2026年3月17日,理想汽车基座模型负责人詹锟出席NVIDIA GTC 2026,发表主题演讲《MindVLA-o1:开启全能范式——下一代统一视觉-语言-动作自动驾驶大模型探索》,发布了理想汽车的下一代自动驾驶基础模型MindVLA-o1。这也标志着其自动驾驶技术从“端到端”向“具身智能”的重大跨越。简单来说,理想正在为车打造一个像人一样能看、能思考、能行动的“数字大脑”。这是将车转向具身智能的重要的一步,自己做大模型就是升级迭代快。
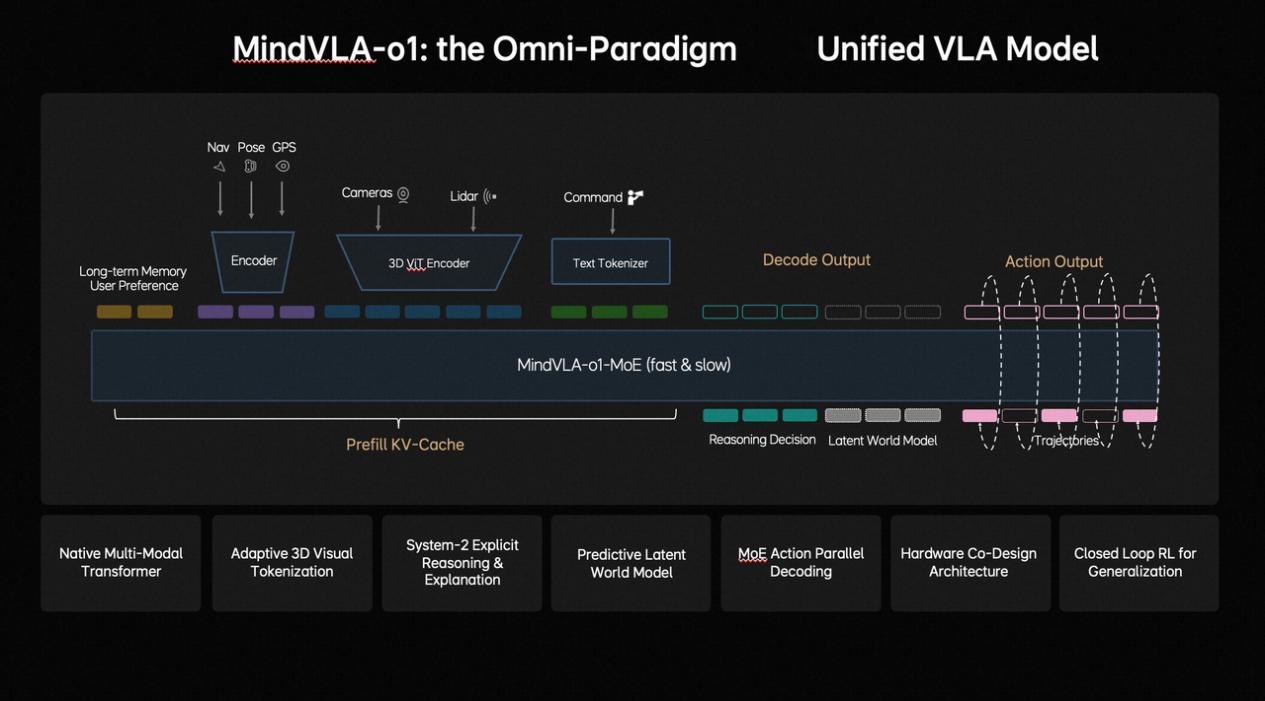
该模型的核心突破可以概括为以下五个维度:
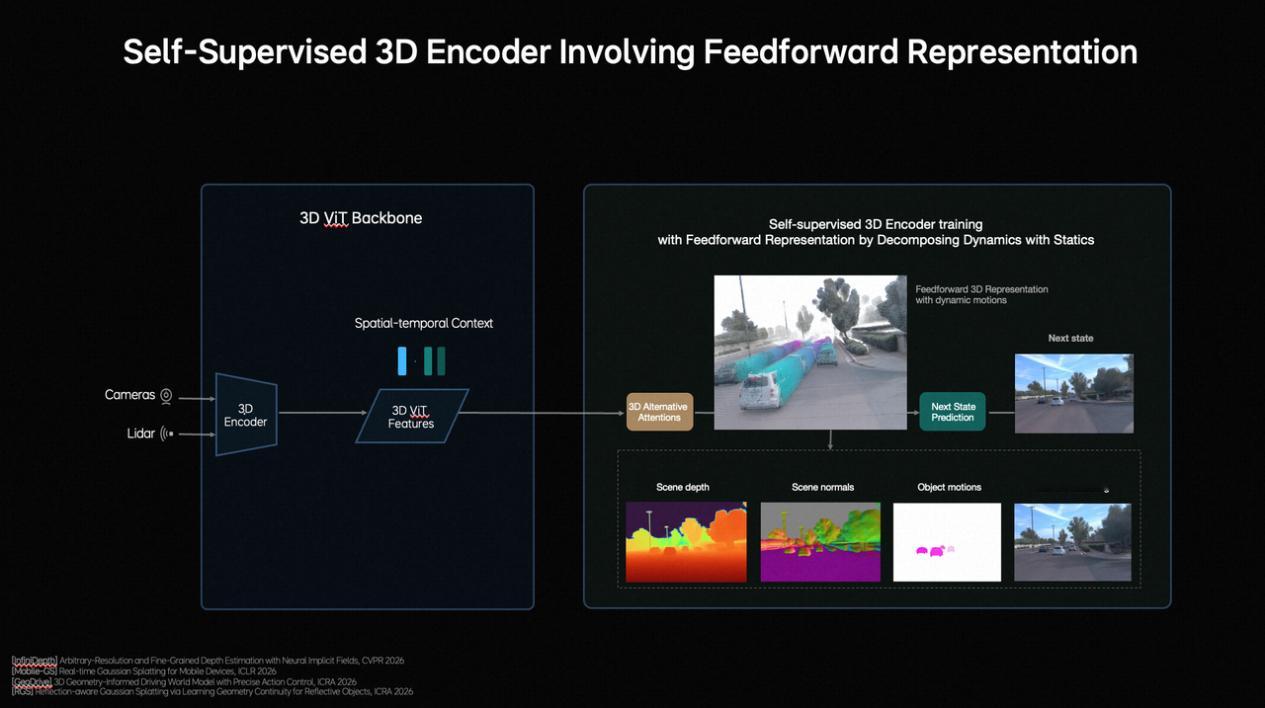
●看得更准(3D空间理解): 以前的系统更多是在处理平面图像,而 MindVLA-o1 结合了摄像头和激光雷达,通过 3D 编码器让车能够像人类一样感知物体的深浅、距离和运动状态,真正理解三维物理空间。
