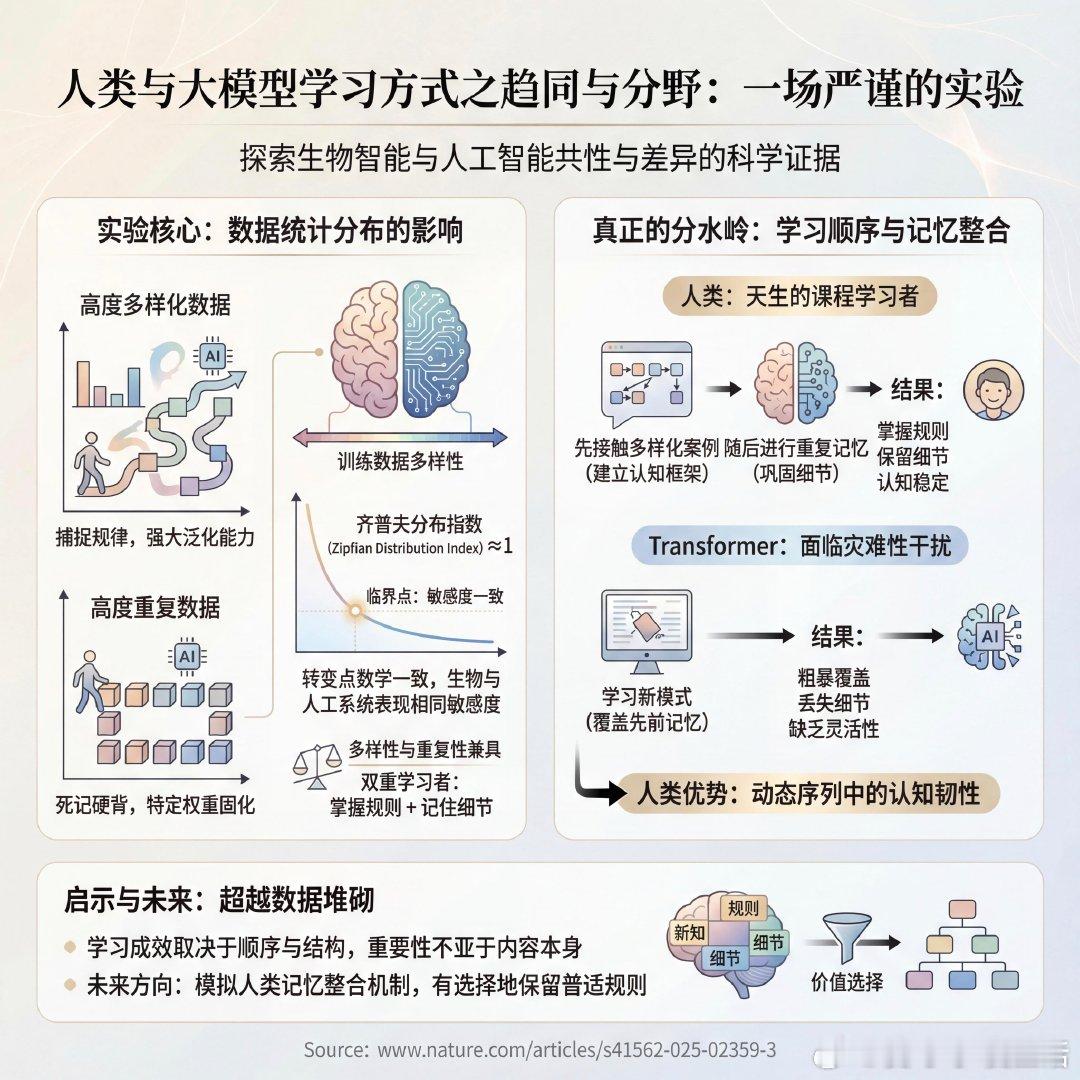
《Shared sensitivity to data distribution during learning in humans and transformer networks》人类与大模型的学习方式是否在本质上趋同?这不再仅仅是一个哲学命题,而是一场严谨的实验。研究者通过对530名人类受试者与小型Transformer网络进行相同的规则学习测试,揭示了生物智能与人工智能之间令人惊叹的共性与分野。实验的核心变量是训练数据的统计分布。当数据高度多样化时,人类和Transformer都能敏锐地捕捉到潜在规律,展现出强大的泛化能力,即在陌生情境下运用规则。而当数据高度重复时,两者都会转向死记硬背,将特定的例子刻进权重。这种行为的转变点在数学上高度一致。在齐普夫分布指数约为1的临界点,生物系统与人工系统表现出了几乎相同的敏感度。只有当数据分布兼具多样性与重复性时,两者才能进化为双重学习者,既掌握规则又记住细节。然而,真正的分水岭出现在学习的顺序上。人类是天生的课程学习者。如果我们先接触多样化的案例建立认知框架,随后再进行重复记忆,我们不仅能掌握规则,还不会丢失细节。相比之下,Transformer却面临灾难性干扰:新学到的模式往往会粗暴地覆盖掉先前的记忆。这意味着,学习的成效不仅取决于你学了什么,更取决于你以什么样的顺序去学。数据结构的重要性丝毫不亚于数据内容本身。人类的优势在于那种能在动态序列中保持认知稳定的韧性,而这正是目前AI所缺失的灵活性。深度学习的未来或许不在于堆砌更多的数据,而在于模拟人类的记忆整合机制。真正的智能不仅是记住一切,更是学会在摄取新知的同时,有选择地保留那些具有普适价值的规则。www.nature.com/articles/s41562-025-02359-3