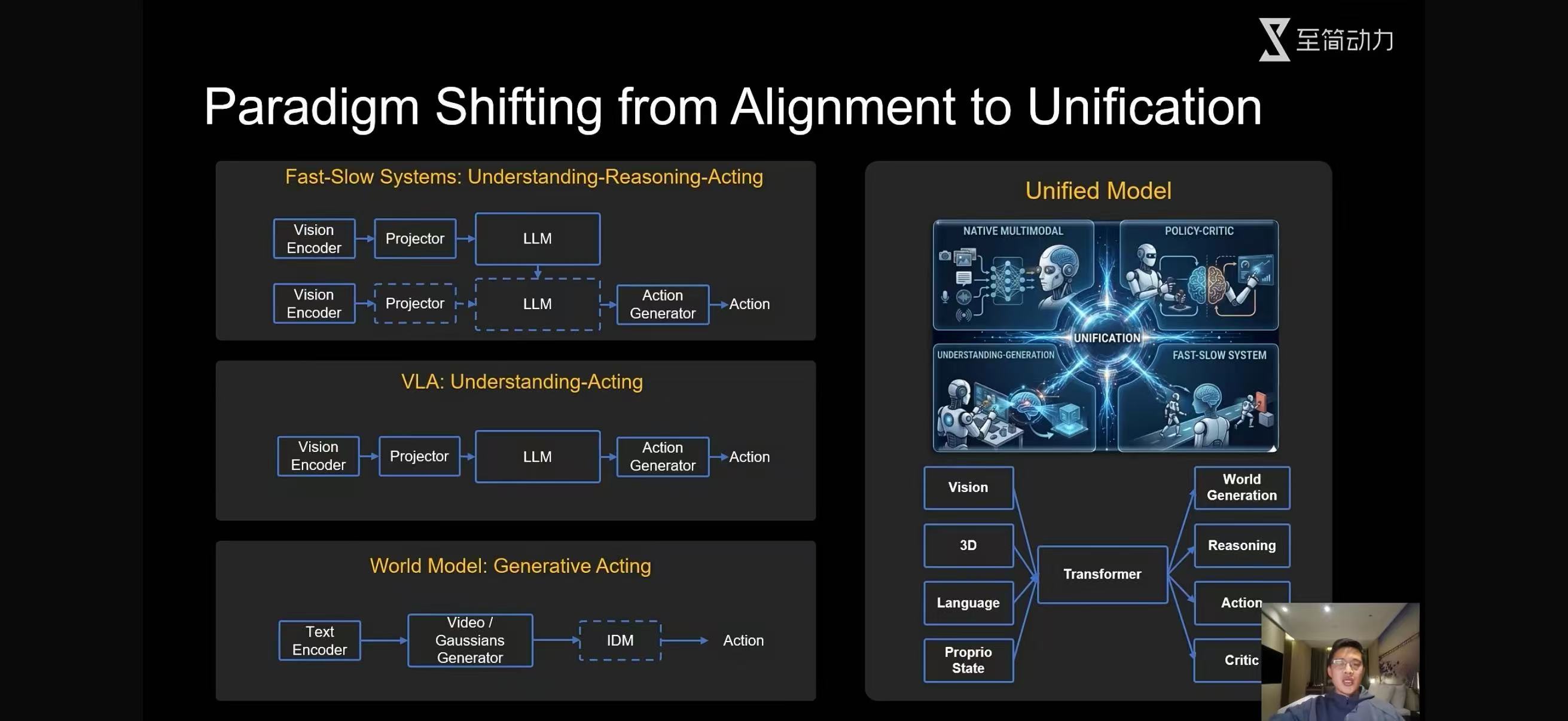
1️⃣Fast-Slow Systems:理解 - 推理 - 行动(Understanding-Reasoning-Acting)核心思想:借鉴人类双系统认知理论(快系统直觉反应、慢系统深度思考),将感知与决策分层。
流程:视觉编码器(Vision Encoder)提取图像特征,通过投影器(Projector)对齐到语言空间。
大语言模型(LLM)分别承担快速感知理解和慢速逻辑推理两个角色。推理结果输入动作生成器(Action Generator),输出最终控制指令。特点:优势:推理能力强,适合复杂场景决策,可解释性高。劣势:模块多、链路长,延迟较高,模块间对齐误差会累积。
2️⃣VLA(Vision-Language-Action):理解 - 行动(Understanding-Acting)核心思想:简化 Fast-Slow 架构,直接将视觉 - 语言 - 动作端到端对齐,是当前主流的具身智能范式。流程:视觉编码器提取环境特征,经投影器映射到 LLM 的嵌入空间。LLM 直接融合视觉与语言信息,输出动作决策。动作生成器将 LLM 输出转换为可执行的控制信号。特点:优势:结构简洁、部署高效,适合端侧实时场景,是当前工业界主流方案。劣势:依赖大规模多模态数据对齐,复杂推理能力弱于 Fast-Slow 系统。
3️⃣World Model:生成式行动(Generative Acting)核心思想:通过构建虚拟世界模型,让智能体在 “脑海” 中预演未来,再基于模拟结果决策。流程:文本编码器输入任务指令,驱动视频 / 3D 高斯生成器(Video/Gaussians Generator)重建环境动态。生成的世界模型输入逆动力学模型(IDM),预测实现目标所需的动作序列。特点:优势:极强的泛化与规划能力,能应对未见过的场景,无需大量真实交互数据。劣势:计算成本极高,世界模型精度直接决定决策可靠性,落地难度大。
🔄 范式演进与统一模型从左到右,技术范式在简化链路、强化端到端能力:Fast-Slow → VLA:弱化显式推理模块,追求实时性与工程可行性。VLA → World Model:从 “感知 - 直接决策” 转向 “模拟 - 规划决策”,更接近人类认知。
而右侧的Unified Model是最终目标:用单一 Transformer 架构,统一视觉、3D、语言、本体状态等多模态输入。输出覆盖世界生成、推理、动作、评判等全能力,实现 “一个模型搞定所有具身任务”,彻底消除模块间的对齐损耗至简动力具身智能