[LG]《Meta-Reinforcement Learning with Self-Reflection for Agentic Search》T Xiao, Y Yuan, H Ivison, H Zhu… [Allen Institute for AI & University of Washington] (2026)
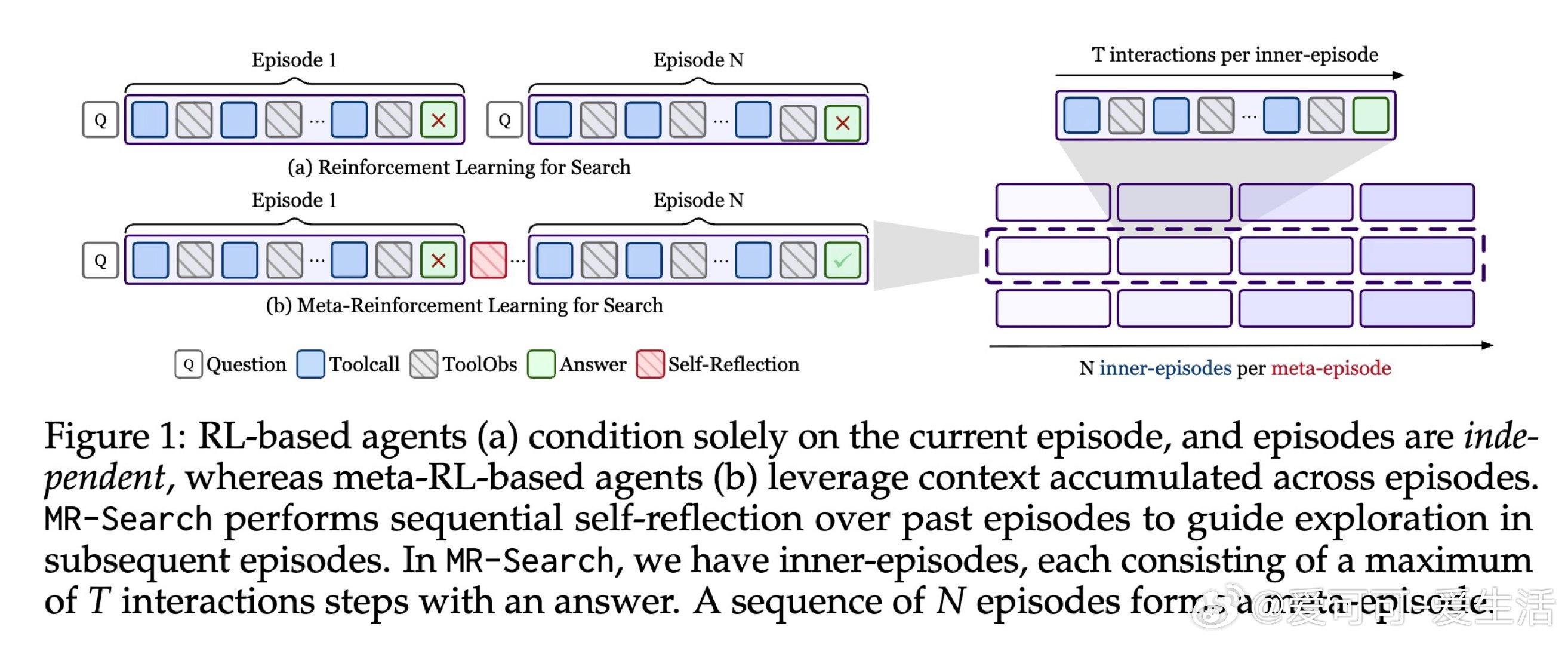
