千问视频图像模型升级,把AI助手性能拉满了
我现在算是真正看懂了阿里的AI战略,只有底层逻辑技术做到足够强,C端的入口才会牢固,AGI归根结底还是依赖底层技术的进化。
12月2日,阿里千问正式官宣全新的AI⽣视频和⽣图能⼒,同时接入国内最强视频生成模型Wan2.5和全球最强开源模型Qwen-Image的独家满血特供版Qwen-Image 2511,更新了下APP后,马上做了几个测试,感觉千问对任务指令的理解、语义、语境分析都非常强了,这应该就是阿里最强大模型带来的体验上的爽感。
1.AI生图测试
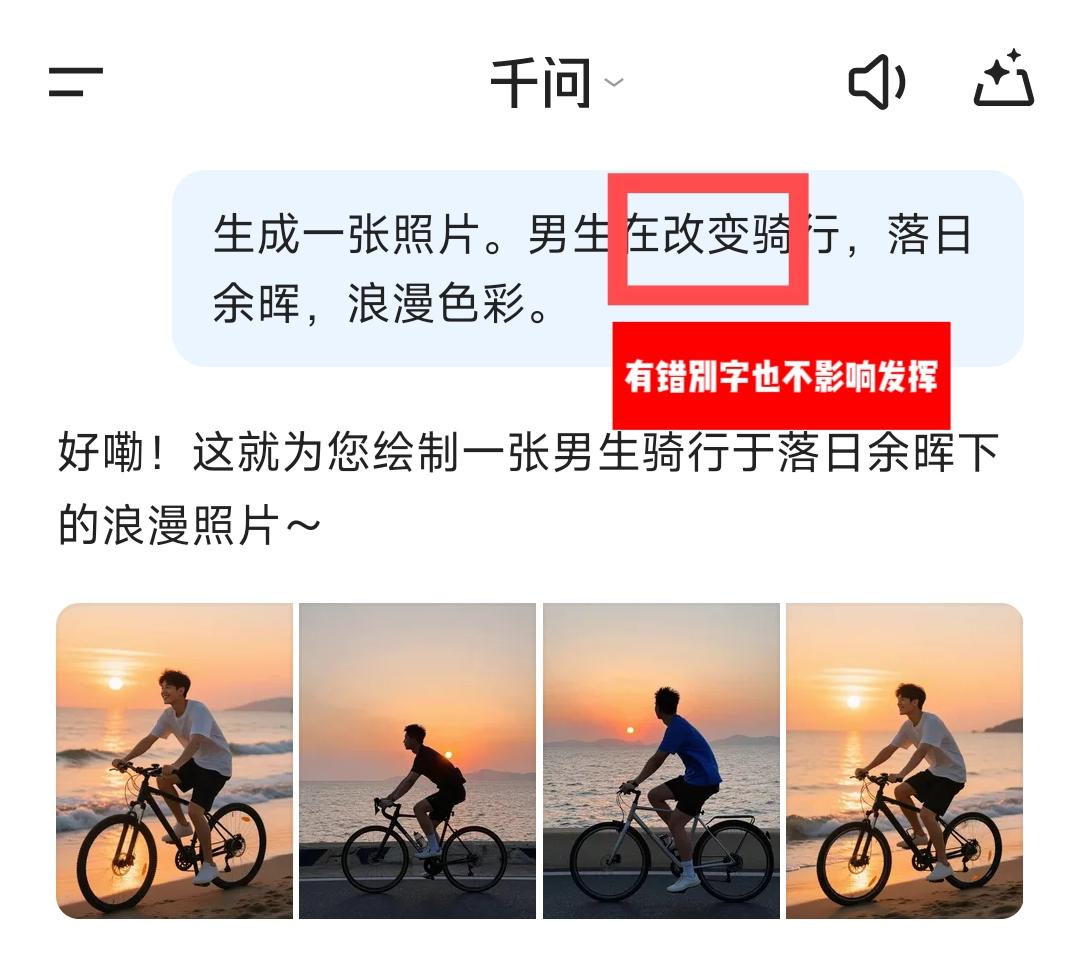
指令:生成一张照片。男生在改变骑行,落日余晖,浪漫色彩。
生成结果如P2所示。输出的图片质量很高,很有意境。但我更想说的是,你们有没有注意到细节(P3),我也是在图片生成后才发现自己写指令的时候输入了错别字,“海边”错误写成了“改变”,但这丝毫没有影响到千问的发挥。阿里最强大模型打底,语义分析能力确实强。
2.AI生视频测试
素材:一张狗狗图片
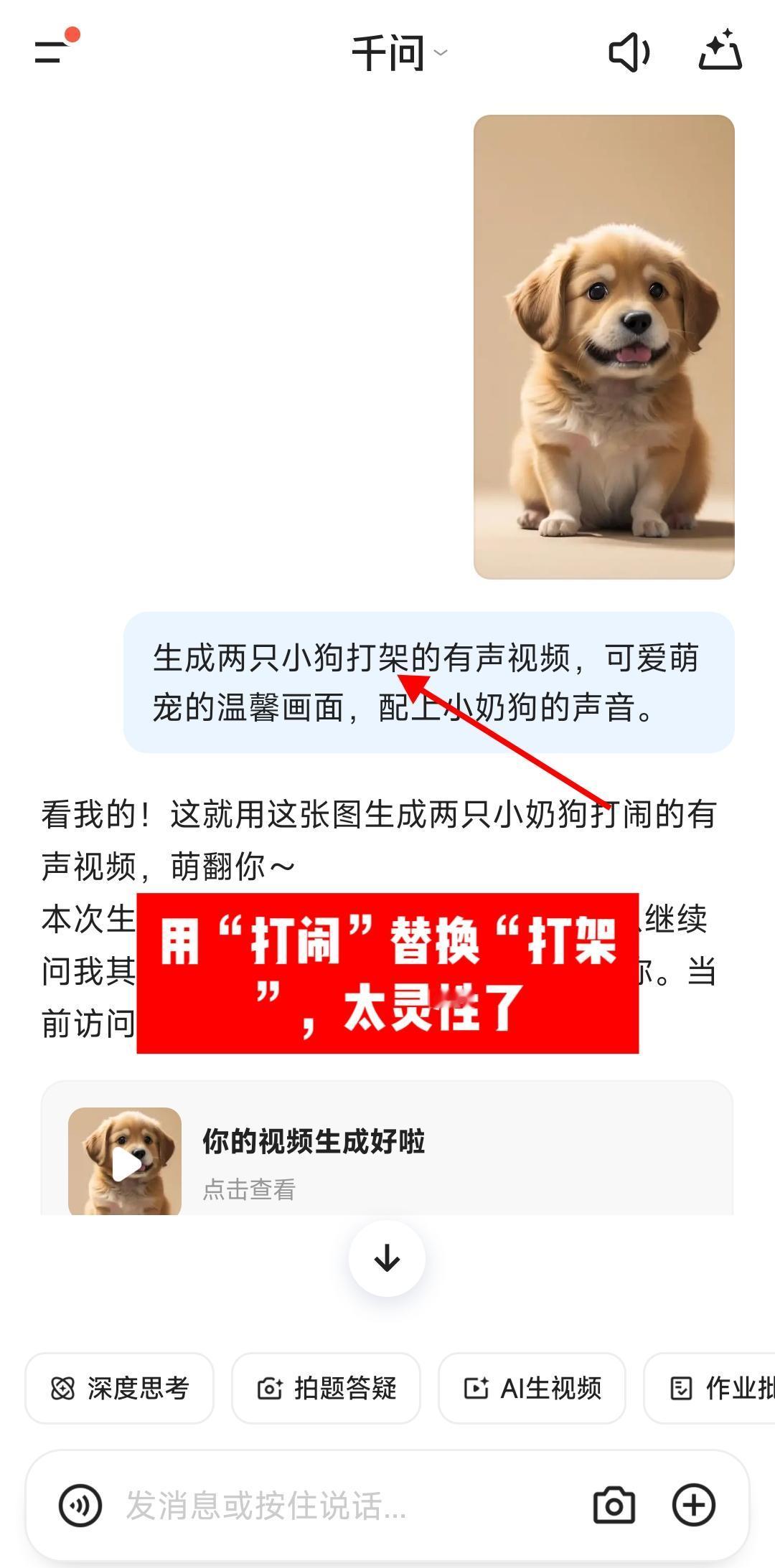
