[LG]《Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights》Y Gan, P Isola [MIT CSAIL] (2026)
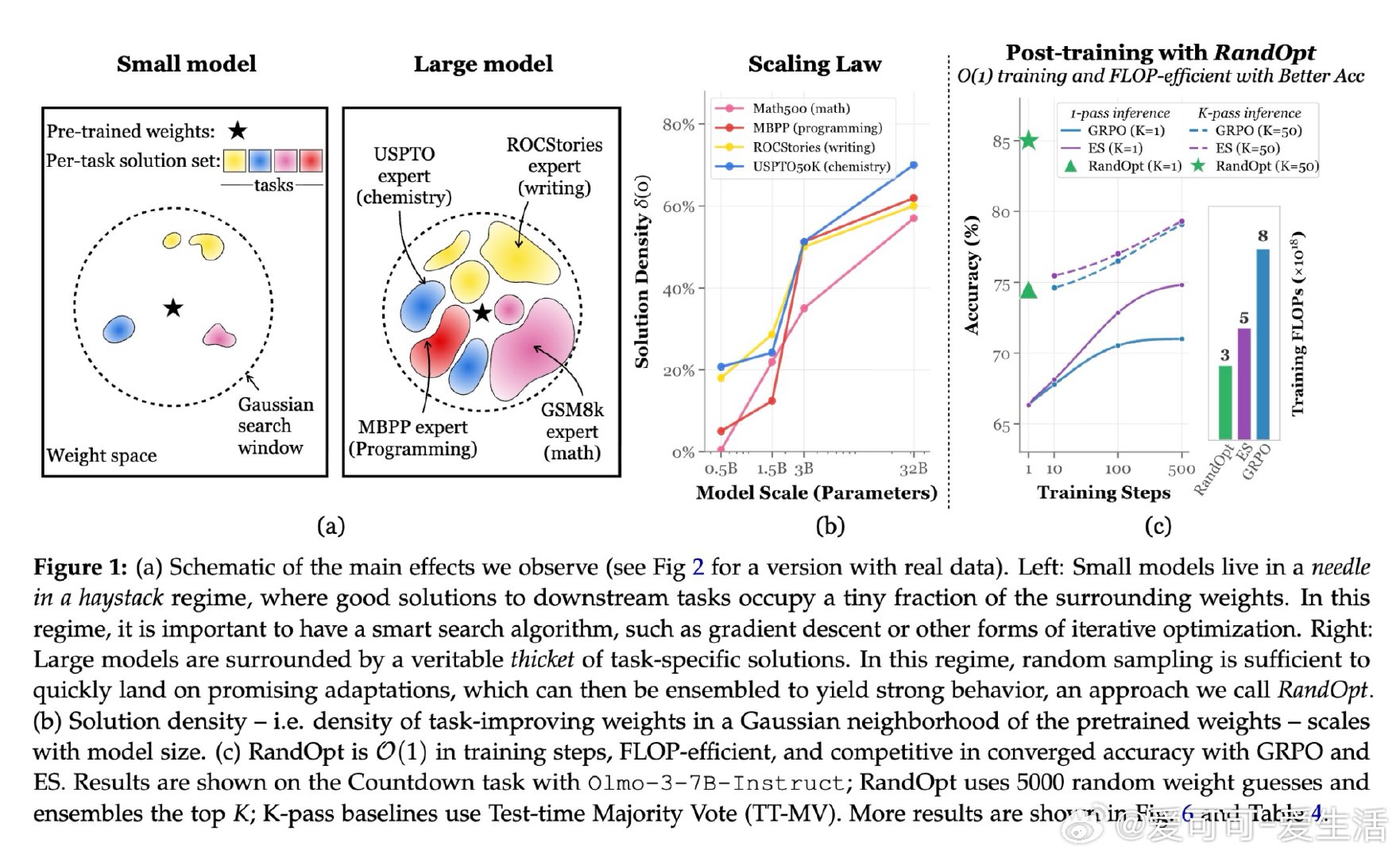
