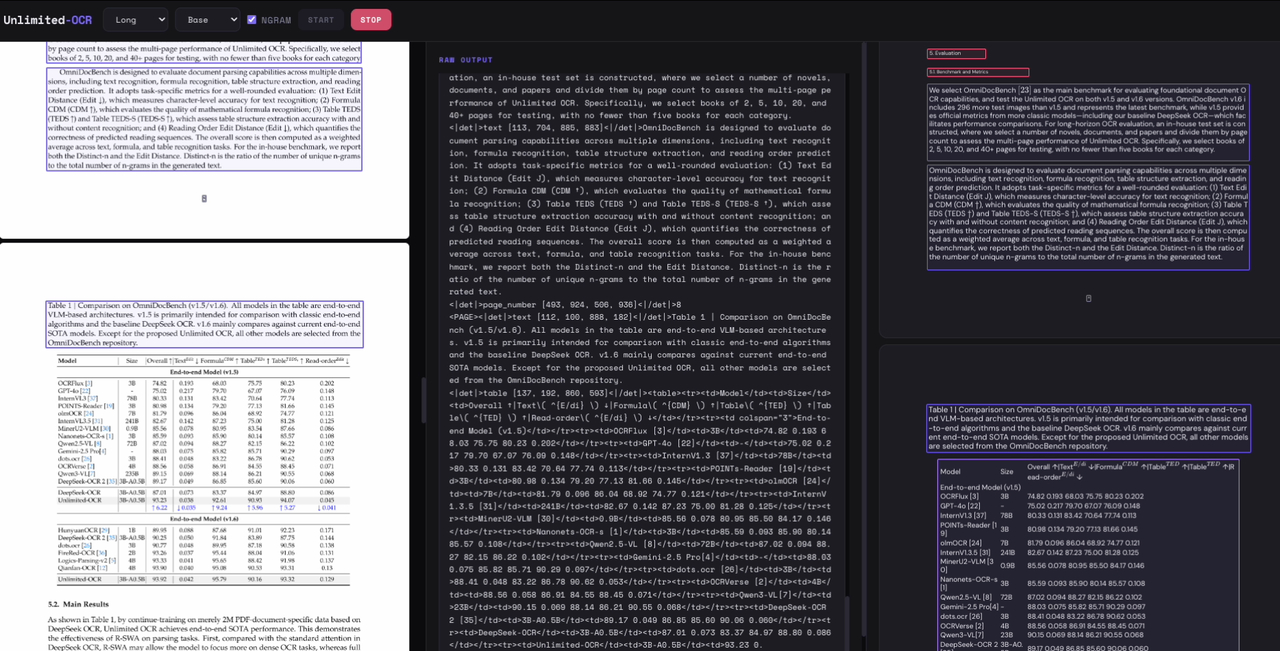
这两天,我看到百度开源了一个叫 Unlimited OCR 的模型。
它可以模拟人类抄书的过程,一次前向推理就能转录几十页文档,不用再一页一页地循环处理。
这个模型在技术层面有非常大的突破,但技术细节咱们放到后面聊。
我比较关注的,是这份技术报告的作者名单。
1
Unlimited OCR 一共列了三位核心贡献者:Youyang Yin,Huanhuan Liu(项目负责人),还有一位标注为技术总监的 YY。
前两个人都用了全名,唯独这位技术总监,只留了两个字母。
这就很耐人寻味了。
一篇正式的技术报告,贡献者栏是你亮学术身份的地方,别人都亮了全名,一个技术总监反而藏起来,图什么?
我们再倒回去看另一件事。
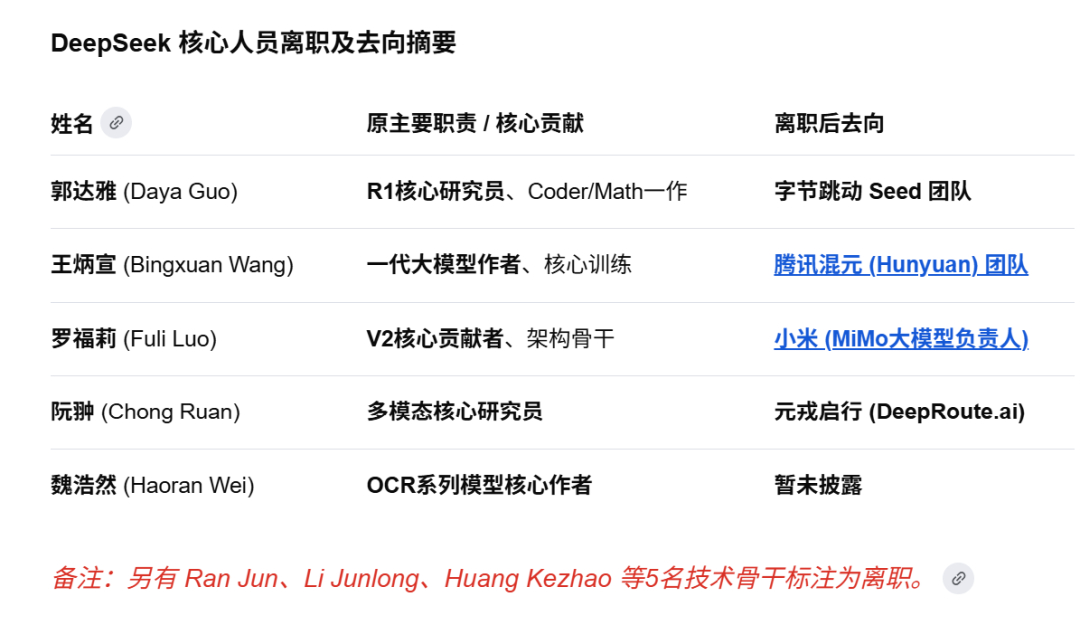
4月24号,DeepSeek 发了 V4 的技术报告,将近60页,末尾附了一份差不多300人的贡献者名单。
创始人梁文锋和每一个研究员、工程师排在一起,按字母排序。但有10个名字旁边标了一个小星号,意思是已离职。
后来媒体陆续扒出了这些人的去向,王炳宣去了腾讯,罗福莉被雷军千万年薪挖到小米做 MiMo 大模型负责人,郭达雅入职字节 Seed 团队,阮翀去了元戎启行做首席科学家。
竞争对手开出的薪资是 DeepSeek 的两到三倍,部分甚至给了八位数总包。
但有一个人的去向始终没有披露——魏浩然。
这位是DeepSeek OCR 系列的核心作者,今年春节前后离职,去向未公开。
然后 Unlimited OCR 出现了。
2
我之所以把这两件事放在一起讲,是因为我接连发现了几条线索。
首先是致谢部分。
论文本身写得克制,但你去翻 GitHub 仓库的致谢栏,排在最前面的是 DeepSeek-OCR 和 DeepSeek-OCR-2,而致谢排序反映出的就是实际影响的权重。
然后我们看一下技术路线。