指令:生成两只小狗打架的有声视频,可爱萌宠的温馨画面,配上小奶狗的声音。
我只提供了一只狗狗的图片,要求生成两只狗狗打架的视频,输出结果放在P4了,无论是狗狗的形象、动作还是声音,都很nice,看着是不是给人萌化了?
这里还有个重点,很细节,大家看P5,千问在解析任务指令的时候,用“打闹”替换了“打架”,我挺惊讶的,这个替换很灵性。因为我的指令里要求是“可爱萌宠的温馨画面”,结合这个要求,“打闹”明显比“打架”更合适。千问对语境的理解,遣词方面,比我强了。
3.对口型测试
千问这次升级后,还有很多玩法模板,用户可以跟着拍同款。比如,我做的对口型测试,大家看P6。
素材就是一张狗狗图,哈几米之歌的对口型视频,嘴型动作跟音乐节拍的同步性很高。可玩性很强。千问提供了非常多玩法,比如照片滤镜、影分身、对口型、全民舞王等等,wan2.5模型可以生成最长10s音画同步的视频,还支持多语种,这下真的想玩什么抽象就自己生了,大家也可以去体验一下,我感觉,AI有可能会改变现有的短视频生态了。
一番测试下来,千问的表现还是超出了我的预期,无论是生图还是生视频,优势都足够明显。现在生图还是免费不限次数使用的,大家都快去体验下,记得评论区交作业!