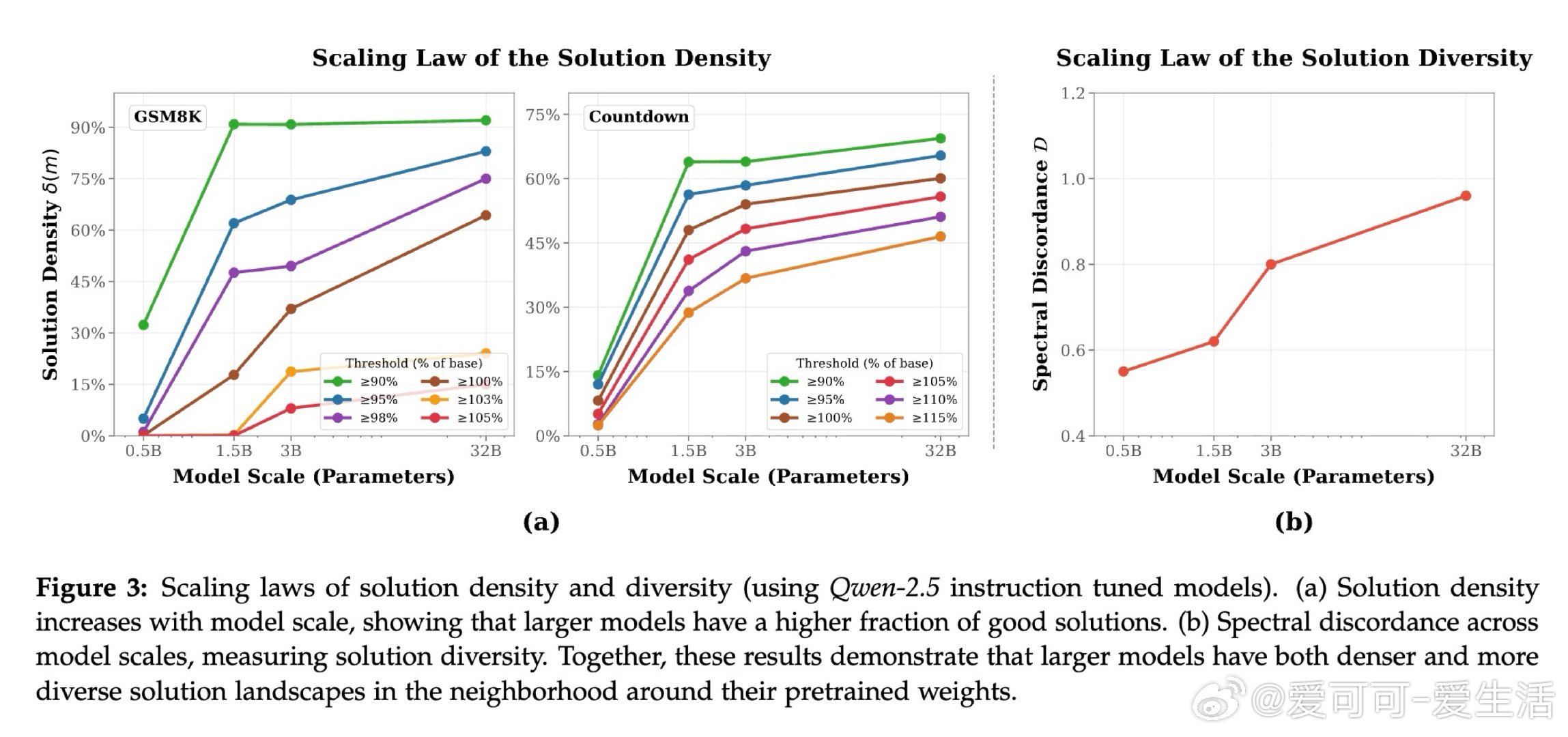
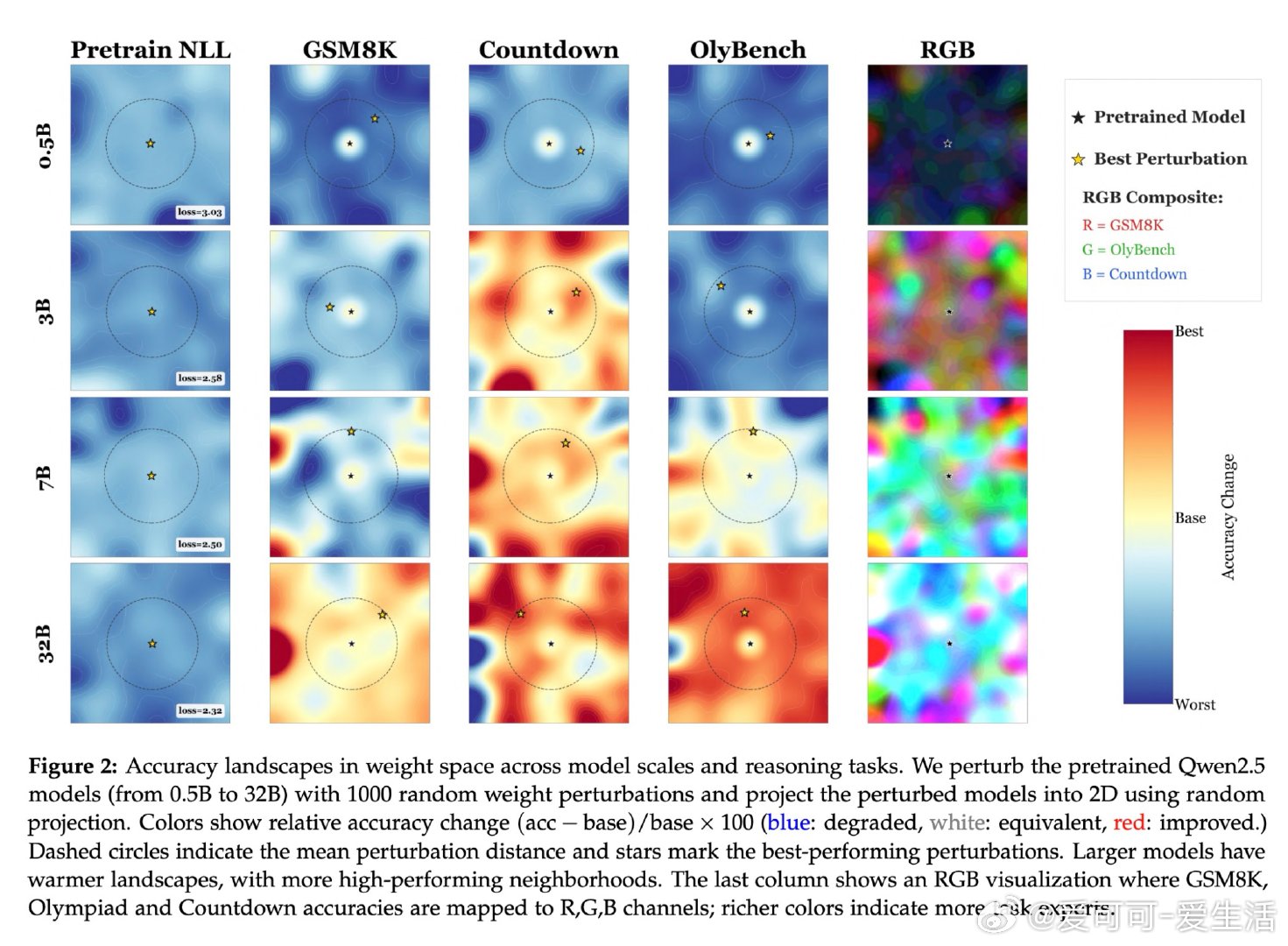
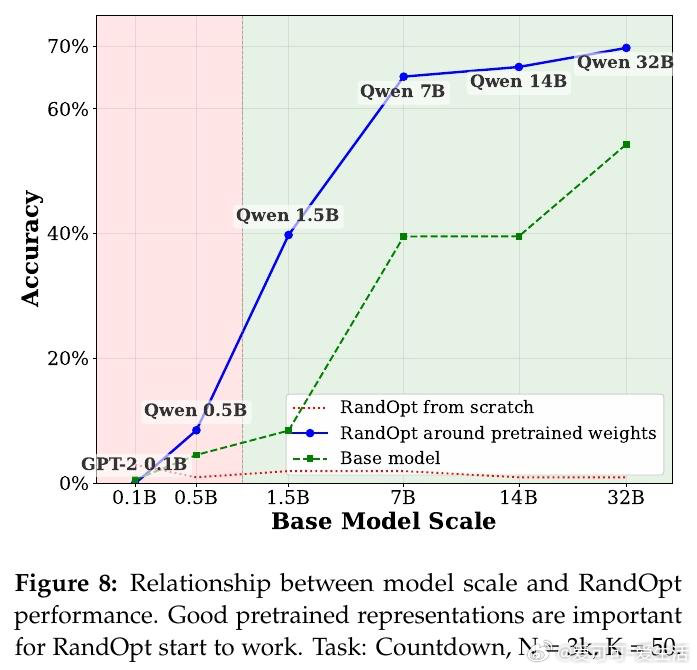