●想得更深(多模态思考): 它是首个能“脑补”未来的模型。通过隐世界模型,它不仅看现在,还能在隐形空间里提前“预演”未来几秒可能发生的场景,从而做出更有预见性的决策。
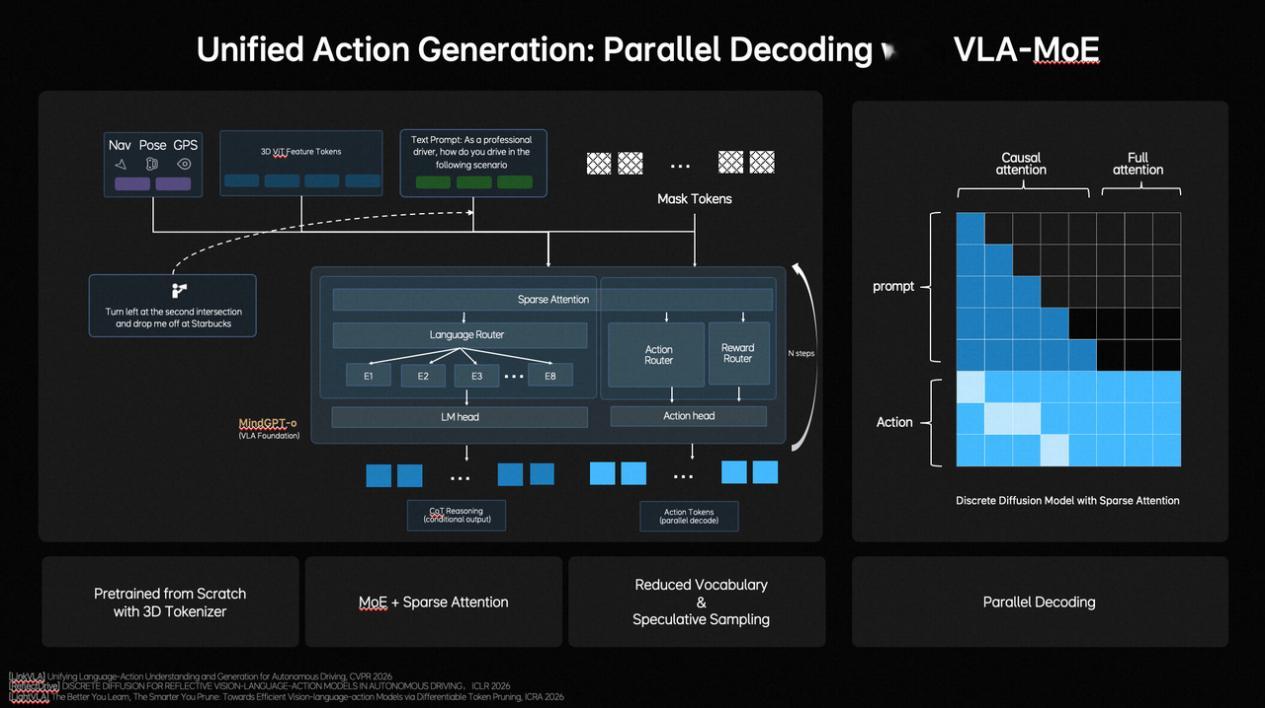
●行得更稳(统一行为生成): 系统采用 VLA-MoE 架构,专门配备了“动作专家”。它能同时生成所有行驶轨迹点,并通过类似“去噪”的优化过程,确保车开得既丝滑又符合物理规律。
