[LG]《IsoCompute Playbook: Optimally Scaling Sampling Compute for LLM RL》Z Cheng, Y Xie, Y Qu, A Setlur… [UC San Diego & CMU] (2026)
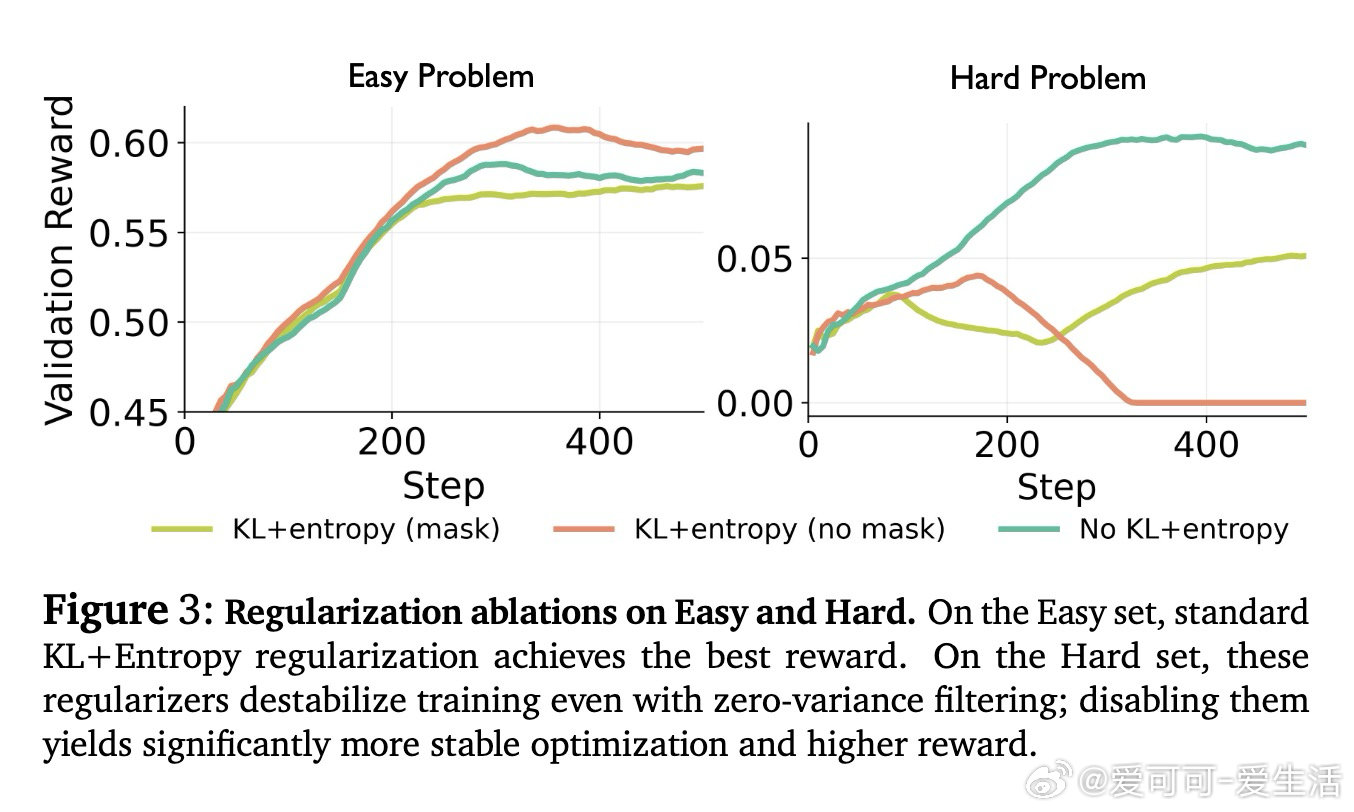
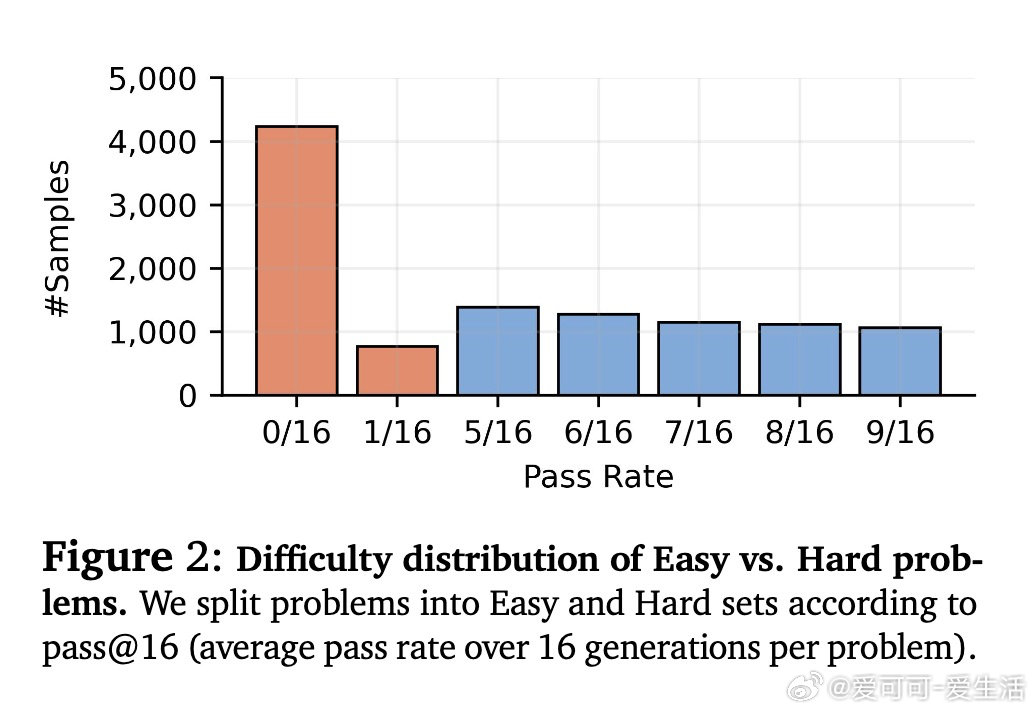