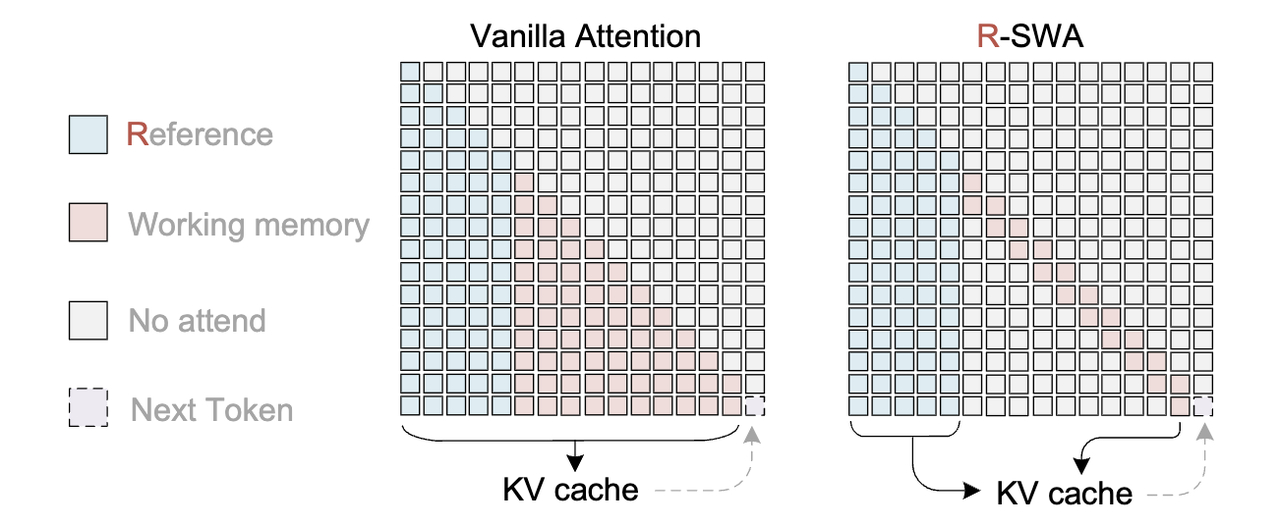
Unlimited OCR 的核心创新叫 R-SWA,全称是参考滑动窗口注意力。
滑动窗口注意力大家可能听过,就是模型在生成内容的时候,只看前面固定数量的token,比如128个。但问题很明显,如果窗口之外有重要的视觉信息,模型就看不到了。
R-SWA的做法是,在输出侧保留滑动窗口,只看前面128个输出token。
但同时,每一个token都能看到所有的参考token,也就是完整的图像信息。
也就是说,模型在生成文字的时候,随时都能回头看原图,但不需要反复回顾自己已经写过的所有内容。
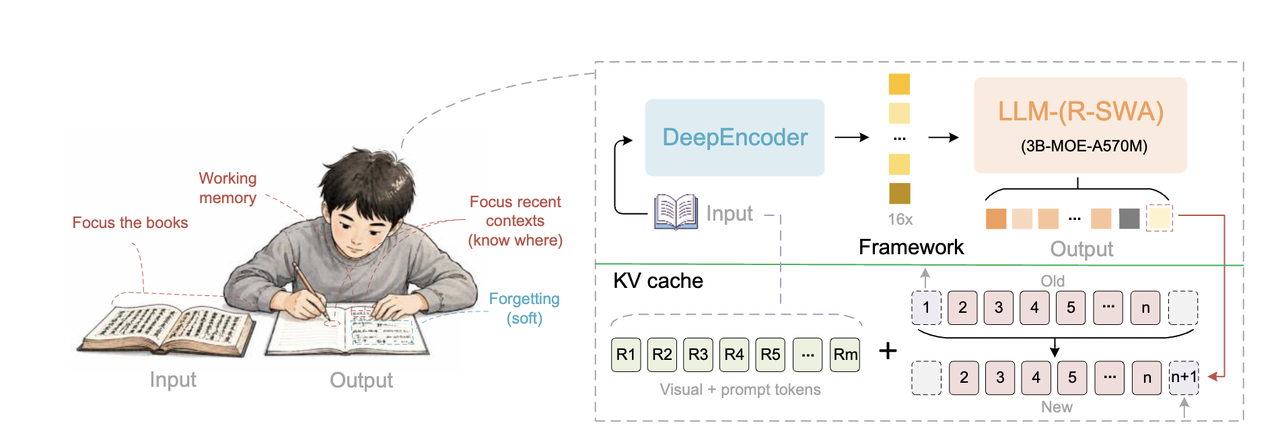
这跟人类抄书的注意力模式是不是特别像?
人抄书的时候,注意力同时锚定在三个地方:一是原书上正在看的那几行,二是自己刚刚写下的几个字,三是接下来要写的下一个字。
你不会把前面抄过的所有内容都背下来,但你也不会完全忘掉,而是会进行一种“软遗忘”。
旧的信息慢慢淡出,但不会突然消失,近期的上下文一直在帮你定位当前进度。
Unlimited OCR要做的,就是让模型也具备这种能力。
而且这里面还有一个很精妙的设计:视觉token被排除在状态转移之外,不参与循环更新。
因为如果视觉特征也跟着不断传递更新,信息会在传递过程中逐渐模糊,R-SWA把视觉信息固定住,保持原始精度,只让输出侧的文字信息在窗口内流动。
但这个机制要发挥作用,需要配合一个高压缩率的视觉编码器。
而报告里用的编码器,恰好就是 DeepEncoder,而这个编码器最早就是在 DeepSeek OCR 里被提出来的。
Unlimited OCR 不仅用了它,而且整合得非常自然,像是对原始设计思路的延续和进化。
还有行文风格,这一点可能有点主观,因为Unlimited OCR 的技术报告读起来不像传统大厂论文。
传统大厂的论文倾向于先摆结果再补方法,写得四平八稳。
