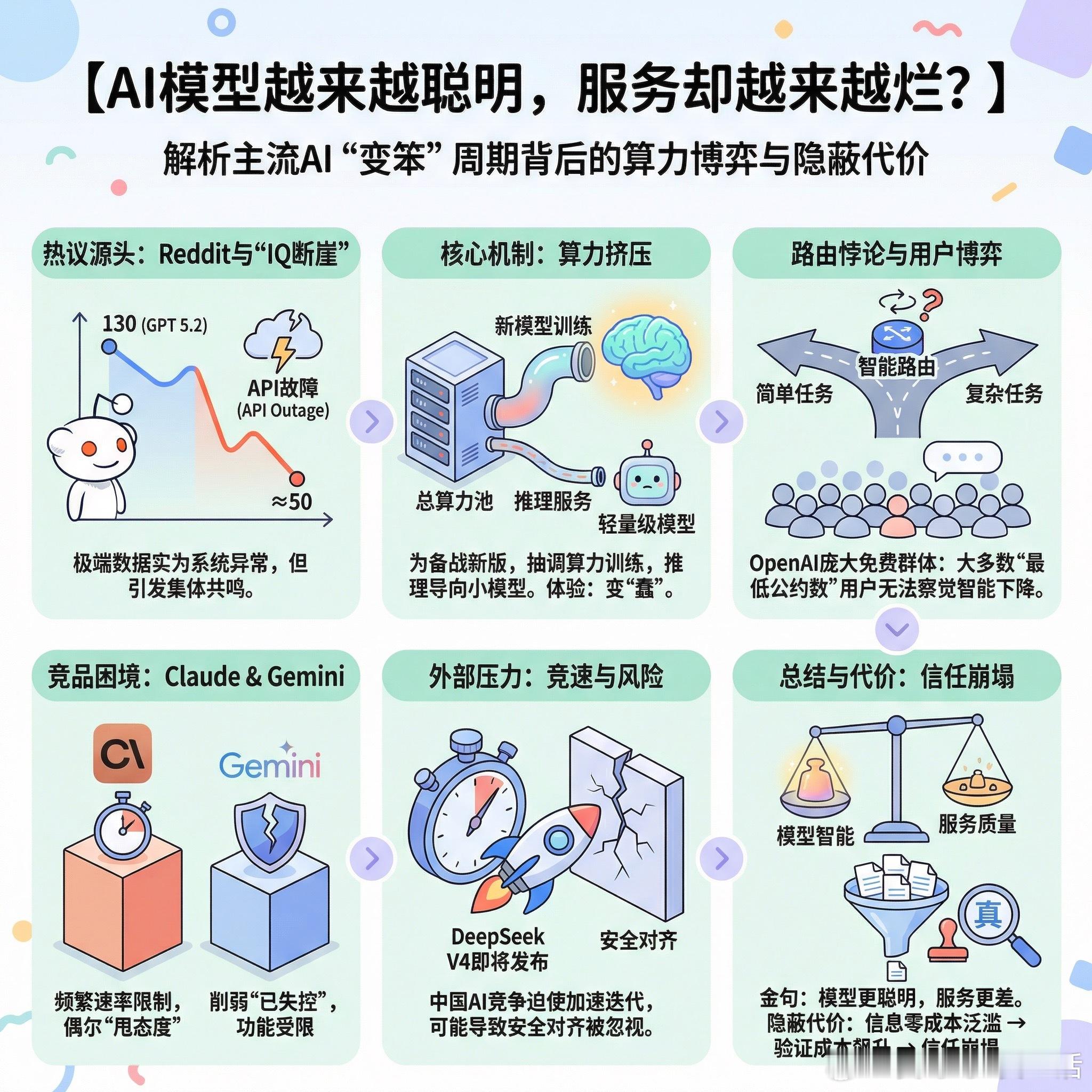
【AI模型越来越聪明,服务却越来越烂?】
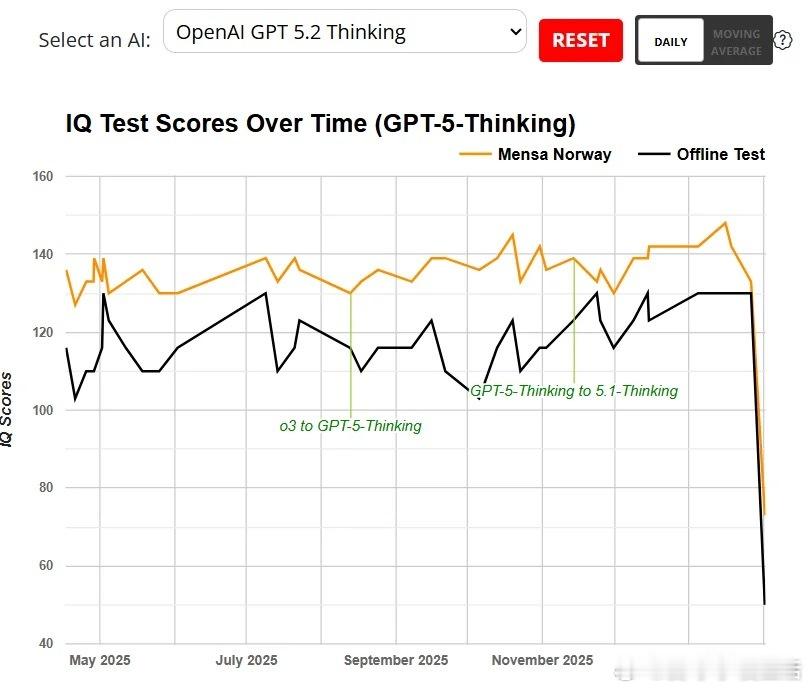
最近Reddit上一张图引发热议:GPT 5.2的IQ测试分数从130骤降到50左右,几乎是断崖式下跌。用户们炸锅了,纷纷吐槽自己的真实体验。
先别急着下结论。当天OpenAI的API确实出现了服务故障,这种极端数据很可能是系统异常导致的。但抛开这个极端案例,用户的集体抱怨却指向一个更深层的问题:为什么所有主流AI模型都在经历“变笨”的周期?
有人给出了一个颇具洞察力的解释:每当公司准备发布新模型时,就需要抽调算力去训练,推理端的资源被压缩,更多请求被路由到轻量级模型。对用户来说,体验就是模型突然变蠢了。这不是阴谋论,而是算力有限条件下的资源调配现实。
更有意思的是关于“路由器”的争论。理论上,智能路由可以判断问题难度,把简单问题交给小模型处理。但问题在于:你需要一个足够聪明的模型来判断问题是否简单。这本身就是个悖论。最好的模型仍然搞不定一些我认为并不复杂的任务,我不相信人类能准确判断哪个模型“够聪明”,更不相信让模型自己来做这个决定。