在大语言模型强化学习后训练领域,从业者面临一个悬而未决的资源分配难题:给定固定计算预算,应如何在每问题并行采样数、批量问题数、梯度更新步数三个维度间权衡?过去的工作仅沿单一轴缩放,本质原因是RL中数据采集与优化的紧耦合使训练行为对配置高度敏感,稳定性与规律性难以同时保证。
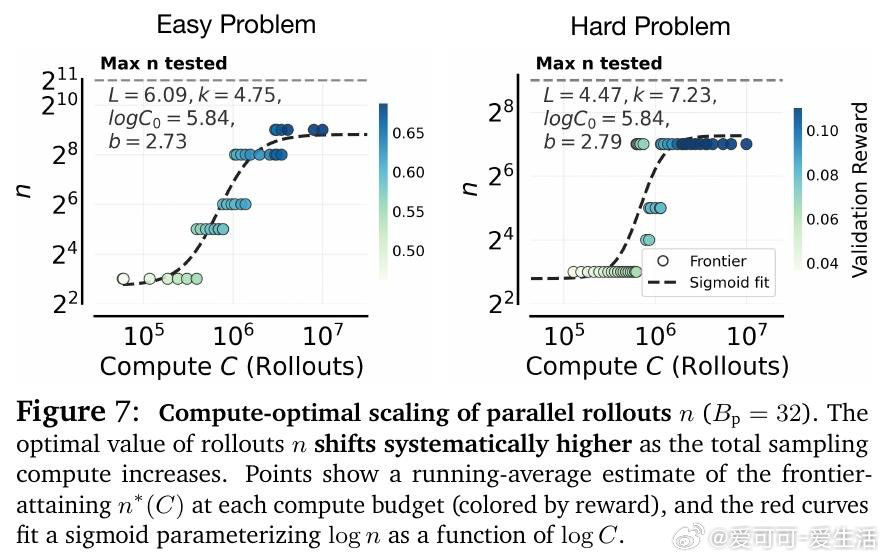
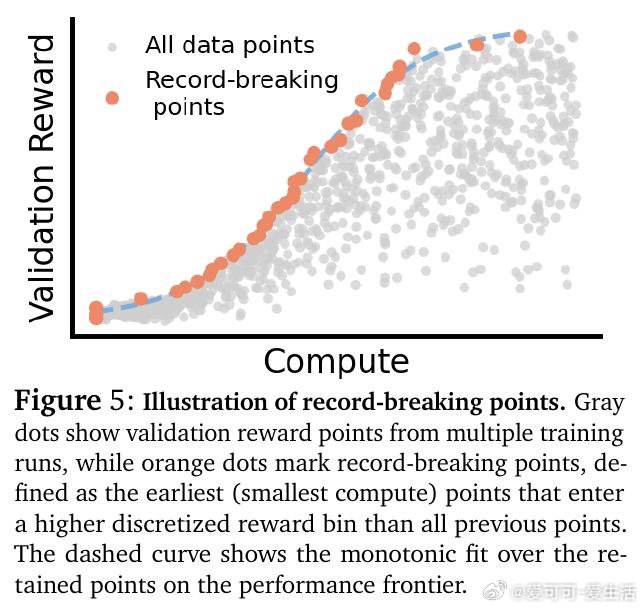
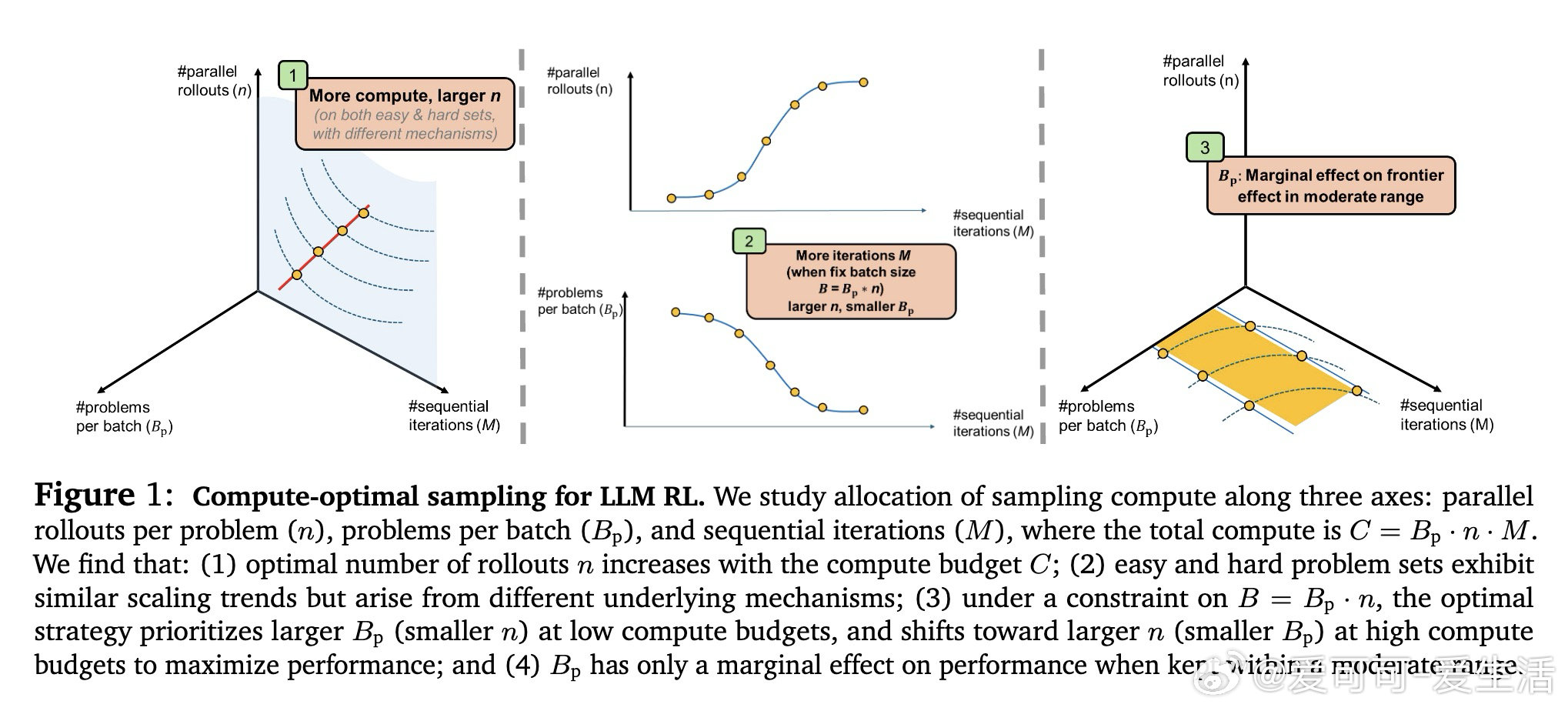
