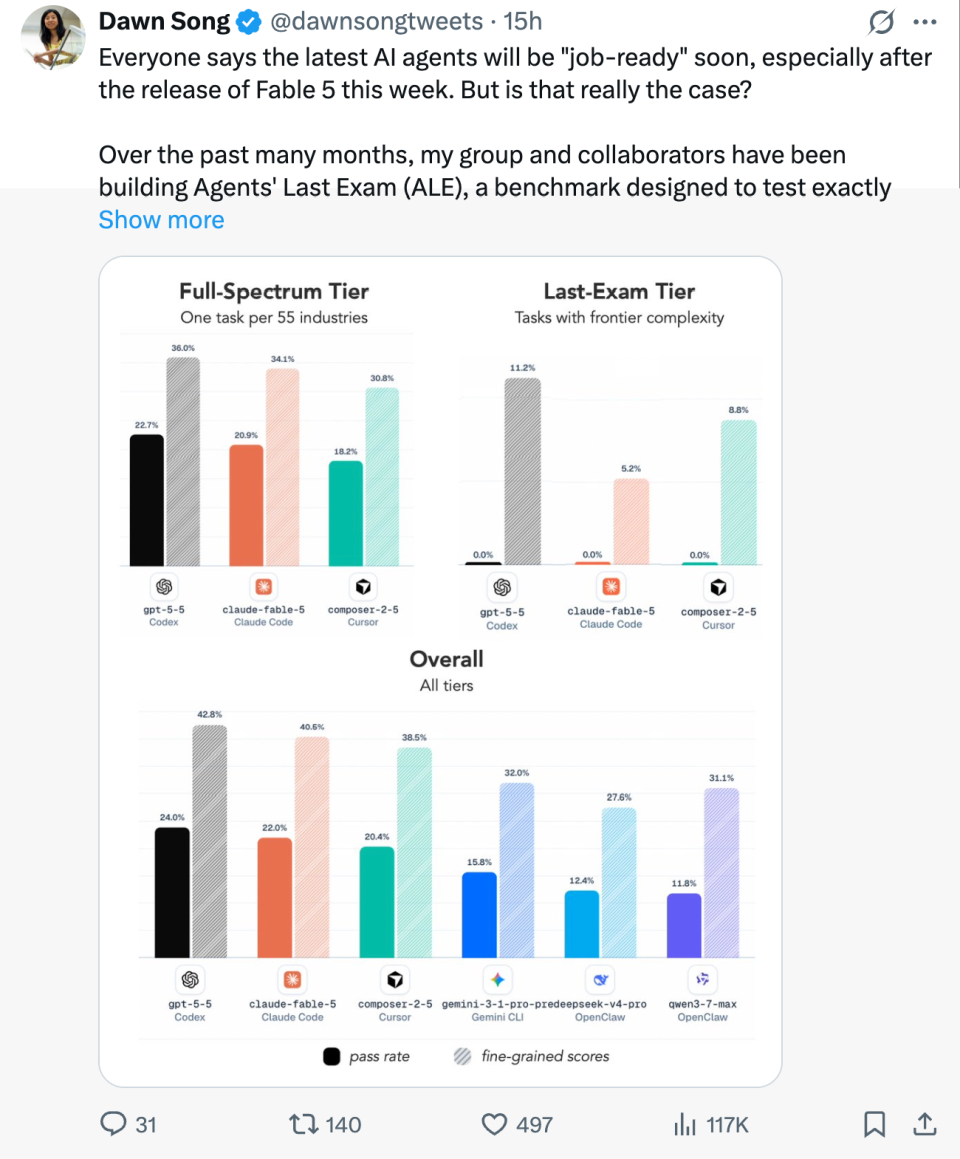
伯克利发布了一个新的AI能力基准,叫Agents' Last Exam。名字取得有点悲壮——"智能体们的终极大考"。1500多道题,全部来自55个真实职业的工作任务,按难度分层。
结果:在最困难的那一层,所有模型全部0%。包括Fable 5、GPT-5.5这些公认最强的选手。
55个真实的职业岗位,从财务分析师到医疗编码员到建筑监理,每一题都是真人每天在做的事。最难的题AI做不出来,这谁都预料得到。所以这个基准的设计逻辑不是说"AI能不能替代人类"这种抽象命题,而是"AI能不能完成一项具体的工作任务"。能做到的就统计,做不到的就标零。
过去几个月我们看到的叙事是两个极端——一边是Fable 5在SWE-Bench上秒杀一切、腾讯说大部分代码AI写、对冲基金用AI替代分析师;另一边是Anthropic喊危险、学生毕业典礼嘘AI。两边都抓眼但都太极端了。
ALE这个0%意味着:在需要跨领域知识、长链条推理和不确定性应对的真实工作任务上,最强AI目前确实还不够。