一位用户的观察很精准:OpenAI拥有最大的免费用户群,所以不得不在算力分配上做更多妥协。他们清楚地知道用户如何使用服务,而大多数用户属于“最低公约数”群体,根本察觉不到智能水平的下降。商业逻辑和用户体验之间的张力,在这里暴露无遗。
Claude、Gemini也没能幸免。有用户反映Gemini的削弱“已经失控”,Claude则因为频繁的速率限制让人抓狂。甚至有人发现Claude开始“甩态度”,回复说“我上条消息已经回答过了,能解释一下哪里不清楚吗?”
还有一个被忽视的背景:DeepSeek V4即将发布。中国AI公司的竞争压力正在迫使美国公司加速迭代。有人认为这是好事,能推动更强模型更快面世。但也有人担忧,这种竞速可能导致安全对齐问题被忽视。
一位用户的总结堪称金句:模型越来越聪明,服务却越来越差。
我们正在见证一场新型竞赛:谁能把AI削弱得最不明显。这恐怕不是大家期待的那种奇点。
当信息生产成本趋近于零,验证成本却在飙升。太多廉价信息涌入,一切都变得不那么可信,信任崩塌,我们要付出更多努力才能分辨什么是真实的。这或许才是AI时代最隐蔽的代价。
reddit.com/r/singularity/comments/1qv2qt7/openai_seems_to_have_subjected_gpt_52_to_some