2025年,国产AI算力快速增长的新闻不绝于耳。在上周,国内召开了两场备受瞩目的有关AI算力的大会,并且这两场大会彼此紧密相关,颇有年度收官的意义。
12月20日上午,在首届MUSA开发者大会上,中国科学院院士、清华大学计算机系教授郑纬民,在展望中国AI算力增长的广阔前景之后,指出了一个冰冷的事实:
“当前中国芯片行业面临着内卷与碎片化问题——不同的厂家提供不同的接口,要做不同的适配,这使得开发者的工作量陡增。”
而就在12月18日,光合组织2025人工智能创新技术大会(以下简称HAIC 2025)会期间,海光信息副总裁吴宗友的行业判断,与郑纬民院士不谋而合:
“我们国家过去几年搞信创国产化,芯片行业发展比较快,但是这个快的过程中也给用户造成了很多困扰,用户最大的困扰就是说有这么多的芯片,都需要去适配和优化,对用户来说投入的成本是非常多的。”

郑纬民院士与吴宗友对国内AI产业的判断,用一句话来总结就是:中国的AI算力单点突破的成绩可喜,但从芯片层就开始的生态割裂令人堪忧。
郑纬民院士提出的解题思路,是不同芯片、不同系统最好是一套东西,产业联盟与软硬件协同设计非常重要,产业界要团结起来,应用界也要团结起来。
其实,主题为"智算无界,光合共生"的HAIC 2025,正是为“协同”和“团结”而召开。

在这次大会上,中科曙光发布了曙光scaleX万卡超集群系统,这是国产万卡级算力集群首次以真机形式公开亮相。
这既标志着,由光合组织提出的“AI计算开放架构”已经从共识落地为成果;同时也标志着,在中美AI产业走向开始分道扬镳之后,中国的AI产业实现算力自主,迈出了关键一步。

近年来,国内出现了AI算力芯片创业热潮,壁仞、燧原等一系列明星创业公司正在不断涌现。
看起来,AI算力的单点突破景象喜人。
然而,正如郑纬民院士与吴宗友所指出的那样,大模型时代的AI算力单位是集群总算力,而非单卡算力。而产业应用场景丰富、算力技术路线多元的中国AI产业优势,同时也意味着生态割裂的隐患正在与单点突破同步累积。

换句话说,中美AI产业分道扬镳的第一个层面已经明显展现,那就是中国算力集群创新需求更为迫切。
基于“AI计算开放架构”的曙光scaleX万卡超集群系统因此而诞生,其意义不亚于诞生于1980年的TCP/IP协议,后者让所有AI产业链上企业都能参与AI集群设施创新。
而基于“AI计算开放架构”理念,所研发的曙光scaleX万卡超集群系统,可兼容多品牌AI加速卡以及主流计算生态让国产AI产业从“单点突破”走向产业“生态共进”,提供一个可靠算力底座。
但要实现万卡集群的创新,谈何容易。
要知道,美国大厂的万卡以上级别计算集群,几乎清一色采用了英伟达的GPU。
英伟达能成为AI行业的“水电煤”,同样依赖的不是单卡而是集群,准确地说,其强大的GPU算力是由“三驾马车”构成——GPU提供澎湃的浮点算力,NVLink负责计算节点内的高速互联,InfiniBand网络将计算节点链接为计算集群。
AI计算需要的网络与传统的以太网不一样,它对信号的质量要求非常高,要求做到无损,如此才可以做到硬件上极低的延迟。所以,NVLink与InfiniBand,其技术门槛丝毫不亚于GPU设计。

