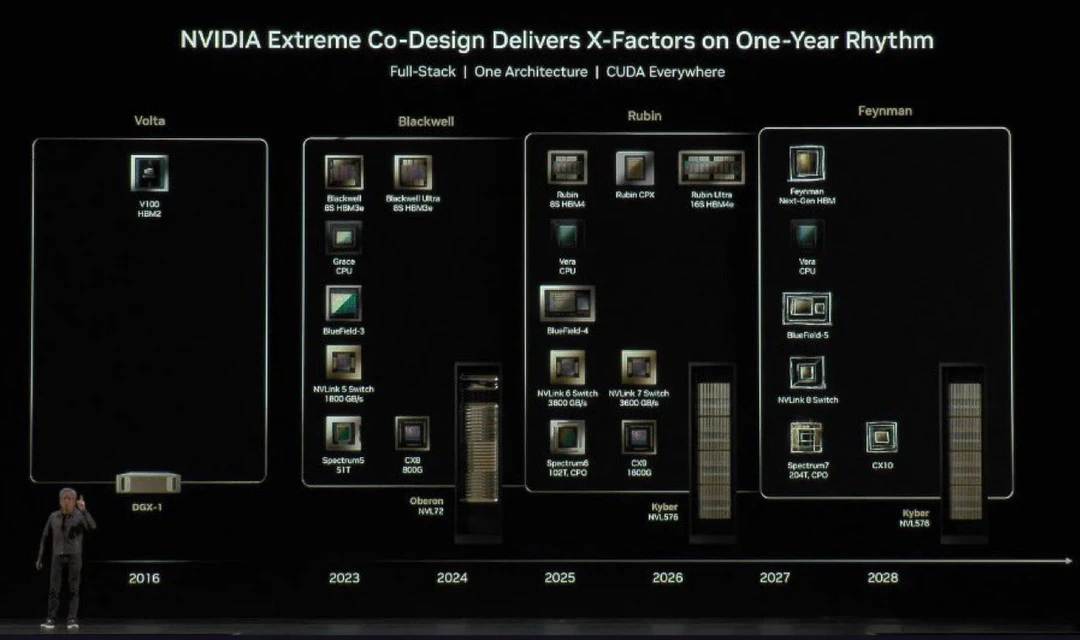
这张图展示的是英伟达未来算力平台路线图,主题为“极致协同设计,每年一代升级”。核心理念是全栈架构统一、单一体系设计,以及CUDA生态全面覆盖。
⚙️Volta时代(2016)
代表产品是V100,搭配HBM2高带宽内存,属于早期AI计算基础设施阶段。当时系统以DGX-1为核心,主要用于深度学习训练起步阶段。
🚀Blackwell架构(2023-2024)
进入现代AI算力爆发期,包含Blackwell GPU、升级版HBM3e内存,同时配套Grace CPU与BlueField-3数据处理单元。网络方面使用NVLink 5交换与高速互联,构建完整算力系统。
🔬Rubin架构(2025-2026)
进一步升级为更高带宽与更强集成度,包括Rubin GPU系列以及更先进的HBM4内存。CPU升级为Vera,数据处理单元升级至BlueField-4,并引入更高速NVLink 6与7,实现更大规模算力集群。
🌌Feynman架构(2027-2028)
代表下一代终极算力平台,继续提升内存带宽与系统协同能力。配套BlueField-5与更高规格互联架构,同时引入CPO(光电共封装)技术,进一步降低延迟并提升能效。
🔗核心技术逻辑
英伟达的竞争力不只是GPU本身,而是“整套系统”。从芯片、CPU、网络、内存到软件生态,全部统一设计,使算力不只是单点性能,而是整体效率最大化。
📈节奏优势
图中最关键的信息是“一年一代”。这意味着英伟达正在把芯片行业从传统两三年周期,压缩到类似软件迭代的节奏,极大拉开与竞争对手的差距。
🌍产业意义
这种路线不仅影响AI行业,也在重塑整个科技产业链。云计算公司、AI企业甚至国家级算力布局,都在围绕英伟达的节奏进行规划。
🔍趋势洞察
未来竞争不再只是芯片性能,而是谁能提供完整算力平台。英伟达已经从芯片公司,转变为AI基础设施供应商。
💡结论
这张图揭示了一个本质变化:英伟达正在定义AI时代的基础规则,而不是单纯参与竞争。