在信息检索型问答任务中,强化学习智能体长期受困于一个结构性缺陷:每条轨迹相互独立,模型只在终点获得稀疏奖励,无从知晓"哪一步搜索走错了"。当任务要求多跳推理时,这一盲区被成倍放大——错误在工具调用链中悄然累积,却无处归因。
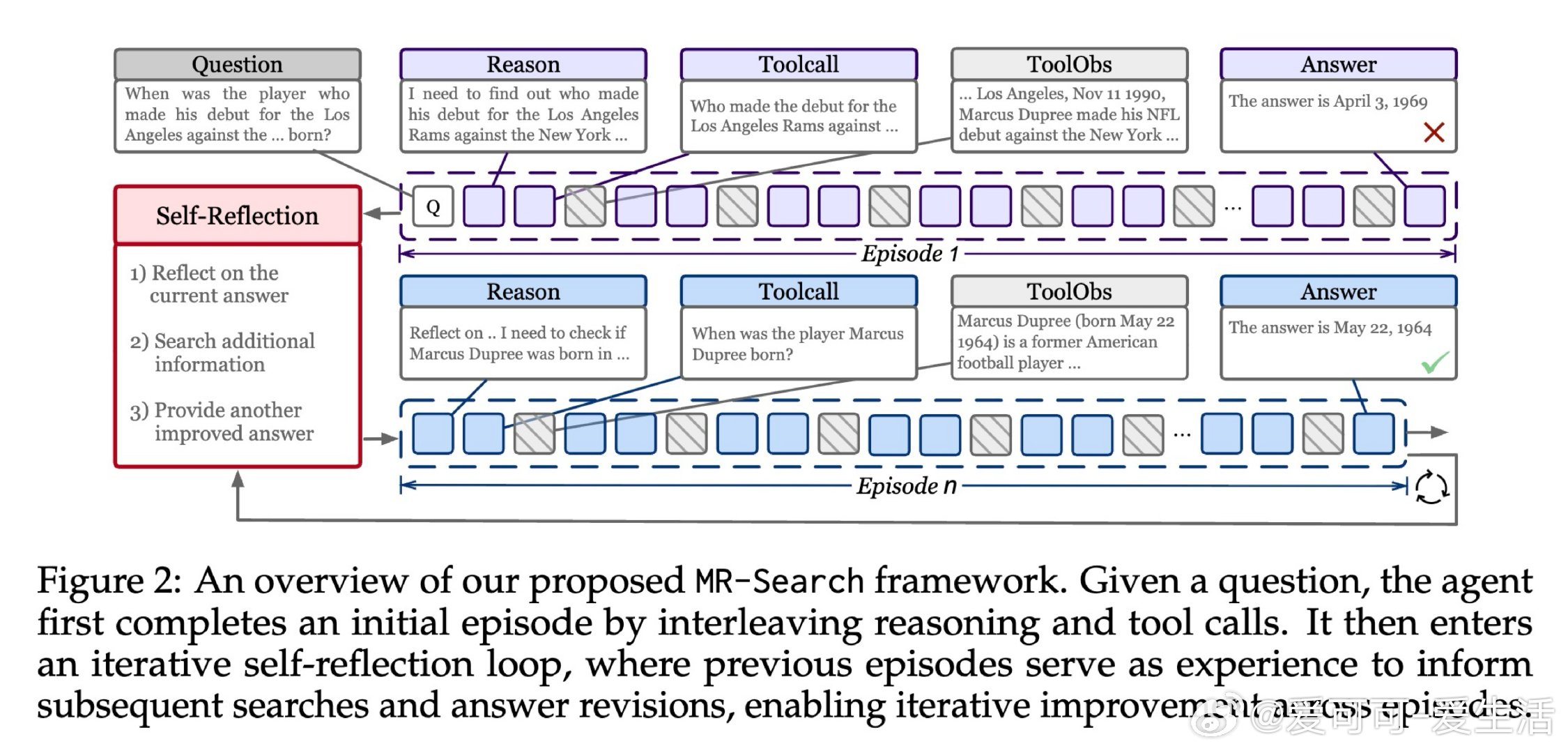
本文的核心洞见是:把"多次独立搜索尝试"重新看作"一个智能体跨越多幕的自我学习过程"。由此,在每幕结束后强制生成显式自我反思、并将其作为下一幕上下文输入这一关键