腾讯混元团队在姚顺雨加入后发布的首篇论文《CL-BENCH: A Benchmark for Context Learning》,首次系统性指出:当前大模型在“长上下文”上的核心短板,不是读不全、找不到,而是“学不会、用不对、执行不了”。
针对这一问题提出了一个新的评测范式——Context Learning(上下文学习),并构建了对应的基准测试 CL-Bench。
论文区分了两种常被混用的能力概念:In-Context Learning(ICL):模型通过少量示例学习输入输出模式或格式,本质上是激活预训练中已有的知识结构;
Context Learning(上下文学习):模型必须从一次性提供的上下文中,吸收此前未在预训练中掌握的新知识(如全新规则、流程、领域体系或隐含规律),并将其正确应用于后续任务。作者指出,后者才是人类在真实工作场景中最常见、也是 Agent 能否完成复杂任务的关键基础能力。
为评估这一能力,CL-Bench 构建了 500 个高复杂度长上下文任务,平均长度为 10.4k token,最长可达 65k token。所有上下文内容均为虚构知识、改写规则或极端长尾内容,确保模型无法依赖预训练知识“作弊”。
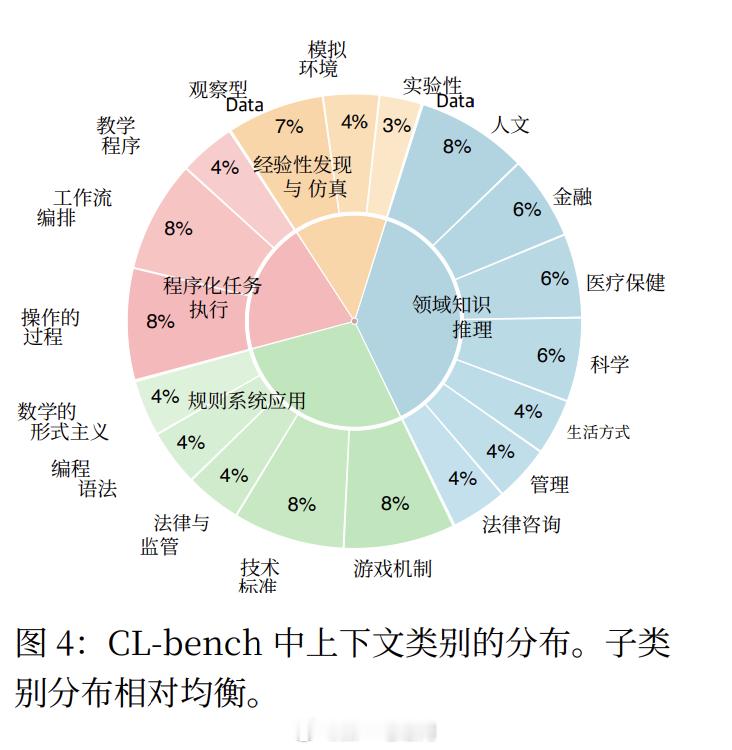
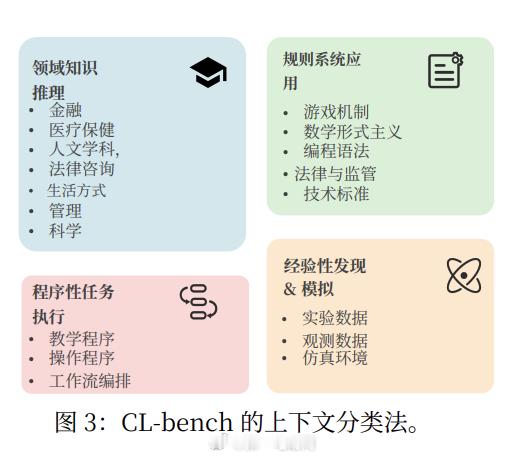
任务覆盖四大类型、19 个子类,分别模拟不同层级的人类上下文学习场景:领域知识推理:在全新规则体系下进行因果分析与决策;规则系统应用:在反直觉或封闭逻辑中严格推导;流程任务执行:按照复杂 SOP 完成多步骤操作;经验发现:从原始数据中归纳隐藏规律。
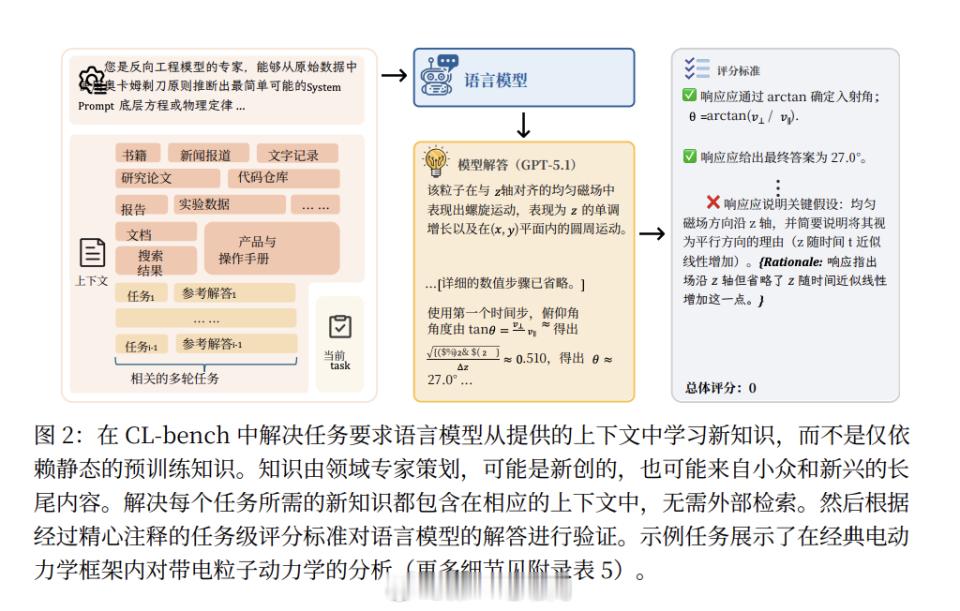
在评测方法上,CL-Bench 为每个任务设计了平均 16.6 条 Rubrics 规则,从事实、计算、流程、格式等多个维度进行验证。只有同时满足全部规则,任务才被判定为成功,强调“正确执行”而非“部分合理”。
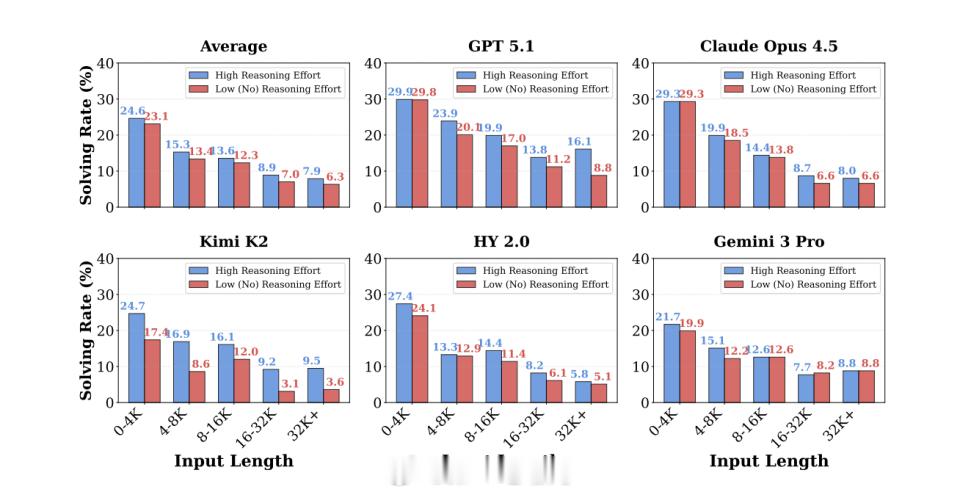
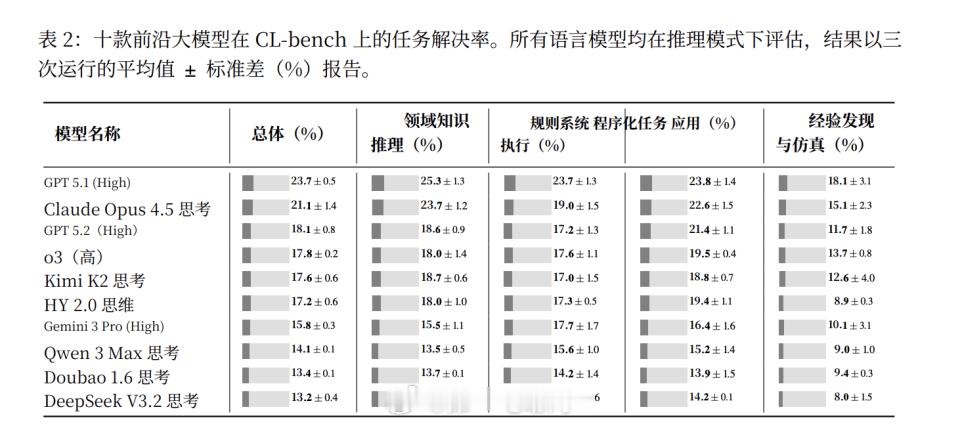
