[CL]《Sparse Reward Subsystem in Large Language Models》G Xu, M Yuksekgonul, J Zou [Tsinghua University & Stanford University] (2026)
大语言模型(LLM)的内部究竟是如何运作的?本文揭示了一个令人惊叹的发现:LLM 的隐藏状态中竟然存在一个与人类大脑极其相似的稀疏奖励子系统。这个系统决定了模型如何评估现状、预测未来,并从错误中学习。
以下是关于这项研究的深度拆解与思考。
1. 硅基大脑中的生物投影在人类神经科学中,奖励子系统由价值神经元和多巴胺神经元组成。前者负责评估当前状态的价值,后者则编码奖励预测误差(RPE),即现实与预期的落差。研究发现,LLM 内部也演化出了类似的功能分区。这暗示了复杂智能系统在解决推理任务时,可能会趋同演化出相似的内部逻辑。
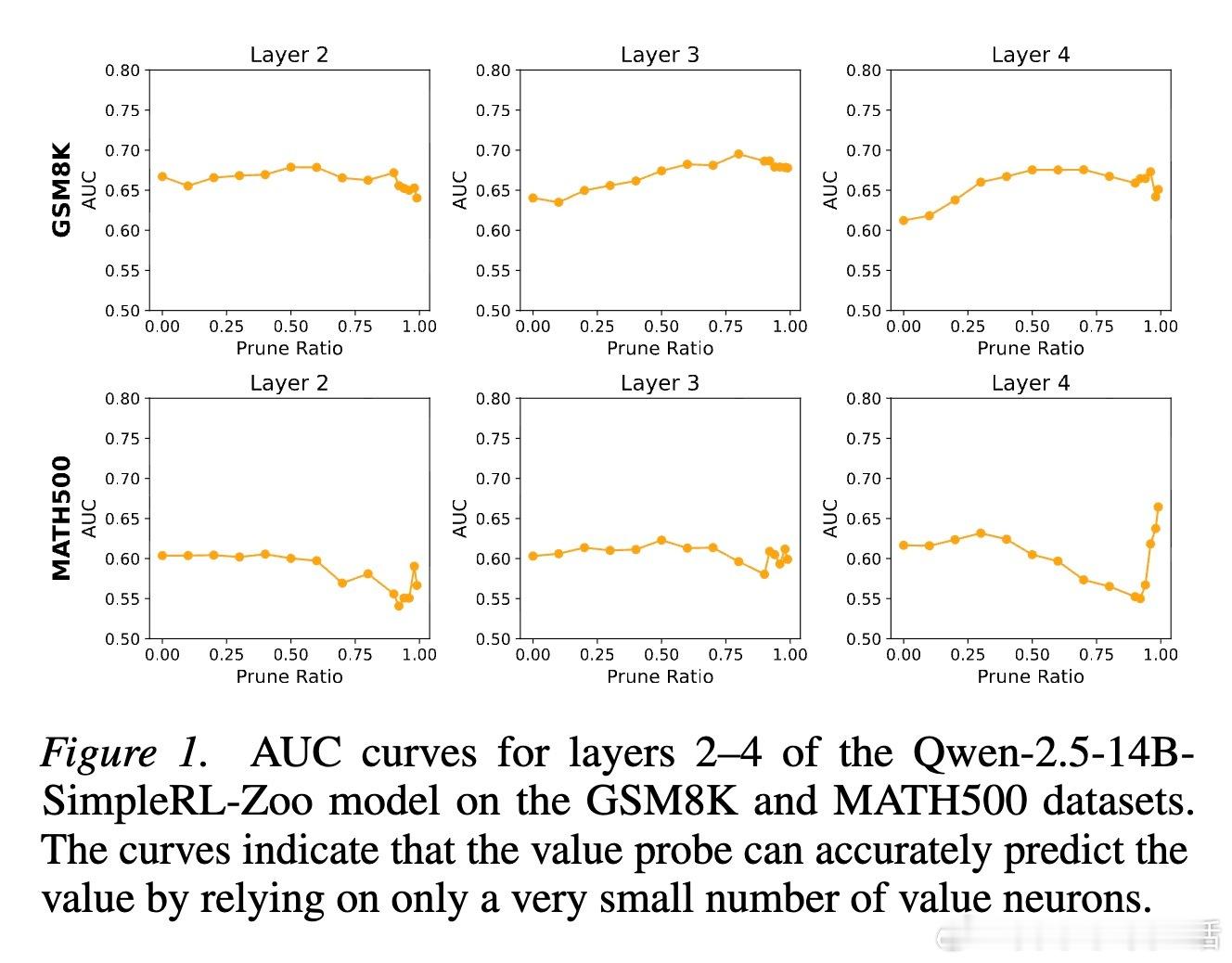
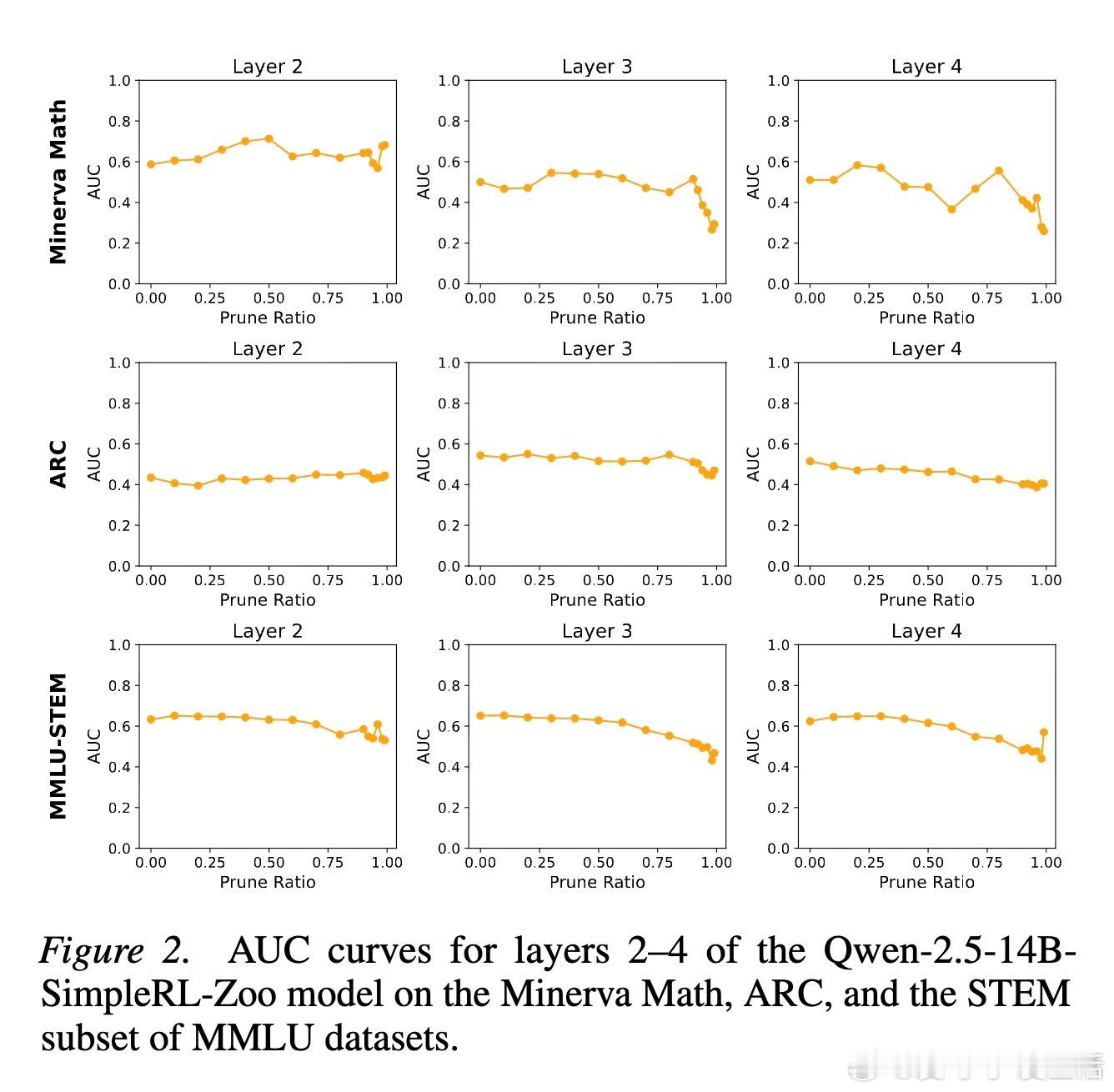
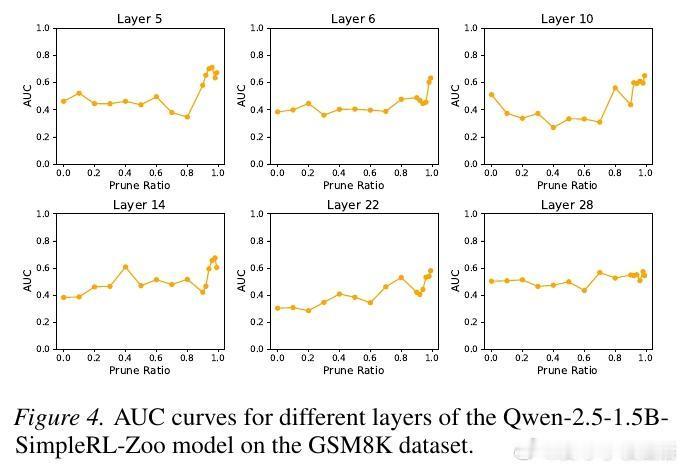
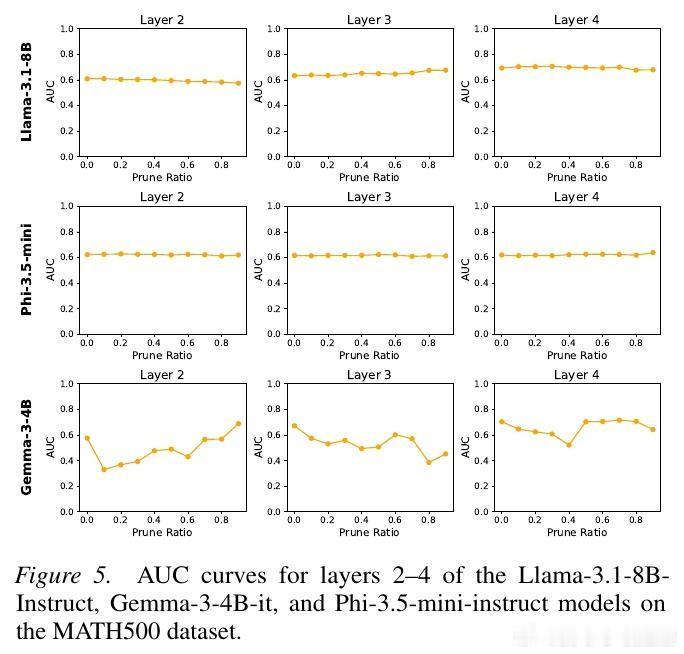