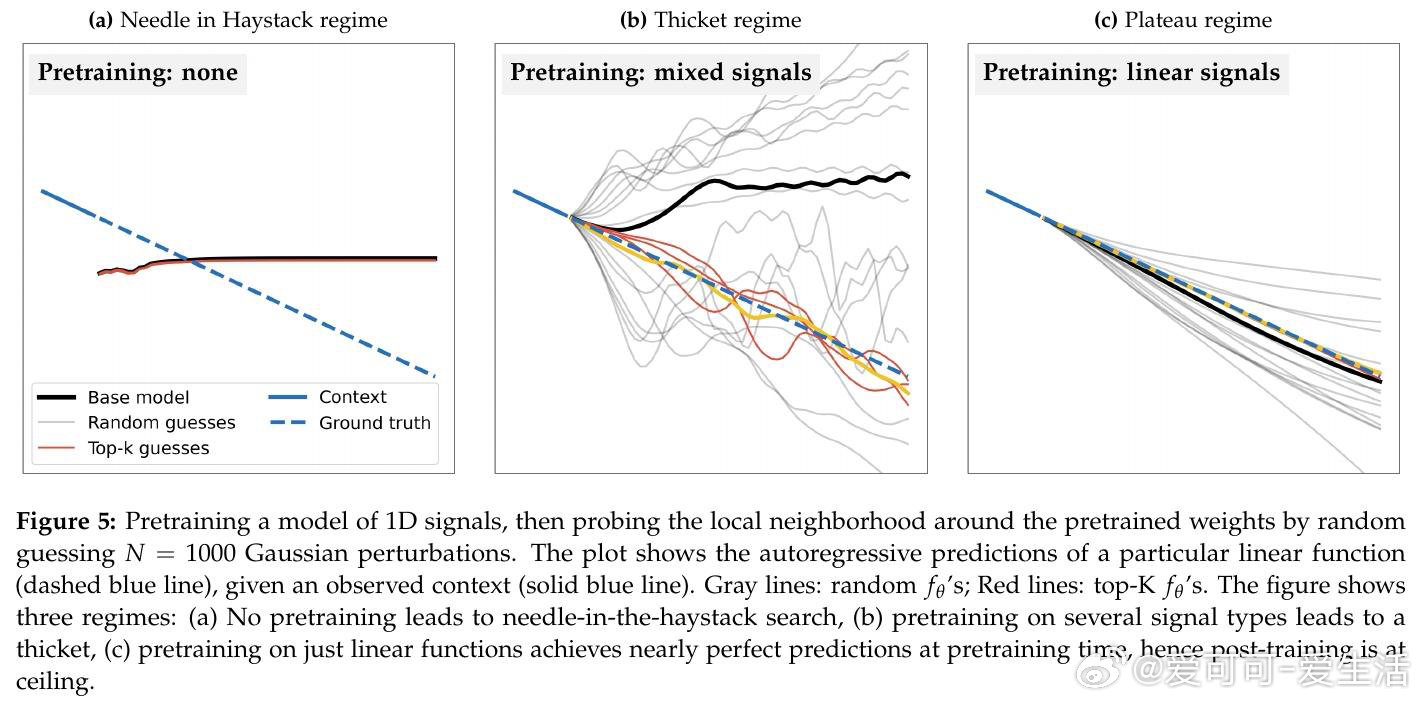
大型语言模型经过充分预训练后,其权重邻域中密集分布着任务专家解——随机扰动即可命中有效解,无需梯度下降。小模型处于"大海捞针"困境:好解极其稀疏,必须依赖有结构的迭代搜索;而随模型规模增大,这一密度急剧提升,进入"神经丛林"状态。