实验结果显示,10 个前沿大模型在 CL-Bench 上的平均成功率仅为 17.2%,表现最好的 GPT-5.1(High)成功率为 23.7%。在最具挑战性的“经验发现”任务中,整体成功率进一步下降至 11.8%。同时,所有模型的表现均随着上下文长度增加而持续下降。
错误分析表明,模型失败主要集中在三类问题上:忽略关键信息;误用上下文规则或约束;未能遵守明确规定的输出格式或流程要求。
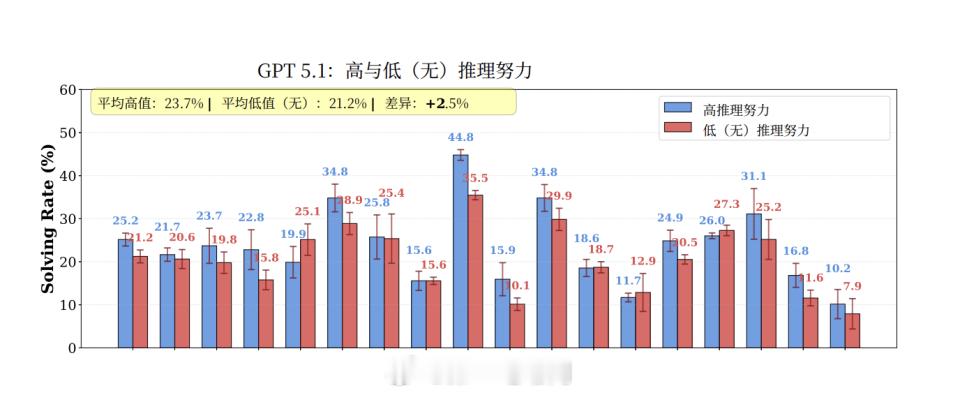
论文进一步指出,当前长上下文技术路线主要提升的是“读取与定位”能力,而非将上下文转化为可持续执行的内部知识。即便提高推理强度,也只能带来有限改进。
在讨论部分,作者提出了未来提升上下文学习能力的若干方向,包括:构造强上下文依赖的训练数据、采用课程式难度递进训练、将 Rubrics 转化为训练信号,以及探索更适合上下文利用的新模型架构。
论文最后强调,只有当模型能够快速内化陌生上下文,并精确、稳定地应用这些知识完成任务时,AI 才能真正成为可用的推理型 Agent。CL-Bench 的目标,正是为这一能力提供清晰、可检验的评估基准。腾讯AI人工智能