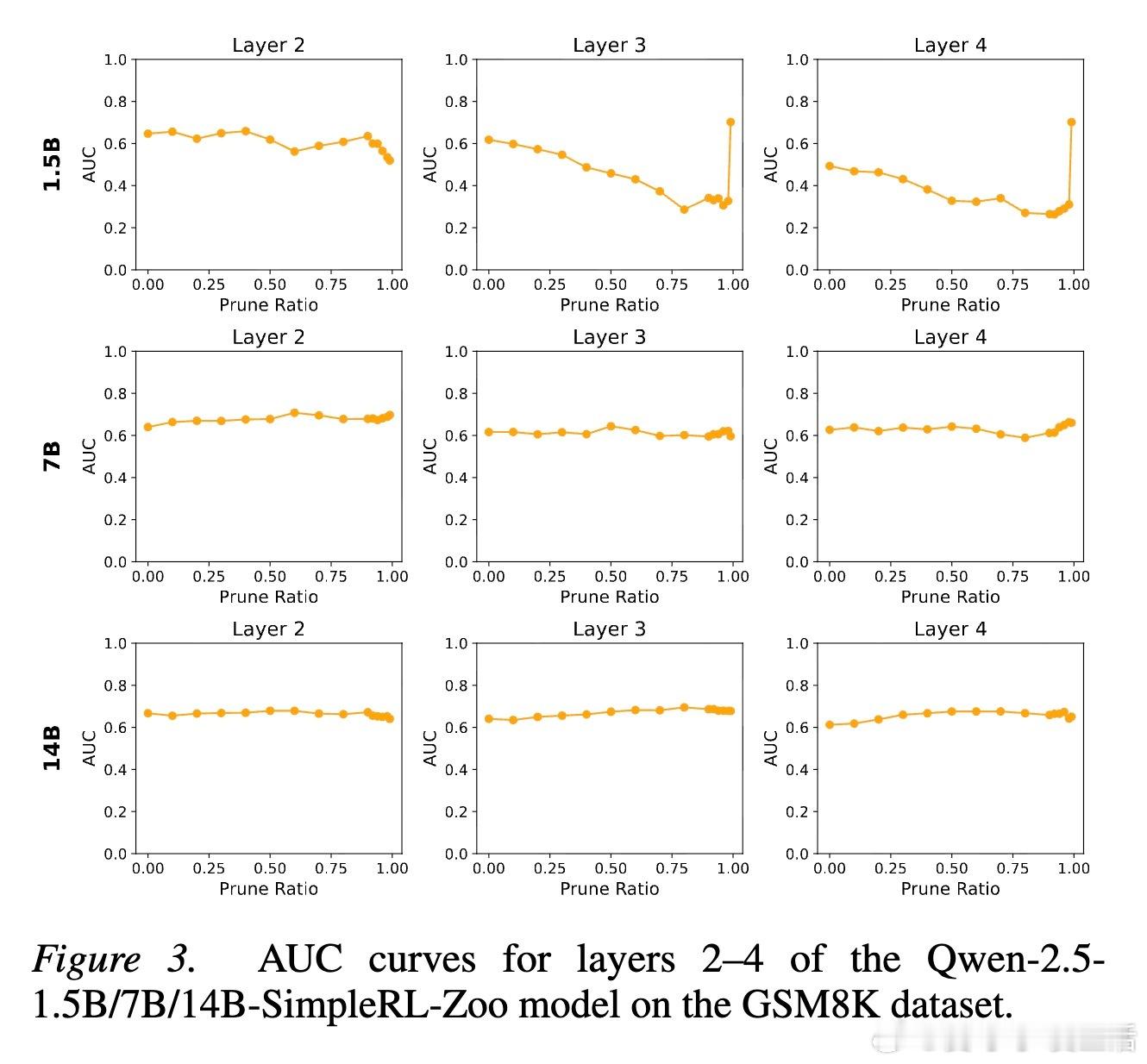
2. 价值神经元:模型心中的胜算研究者通过训练价值探针发现,LLM 内部存在一类专门代表价值预期的神经元。有趣的是,这些神经元极其稀疏。在成千上万个神经元中,只需提取不到 1% 的关键神经元,就能准确预测模型最终是否能解题成功。这种稀疏性说明,智能的本质往往掌握在极少数关键节点手中。
3. 致命的 1%:干预实验的启示为了验证这些神经元的重要性,研究者进行了干预实验。如果随机屏蔽 1% 的神经元,模型的推理能力几乎不受影响。但如果精准屏蔽这 1% 的价值神经元,模型的逻辑推理能力会瞬间崩塌。