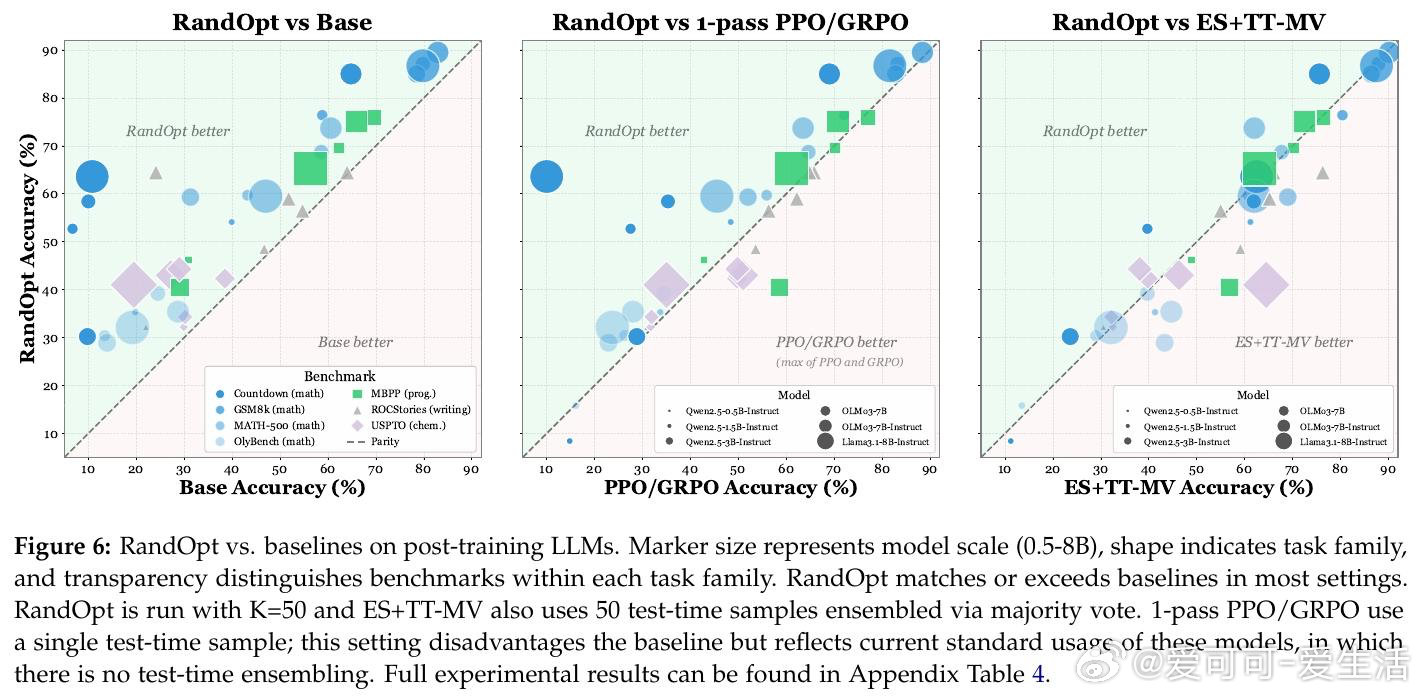
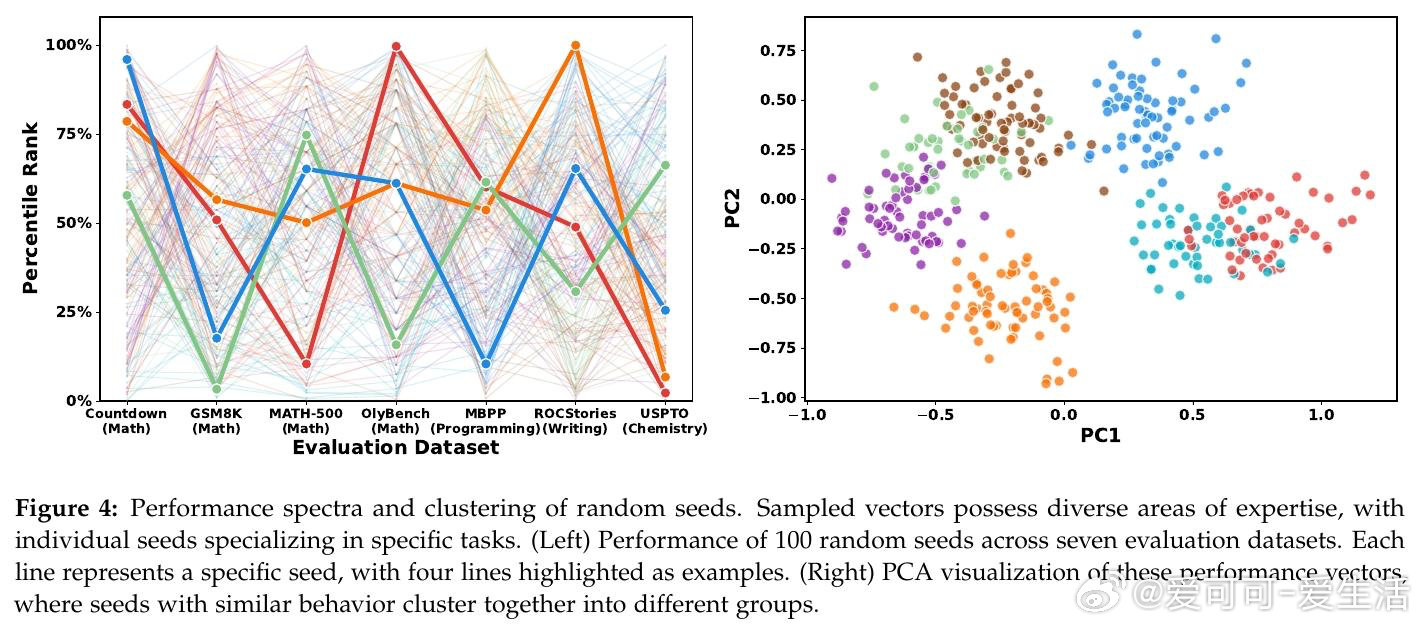
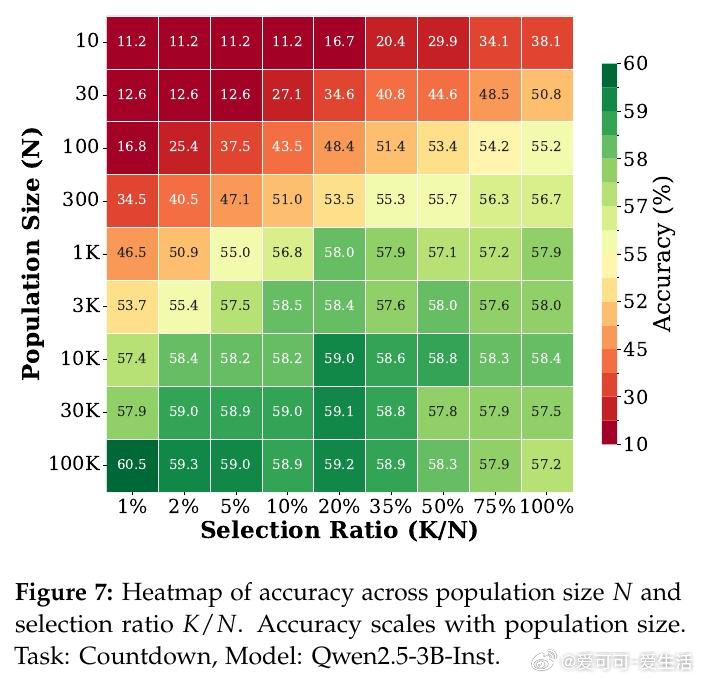
本文的核心洞见是:把预训练权重重新看作一个分布,而非单一起点。由此,"随机采样N个权重扰动,选取表现最优的K个,再通过多数投票集成预测"这一关键操作使问题得以解开——不同扰动各自是不同任务的专家,集成恰好利用了这种多样性。
这项工作真正留下的遗产是:证明了充分预训练本身就是一种隐式的元学习,让下游适应变得出奇简单。它为后来者打开的新门是:以分布视角重新理解预训练权重,以及探索完全并行、无需通信的去中心化适应范式。但尚未跨过的门槛是:当前收益存在明显饱和,模型是否能借此突破自身能力边界、习得全新技能,仍是未解之题。
arxiv.org/abs/2603.12228
机器学习 人工智能 论文 AI创造营