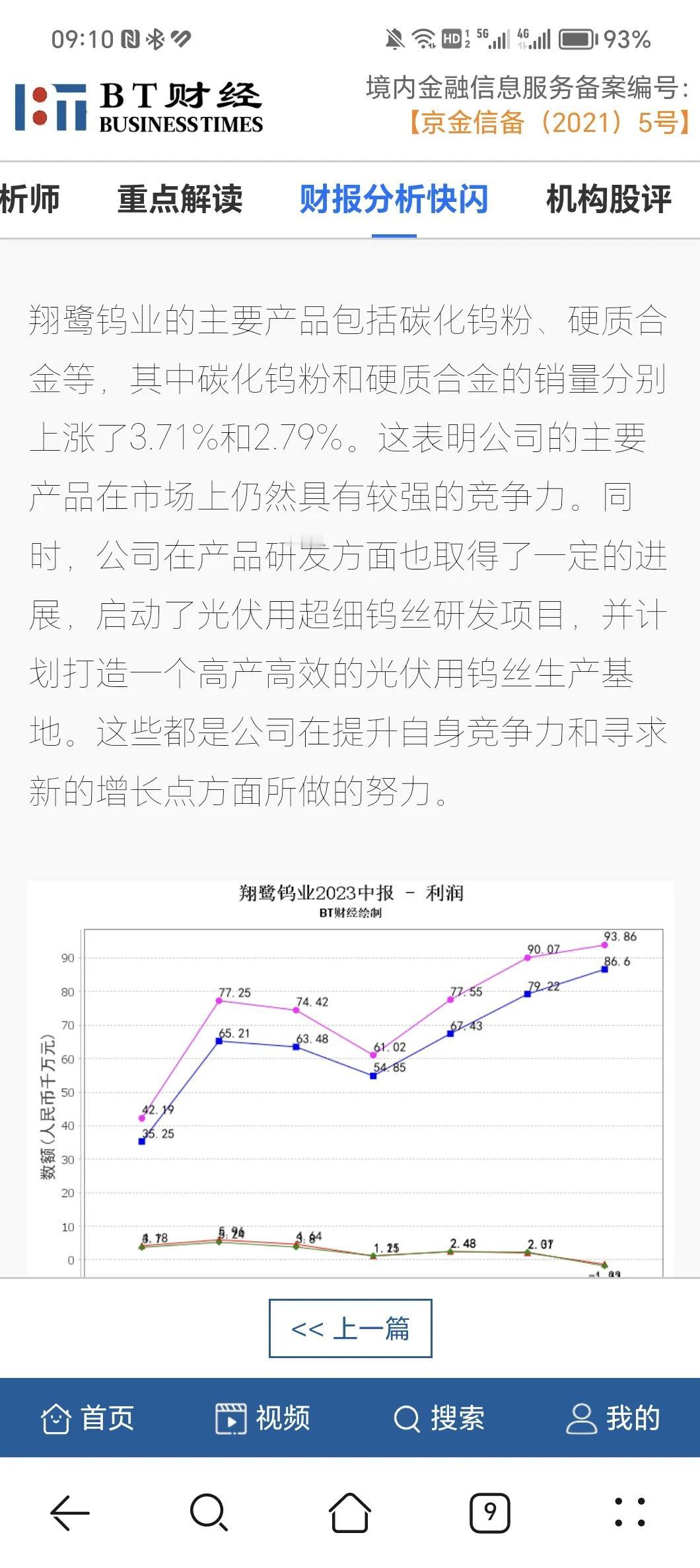
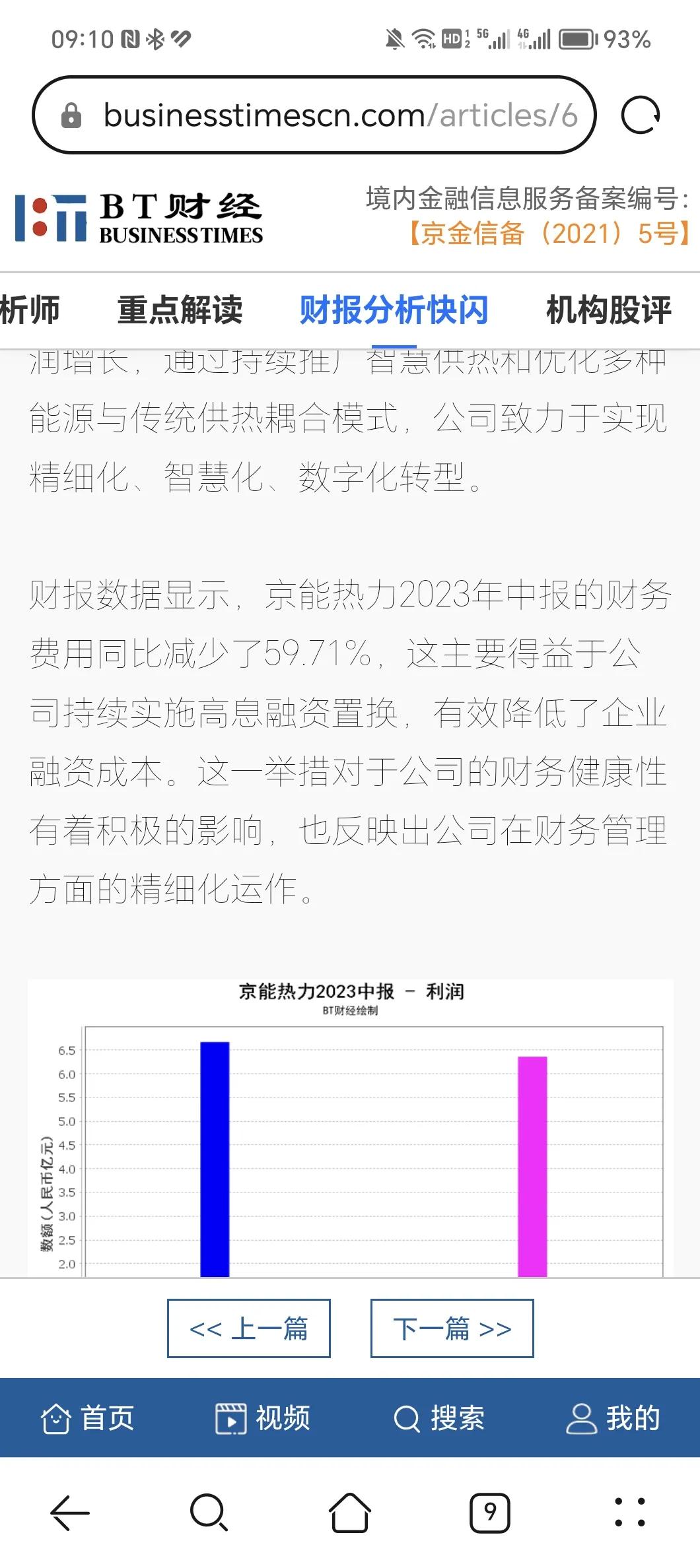
好吧,今天继续battle。节前受邀参加了几家云服务商的活动,其中有一位很资深的云服务商自身专家出面给我们,彻底讲述了一下中国和美国在AI和大模型方面的进展与差距。 但有意思的是中午吃饭的时候,就开始有号称科技大v出来给我们布道。认为从ChatGPT开始,中国和美国之间AI与大模型的差距就是以阶梯状的方式来显现,甚至认为中国到现在的能力永远也追不上美国。 好吧,我不知道,科技的大V居然愚蠢到了这种程度。 我们自己的公司是一家做资本市场数据分析的企业,分析结果展示更偏重于媒体表现,因此也拿到了网信办互联网金融信息服务备案的许可。对于ChatGPT在金融领域的应用经验,我想我们是中国任何一家企业都无法比拟的,因为我们在去年11月份,就从美国同事的手上拿到了当时chat GPT3的内测代码,开始在自身的系统中就此进行测试和开发。 所以对于大模型和大模型的应用,我想我们应该是在中国,算有自己核心发言权的那一拨人。 实际上不论是美国的ChatGPT,哪怕是4,亦或是其他几个开源的模型,或者是美国彭博社特意推出的针对于资本市场分析的大模型工具,我们都用过。反馈情况是技术非常酷炫,结果烂的一批。彭博社号称综合几个开源大模型的优势,推出针对资本市场数据的分析工具,我们拿两家A股的公司财报导入,不是数据提取位置出现错误,就是数据理解出现错误,最后的图表也是无法使用的。