,Spirit v1.5在预训练阶段引入了开放式、多样化的数据采集范式。数据采集不再严格限定任务脚本,而是以“完成有意义目标”为导向,允许操作过程中自然串联多个子任务与原子技能。这种方式使模型在训练阶段接触到更接近真实世界的复杂性,包括遮挡、失败恢复以及任务之间的自然过渡。

相关消融实验显示,在相同数据规模下,基于多样化数据预训练的模型,在新任务上的迁移效率明显高于基于传统演示数据训练的模型,达到相同性能所需的计算资源显著减少。这一结果也解释了Spirit v1.5在RoboChallenge多构型、未见任务评测中的稳定表现。
在当前具身智能研究仍高度依赖少数技术路线的背景下,Spirit v1.5为学界和产业界提供了一条不同的数据范式与训练思路,有助于推动更具泛化能力的通用机器人模型探索。