这意味着,价值预期不仅是结果的观察者,更是推理过程的参与者。没有了对目标的预期,逻辑就会迷失方向。
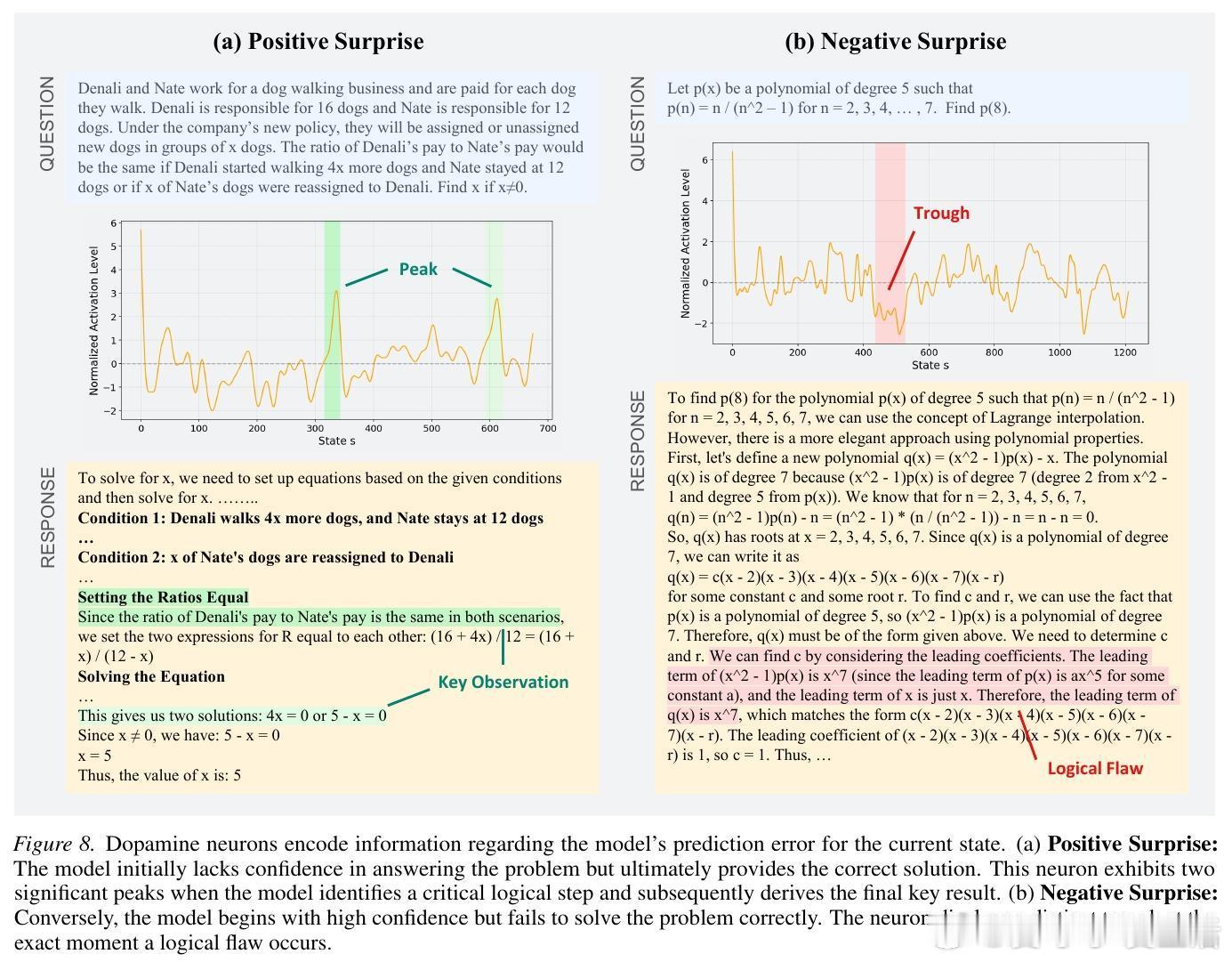
4. 多巴胺神经元:捕捉意外的惊喜与失落当模型的实际表现与内部预期发生偏离时,多巴胺神经元就会激活。当模型原本没信心但突然找到解题关键时,这些神经元会剧烈放电(正向惊喜);而当模型信心满满却在逻辑上踩坑时,其活跃度会跌至谷底(负向惊喜)。这种机制让模型在推理的每一步都能感知进步或挫败。
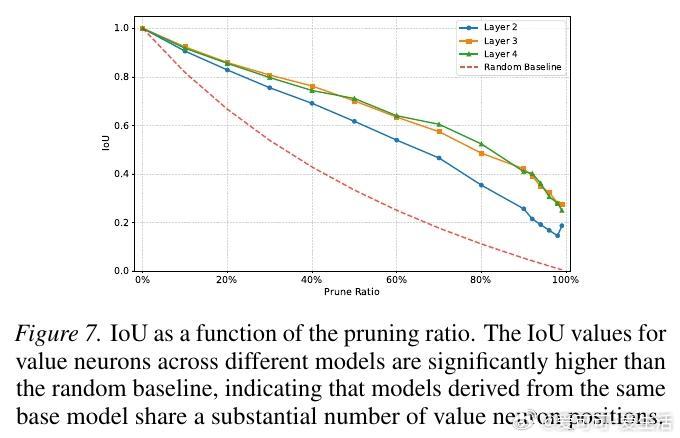