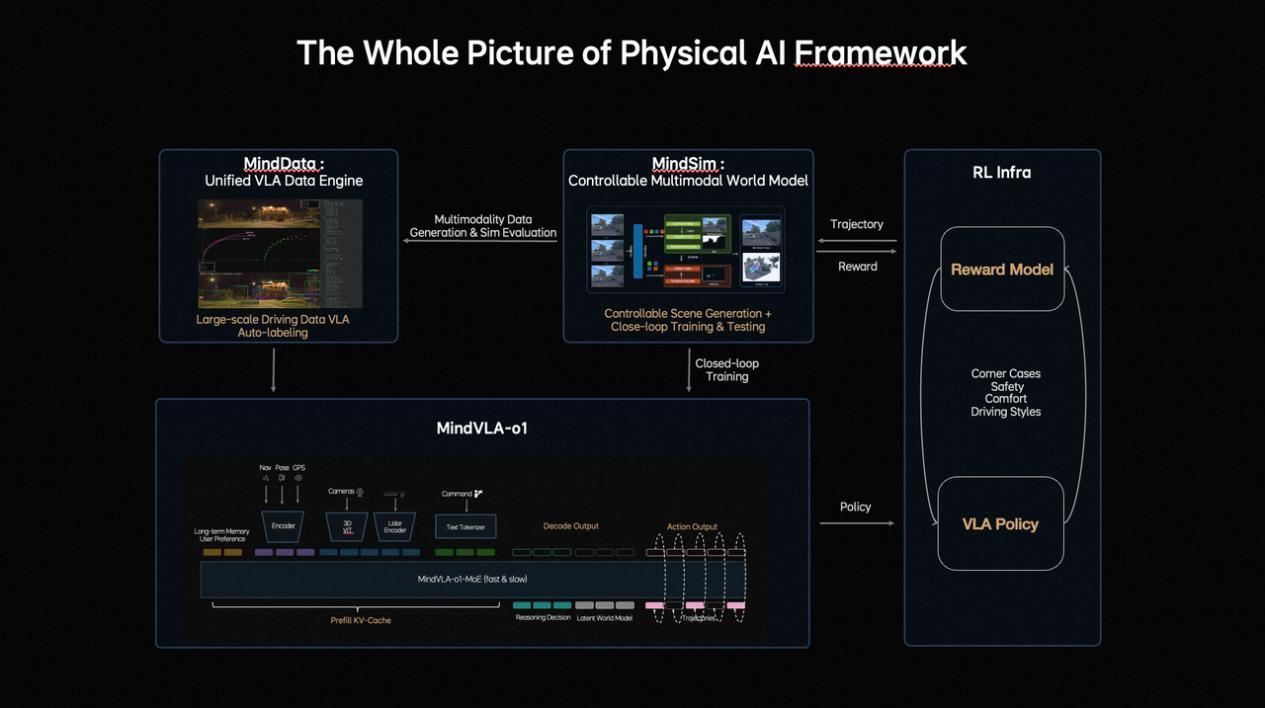
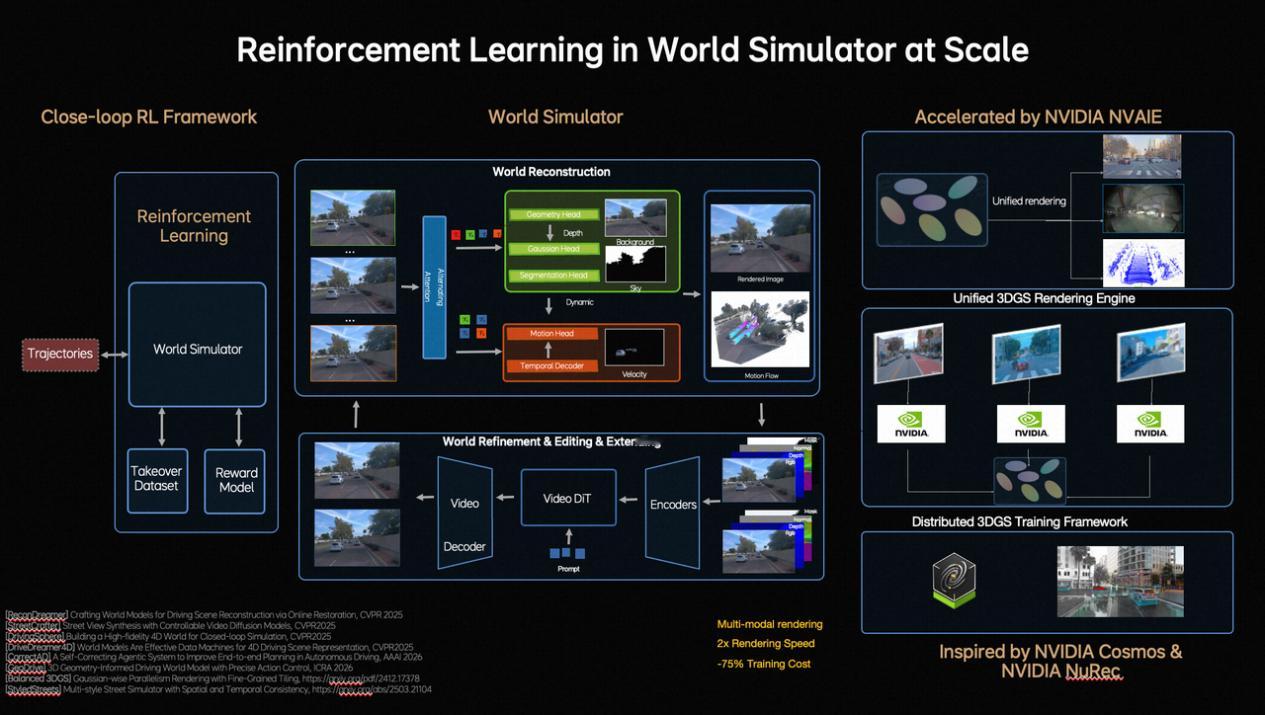
●进化更快(闭环强化学习): 理想构建了一个强大的世界模拟器。模型不仅在马路上学,还能在虚拟世界里进行大规模、高效率的自我练习和策略优化,大大降低了训练成本。
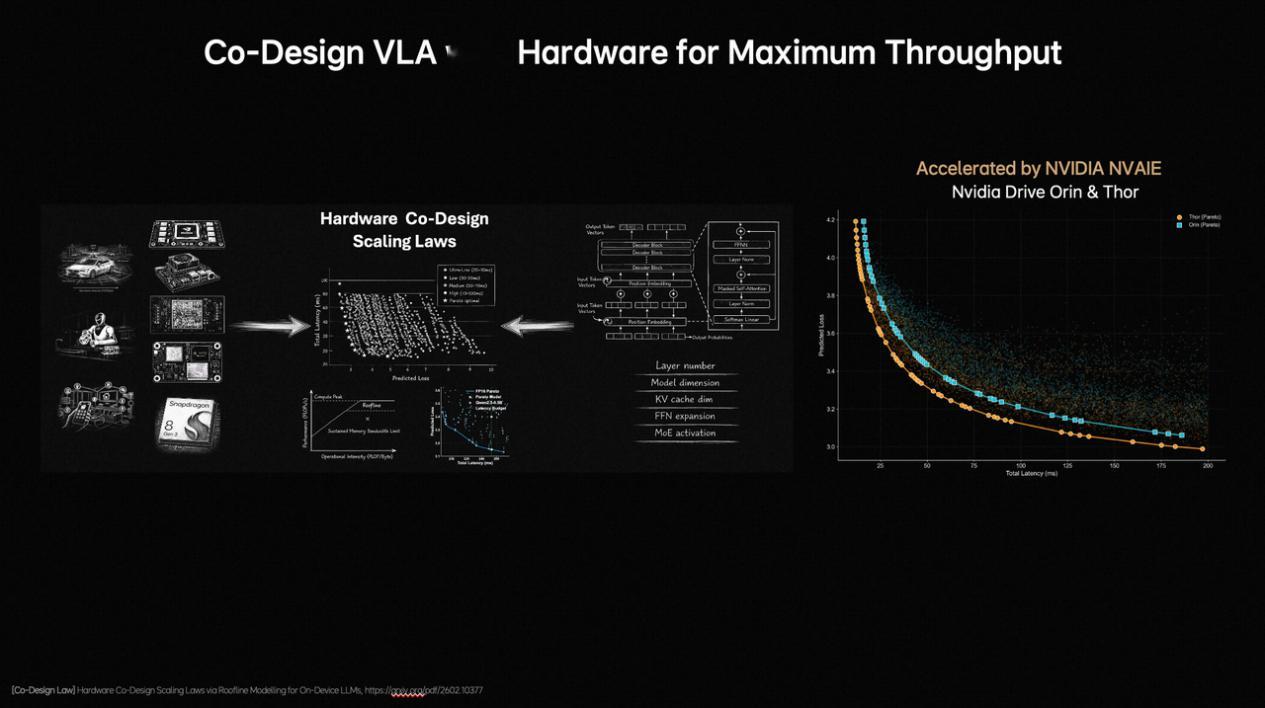
●部署更高效(软硬件协同): 通过研究模型精度与硬件延迟的平衡,理想将架构设计的时间从几个月缩短到几天,让复杂的大模型能更流畅地跑在车端芯片上。
这套框架本质上是将车视作一个“大号机器人”。它不再仅仅是听从规则的工具,而是正在进化成一个能够感知、理解并在复杂物理世界中自主行动的通用智能体。
你想了解这个模型在实际驾驶场景(如城区拥堵或高速避障)中具体是如何表现的吗?挺期待的~理想L9 Livis