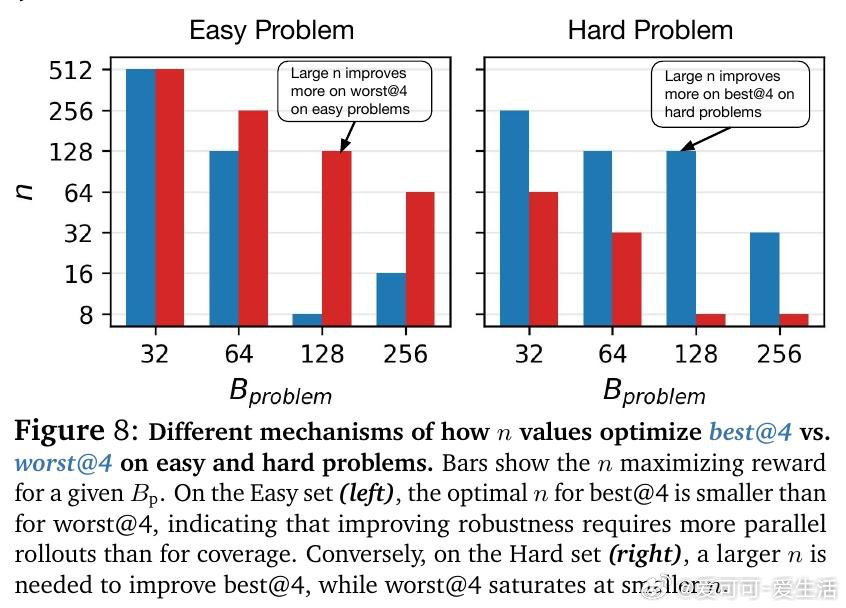
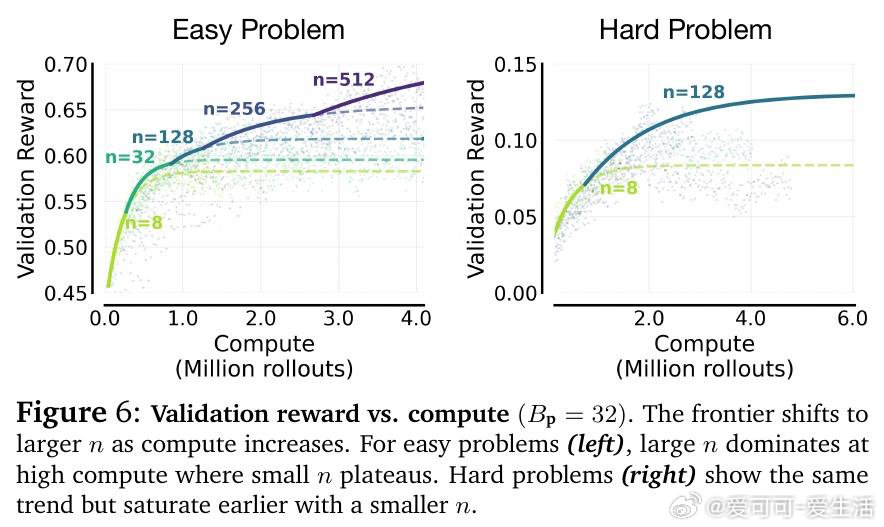
本文的核心洞见是:把RL超参数选择重新看作固定计算预算下的分配优化问题。由此,"等算力等值线分析"这一关键操作得以将混乱的超参数扫描还原为可预测规律——最优并行采样数随预算呈S型增长后饱和,且饱和点由多问题联合训练时的梯度干扰强度决定:并行数越大,跨问题更新越均匀,干扰越小,这才是并行优于序列的真实机制。
这项工作真正留下的遗产是:将LLM强化学习的工程直觉转化为可外推的分配准则——随预算增长优先扩大并行采样、批量问题数作为稳定性旋钮次要调节。它为后来者打开的新门是基于pass﹫1分布动态诊断干扰程度、进而预测最优超参的方向。但尚未跨过的门槛是:当前规律依赖特定问题难度分布,在极端难度或超大批量混合场景下的普适性仍待验证。
arxiv.org/abs/2603.12151
机器学习 人工智能 论文 AI创造营