scaleX万卡超集群由16个曙光scaleX640超节点通过scaleFabric高速网络互连而成,可实现10240块AI加速卡部署,总算力规模超5EFlops。作为世界首个单机柜级640卡超节点,scaleX640采用超高密度刀片、浸没相变液冷等技术,将单机柜算力密度提升20倍,PUE值低至1.04。
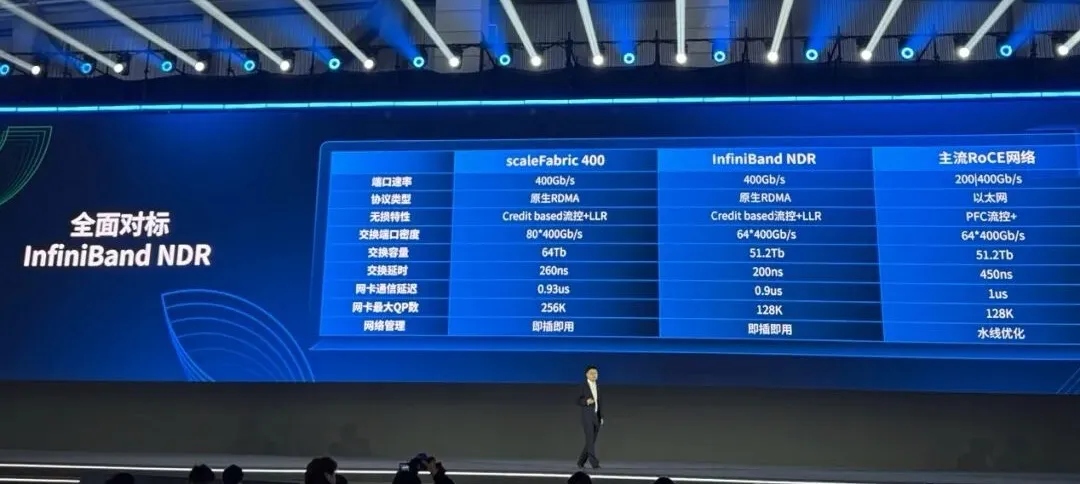
特别值得关注的是曙光scaleFabric网络,其是基于国内首款400G 类InfiniBand的原生RDMA网卡与交换芯片,可实现400Gb/s超高带宽、低于1微秒端侧通信延迟,超节点间的通信性能达到业内领先水平,充分释放万卡超集群算力,并可将超集群规模轻松扩展至10 万卡以上,相比传统IB网络提升2.33倍,同时网络总体成本降低 30%。
曙光scaleFabric网络与scaleX万卡超集群实现的技术跃迁程度,用形象描述会比数据描述更容易理解:要是用原本的技术搭建万卡集群,HAIC 2025的半个展馆都不够。而现在却可以放置在门口,其计算密度是数量级上的差距。
“我们这一代的产品,从目前的规格指标和实测的指标稳定性来说,完全可说实现全行业领先。”
中科曙光高级副总裁李斌介绍,scaleX万卡超集群的部分技术与能力,已超越英伟达研发路线图的2027年NVL576里程节点。
更让人佩服的是,scaleX万卡超集群连一些非核心但对运维很重要的技术,比如让数据传输更稳定的112G SerDes关键部件,还有万一网络出问题也能很快恢复正常的技术——通过物理集群数字孪生,实现故障定位、修复等全流程可视化智能管理——都一次性搞定了,补表现出了十分全面的技术优势。

中美AI产业分道扬镳的第二个层面,表现的更为明显,那就是中国拥有从不同数量级参数的大模型层,到应用层的蓬勃生态,背后则是中国各行各业产业升级的迫切需求。
也就是说,除了AI算力的提升之外,国内产业还有强烈的生态融合需求。
令行业惊喜的是,scaleX万卡超集群一出场就自带开放生态雏形。
在HAIC 2025上,曙光scaleX万卡超集群系统的发布环节,不仅发布了打破异构算力“存算传”瓶颈的技术创新,而且直接发布一个开放生态的雏形——兼容市面上所有智算及超算应用场景,应用可实现无感迁移。
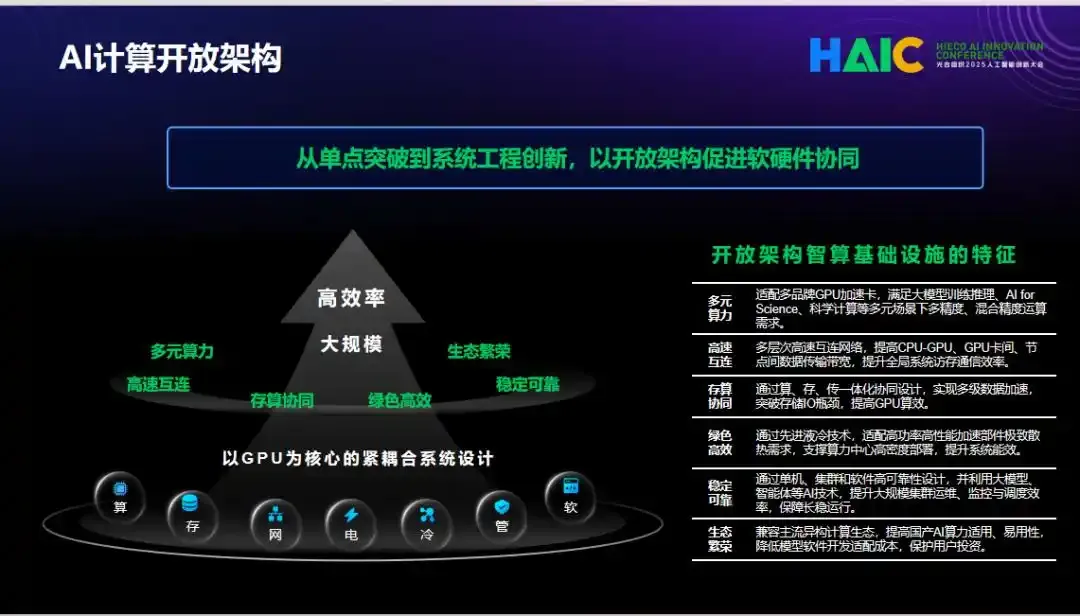
作为 “AI计算开放架构”最新重磅成果,scaleX万卡超集群实现400+主流大模型、世界模型等适配优化。在实际应用中,该超集群可覆盖大模型训练、金融风控、地质能源勘探及科学智能等多元场景。
随着scaleX万卡超集群的落地,中国AI产业不再局限于追赶硬件性能,而是转向构建开放、协同、可持续的生态体系。这一转变,正呼应了光合组织“智算无界,光合共生”的愿景。