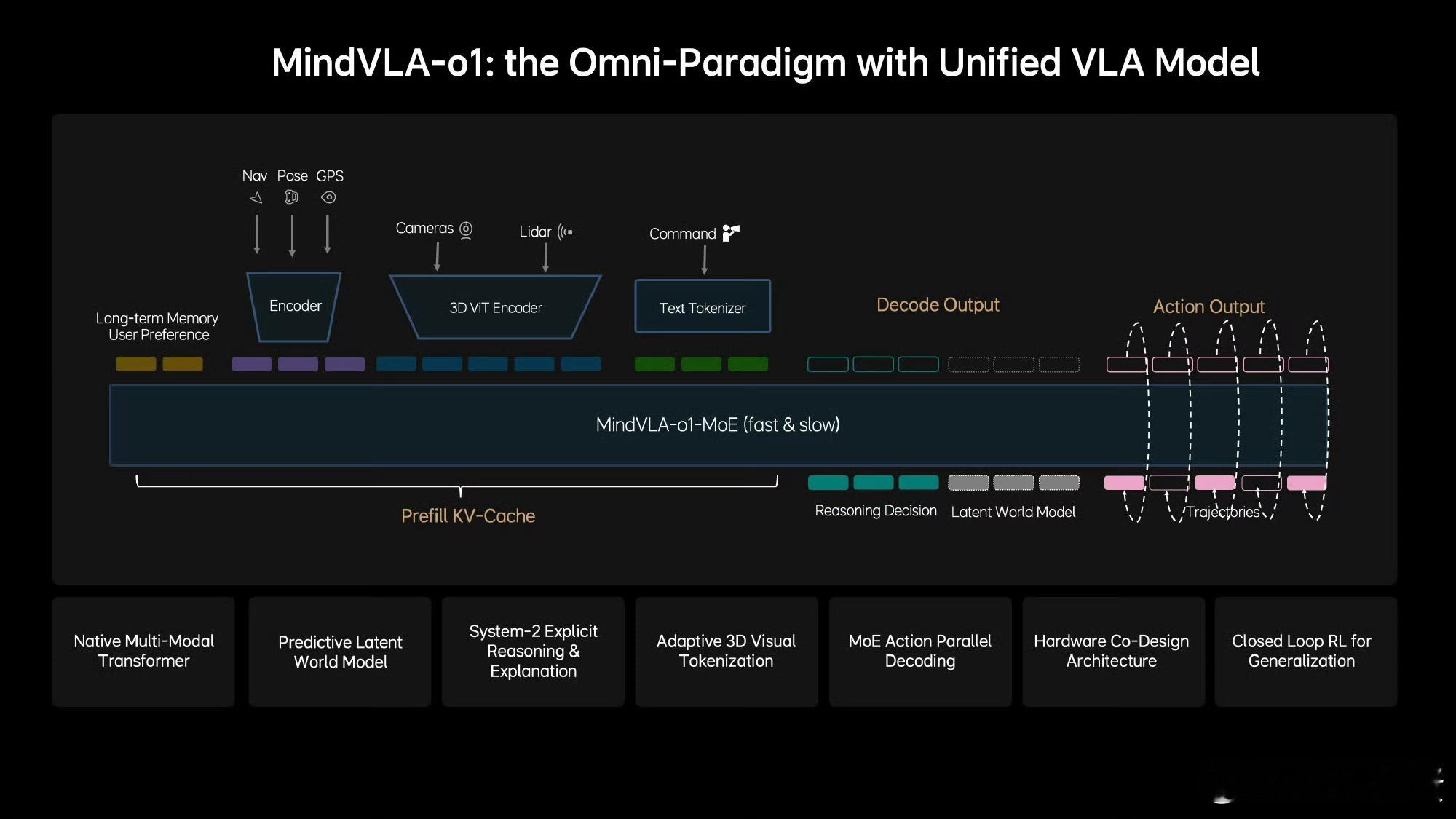
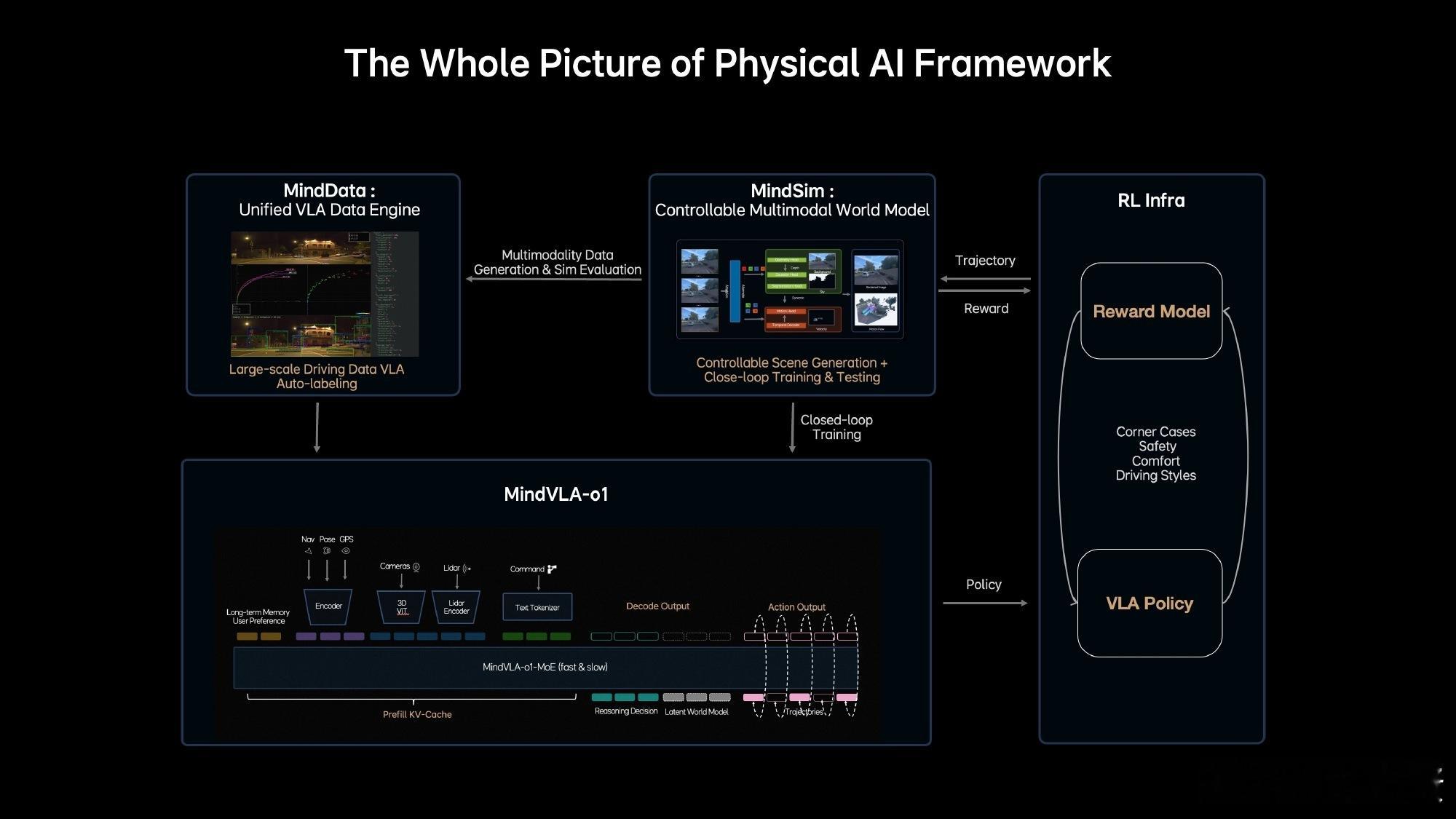
理想在GTC上发布了MindVLA-o1,让车真正拥有了三维空间的理解力,同一套模型既能开车也能操控机器人,说明自动驾驶确实只是物理AI的一个起点。
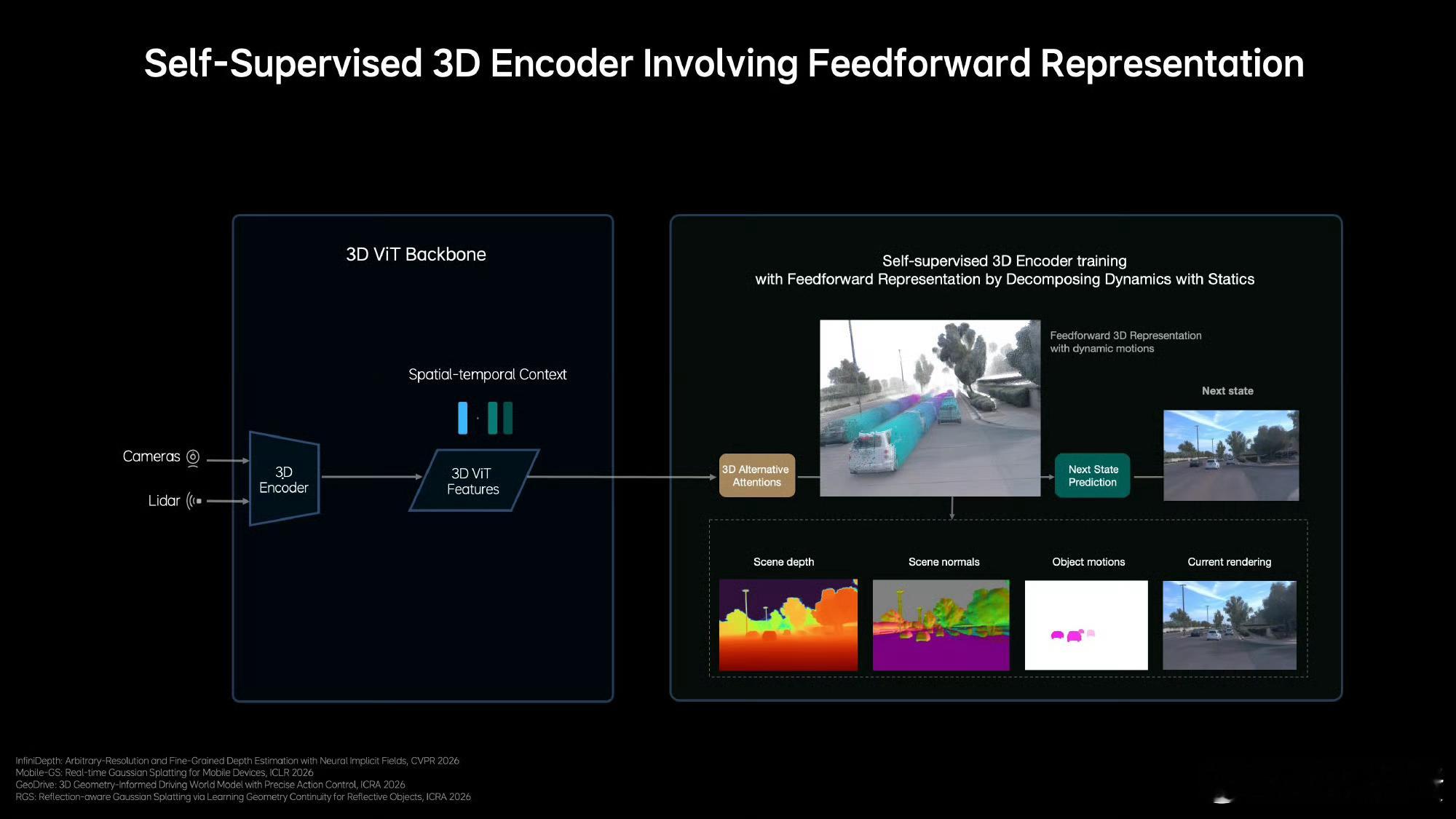
我理解这次的关键突破在于对3D空间的认知方式。传统的鸟瞰视图只有2D信息,占用网络虽然是3D的但缺少语义,相当于知道这里有东西却不知道是什么。
MindVLA-o1就能通过视频流直接还原三维空间的位置、点云和语义了,我觉得这种对物理世界的理解能力,才谈得上真正的智能。
李想拿小孩接球做类比很形象,咱们小时候接不住球,一次次尝试后大脑学会了预判速度和距离。车也一样,关键不是堆更多传感器,而是让模型在一次次训练中形成对三维空间的直觉。这种学习路径,更接近智能的本质。
想到以后的车能像人一样理解空间关系,不是机械地识别障碍物,而是真正看懂周围在发生什么,还挺让人感慨的。技术进步有时候就是这样,在不知不觉就跨过了一道道坎,已经在期待未来的发展还有什么惊喜了理想全能辅助驾驶来了