而且有意思的是,我们觉得可能是因为资本市场不同的对于财报要求所致,我们还将美国股市上市公司的财报导了进去,结论依然是一样的。 所以我们这6个多月以来,不得不自己用GPT4和国产大模型文心一言与星火,结合开发了一套大模型拆分财报并作出简短点评的系统,而这套系统最核心的并不是技术,技术团队只用了不到20天就全部做完了,最核心的是我们20多位分析师历经三个月,对所有能遇到的错误进行的数据标注,几乎超过8万条。 我们现在还需要三位分析师同事每天8个小时,通过后台来关注各个模型生成的内容,相关数据有没有错误,虽然数据的错误率已经降到了95%以下,但在资本市场层面,只要一个数据的错误,就可能对于投资人的决策造成诱诱导,而平台的专业性就没有办法显现。 我们说这么多的原因,其实是告诉大家,当下不论是国产大模型,还是美国的ChatGPT4,亦或是其他那些开源的大模型,其实都是通用模型,只解决了与人机对话中的自然理解问题,真正让他们去处理行业中的工作错误百出。 在我们的测试中,所有的模型都有这样的问题,原因也很简单,他们在前期的学习中,只是将互联网能找到的信息输入进去,真正在专业领域才能碰到的相关数据问题和解析问题,他们是不可能涉及的,因为这会增加大模型培训的时间,同时支出更多的成本。 所以大模型技术上的强弱,我认为没有任何意义,当下的技术水平,哪怕国产模型稍微弱一点也都够用了。再先进的大模型跟产业结合不到一起去,它就是一个昂贵的玩具。 说到中美在大模型的竞争上,国家已经对这件事情有了深刻的认知,有一句话是在最近这段时间从高层提出来的,就是“利用通用人工智能,推动实现产业体系的智能化”。