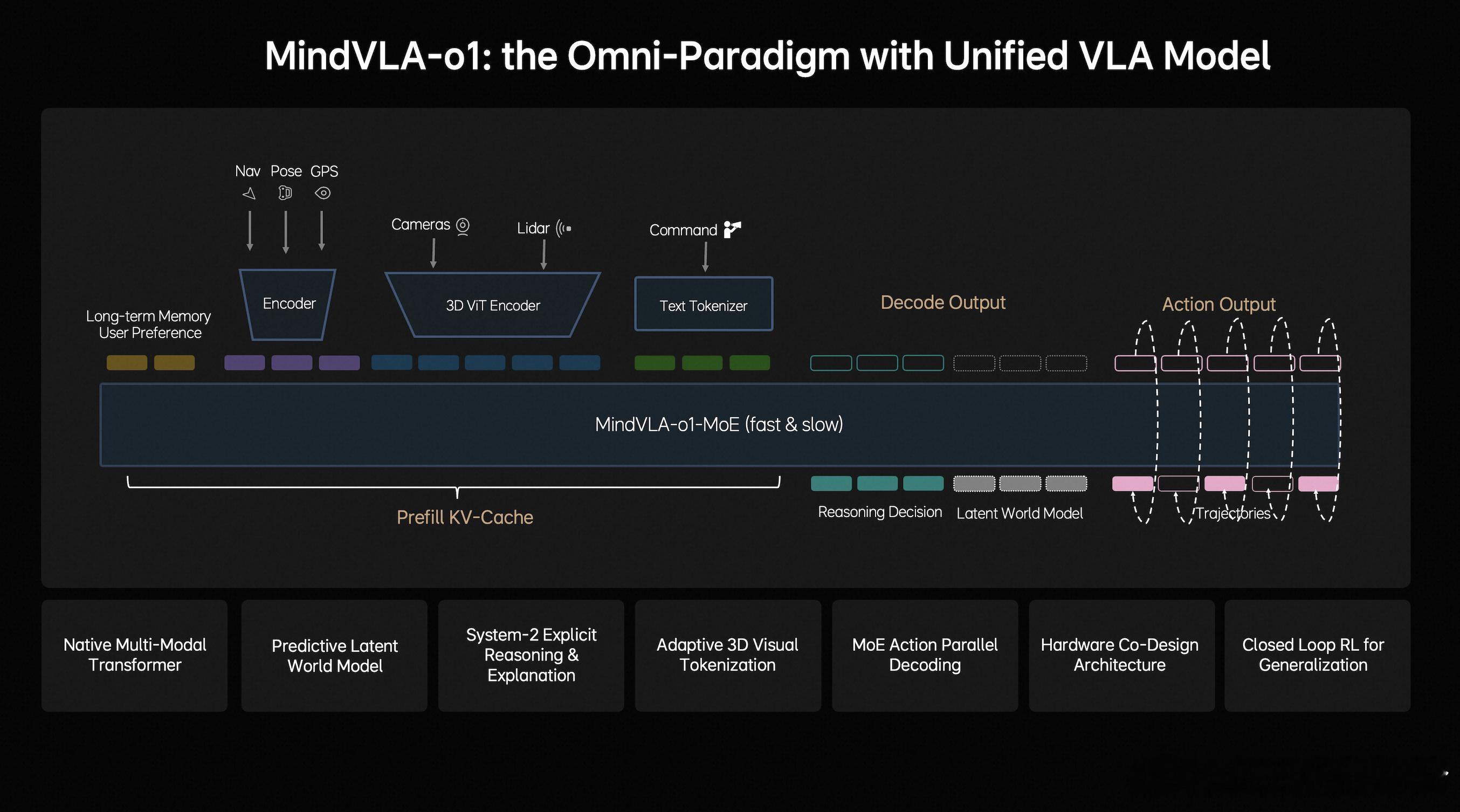
理想 3月17日,理想汽车基座模型负责人詹锟出席NVIDIA GTC 2026,发表主题演讲《MindVLA-o1:开启全能范式——下一代统一视觉-语言-动作自动驾驶大模型探索》,发布下一代自动驾驶基础模型MindVLA-o1。MindVLA-o1通过五大技术创新,构建了面向物理世界智能的自动驾驶基础模型,让自动驾驶看得更远、想得更深、行得更稳、进化更快、部署更高效。詹锟表示:“当我们把视觉、语言和行动统一到一个模型中时,它已不再只是自动驾驶模型,而是在逐渐演化为面向物理世界的通用智能体。基于同一套VLA模型,不仅可以控制车辆,也能够扩展到机器人。因此,自动驾驶只是物理AI的起点,未来这类基础模型将驱动新的具身智能范式。”