但这篇开头就讲人类怎么抄书,从工作记忆和认知科学的角度切入,然后才引出技术方案,结尾还放了一句话,说 R-SWA 是通用的长程解析机制,OCR 只是第一站。
这种叙事驱动的写法,故事感强,想法激进,此前能把技术报告写出这种味道的团队,印象里也就 DeepSeek 一家。
还有报告里提到 DeepSeek OCR 的段落,语气不太像是在对标一个竞品,更像是在对自己之前的方案做反思和迭代。
3
我把这几条线索串起来,你大概就能理解为什么 AI 圈最近都在猜 YY 是谁了。
国内做 OCR 的圈子其实不大,DeepSeek OCR 从一代到二代,核心作者始终就那么几个人,同一支小团队,从零开始做起来的。
能够对 DeepSeek OCR 的架构有这种程度的理解,又能在此基础上做出 R-SWA 这个级别的突破,再加上行文风格的高度一致,符合条件的人一只手都数得过来。
当然,以上全是我基于公开信息的推测。
YY 到底是谁,目前没有任何官方确认,我也不会下定论。
但比较有意思的是,它折射出的是整个行业正在发生的一个趋势。
过去一年,中国 AI 人才的流动烈度远超此前任何时期。中国 AI 核心技术岗缺口超过80万人,顶尖人才的年薪已经突破300万,跳槽涨幅集中在20%到30%,关键岗位企业还愿意再往上加。
DeepSeek 不到200人的团队,半年走了5个核心,覆盖四条主线。
但硬币的另一面是:人才流动本身也在创造价值。
每一个人带走的不只是简历上几行字,而是从零到一搭建过一条技术线的全部积累,包括那些论文里写不出来的工程直觉。
如果 Unlimited OCR 的背后确实站着一位从 DeepSeek OCR 一路走过来的人,那这篇报告可能就代表了:一个研究者带着自己对问题的深层理解,换了一个环境,碰上了不同的资源和产品方向,于是做出了比上一份工作更大胆的尝试。
而百度最近在 AI 方面释放出的信号,从技术报告的写法到开源的节奏,再到这次团队构成透露出的信息,都让人感觉内部的氛围在发生变化。
YY 是谁?也许过不了多久,答案很快会浮出水面。