所以国家看到的是大模型,一定要跟我们现在的产业体系相结合,而美国看到的是我一定要在大模型的领域实现技术的领先,这就产生了一个巨大的分歧。 美国其实不是不想在各个行业都将大模型部署进去,但是他遇到了很多的问题,最核心就是数据不足,我再举个例子,比如说在医疗领域,大模型应用最核心的点、能解决医生的难题,并且提升诊疗效率的,就是CT阅片。那么我拿到了一个内部数据,美国全年拍摄的CT片子是中国大概拍摄CT片子总量的1/500。换句话说,中国的医生一年内在CT中见到的疑难杂症的数量和种类,是美国的医生一辈子都难以想象的。因此用美国自己的CT数据来训练CHATGPT4,其对CT阅片的结果准确程度和用中国的数据来训练中国的模型,最终产生的结果,一定是技术稍微落后一点的中国模型胜出。这说明了数据对于当下大模型领域中美竞争的重要性。 然后中美在大模型领域产生这样的能力差距和数据差距,重要原因就在于美国推行了20年的脱实向虚,而中国在不停的夯实制造业基础。美国将大量的资金投向了互联网技术的研发,这是他们脱实向虚和金融资本化的一个最核心的标志;而中国确实这20多年来不停的夯实制造业的基础,搭建了全球最完善的制造业体系,在这个过程中美国产生了GPT这样的先进的互联网技术,但可惜的是它没有后续的行业数据支撑,注定恐怕只能成为一个昂贵的玩具,而中国有了这些行业的数据和制造业的底气,如果有哪怕技术差一点,但是可以用的通用模型来匹配,就会产生放大性的辐射效应。 这也是在中美大模型竞争中,我极力看好我们国家的重要原因。