【姚顺雨入职腾讯后首发研究成果】姚顺雨最新研究成果 2月3日,腾讯混元官网技术博客(Tencent HY Research)上线并发表了一篇名为《从 Context 学习,远比我们想象的要难》的文章,系统介绍了腾讯混元团队联合复旦大学的一项新研究。
这是姚顺雨加入腾讯担任首席 AI 科学家后带领团队首次发布研究成果,也是腾讯混元技术博客首次公开。这一博客的推出,旨在分享腾讯混元研究员在前沿技术研究和实践中的探索与经验。
博客提到,过去几年,大语言模型的进化速度快得令人惊叹。如今的前沿模型,已经是顶级的“做题家”:它们能解开奥数级别的难题,能推演复杂的编程逻辑,甚至能通过那些人类需要苦读数年才能拿下的专业资格考试。
然而,这些耀眼的成绩单可能掩盖了一个真相:能在考场拿满分的学生,未必能胜任真实世界的工作。
回看我们人类的日常工作:开发者扫过从未见过的工具文档,就能立刻开始调试代码;玩家拿起新游戏的规则书,在实战中边玩边学;科学家从复杂的实验日志中筛选数据,推导出新的结论和定律。我们发现在这些场景中,人类并不只依赖多年前学到的“死知识”,而是在实时地从眼前的 Context 中学习。
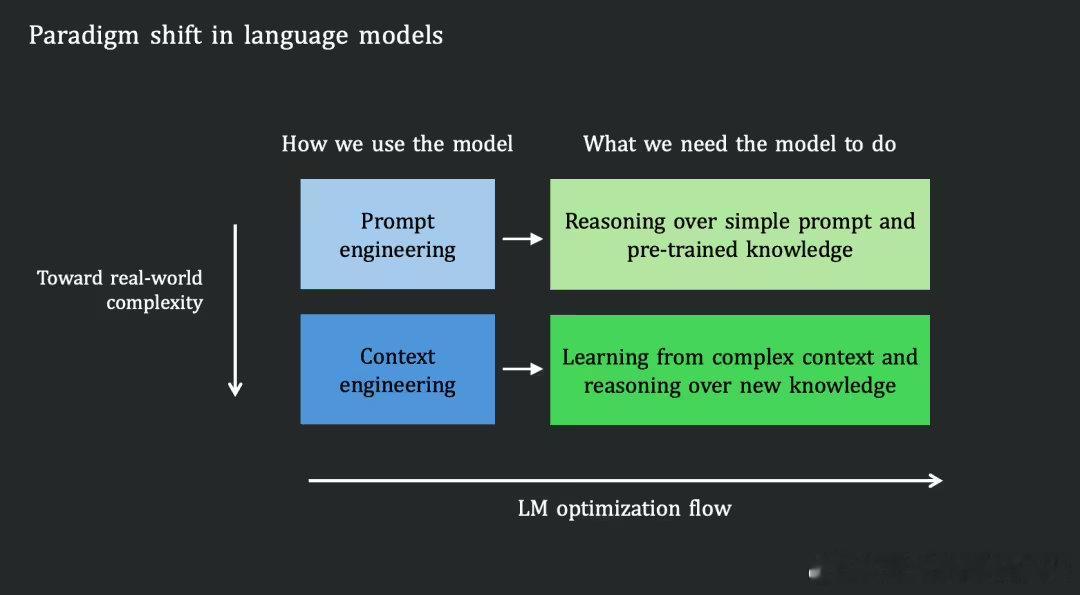
然而,今天的语言模型并非如此。它们主要依赖“参数化知识”—— 即在预训练阶段被压缩进模型权重里的静态记忆。在推理时,模型更多是在调用这些封存的内部知识,而不是主动从当前输入的新信息中汲取营养。
这揭示了当前模型的训练范式和在真实场景中应用之间是不匹配的:我们优化出的模型擅长对自己“已知”的事物进行推理,但用户需要的,却是让模型解决那些依赖于杂乱、动态变化的 Context 的任务。
简而言之:我们造出了依赖“过去”的参数推理者,但世界需要的是能吸收“当下”环境的 Context 学习者。要弥合这一差距,我们必须从根本上改变模型的优化方向。(IT之家)