操作,使跨幕探索得以实现;配合回合级折扣优势估计,让每次反思步骤都获得细粒度的信用分配,无需外部奖励模型。
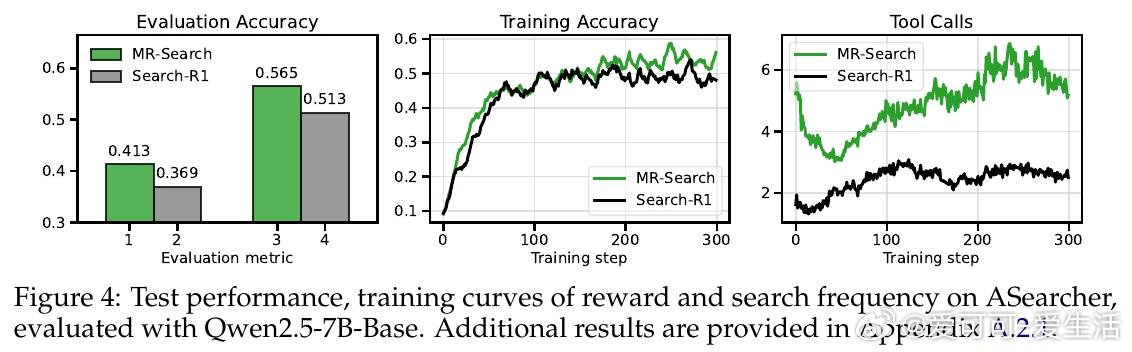
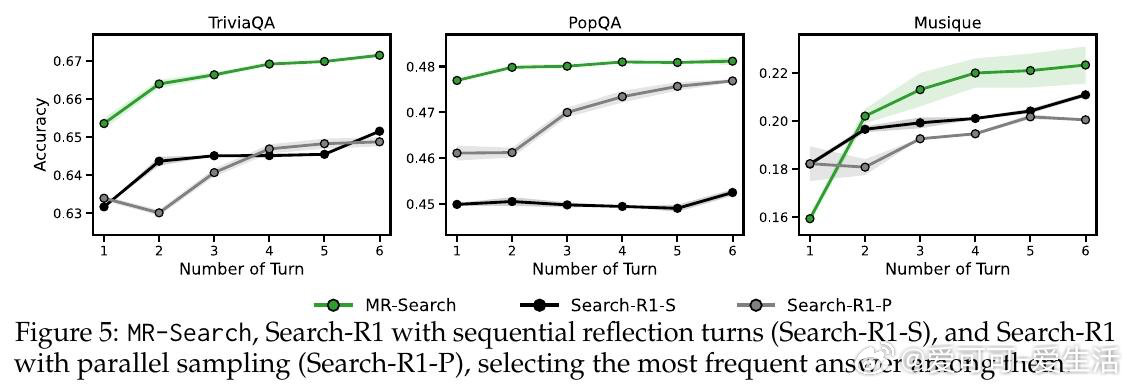
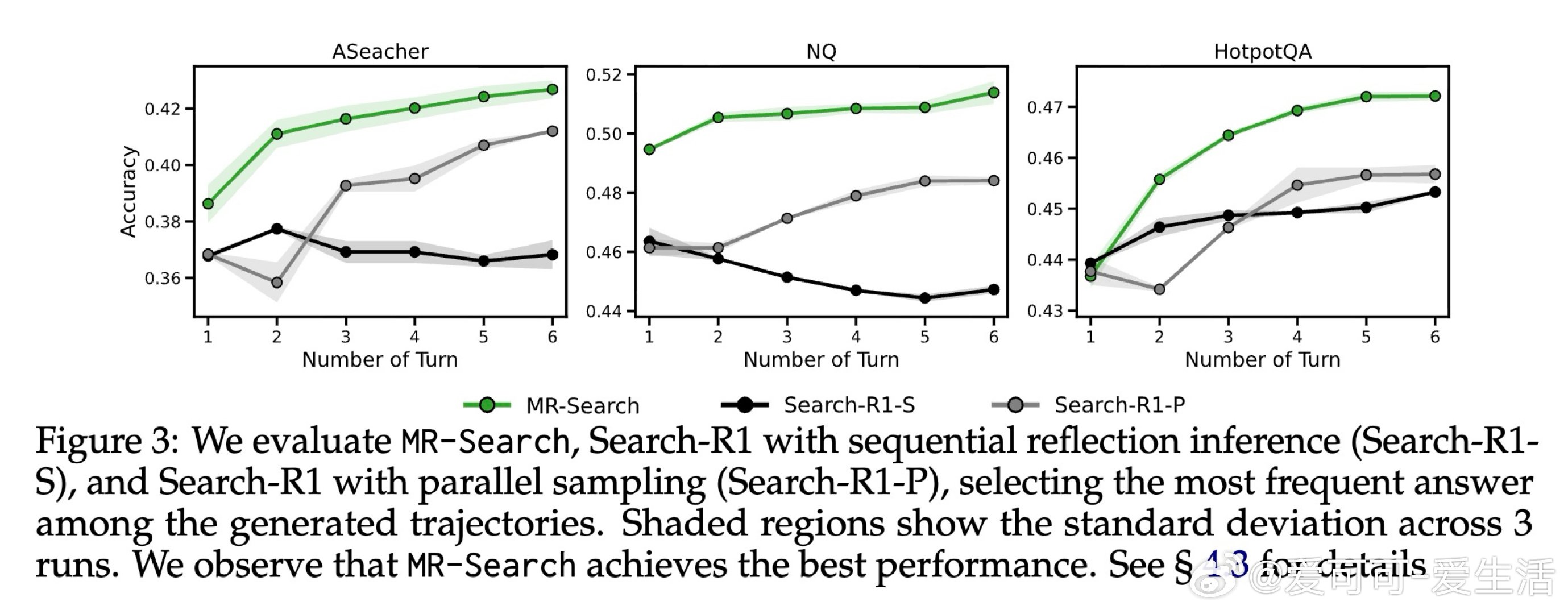
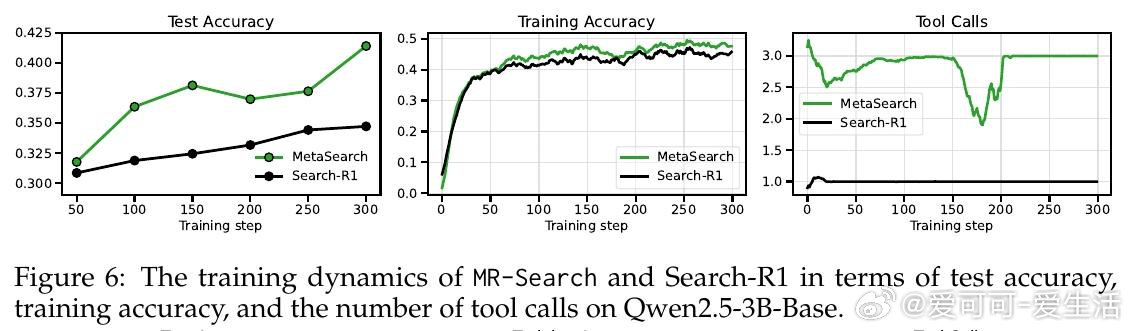
这项工作真正留下的遗产是:证明了元强化学习的"跨情节上下文积累"思想可在纯文本智能体中以低成本实现,并在八个基准上带来9%至19%的实质提升。它为后来者打开的新门是:将测试时的序列反思与训练目标统一对齐,使模型能在推理阶段持续自我改进。但尚未跨过的门槛是:当前方案仅适用于有精确答案可供验证的任务,对长文本生成和多异构工具环境的扩展性仍是悬而未决的挑战。
arxiv.org/abs/2603.11327
机器学习 人工智能 论文 AI创造营