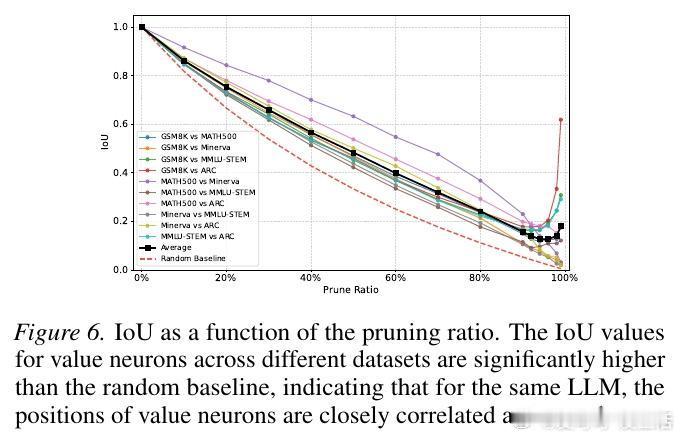
5. 跨越模型的普适规律这种奖励子系统并非某个模型的特例。实验证明,无论是 Qwen、Llama 还是 Phi 和 Gemma,无论模型规模大小,这种稀疏的奖励结构都稳定存在。更深层的发现是,基于同一基座微调出的不同模型,其价值神经元的位置高度重合。这说明,基础模型在预训练阶段就已经埋下了价值判断的种子。
6. 预知未来的能力:提前感知信心既然价值神经元在模型开口说话前就已经形成了评估,我们完全可以利用它来预测模型的置信度。相比于让模型自己说出我有多大把握,直接读取这些神经元的信号要准确得多。这为未来的自适应计算提供了可能:如果模型在动笔前就感知到难度极高,它可以自动分配更多的思考时间或计算资源。
深度思考:这项研究让我们意识到,LLM 不仅仅是统计意义上的下个 token 预测器。它在学习语言规律的同时,自发地构建了一套关于对错、难易和进步的内在度量衡。这种内在的奖励机制,或许就是模型能够进行复杂长链条推理的底层驱动力。
智能的进化,似乎总是从杂乱无章的关联,走向高度有序且稀疏的关键表征。理解了这 1% 的奖励子系统,我们也就握住了通往机械解释性的一把钥匙。
arxiv.org/abs/2602.00986