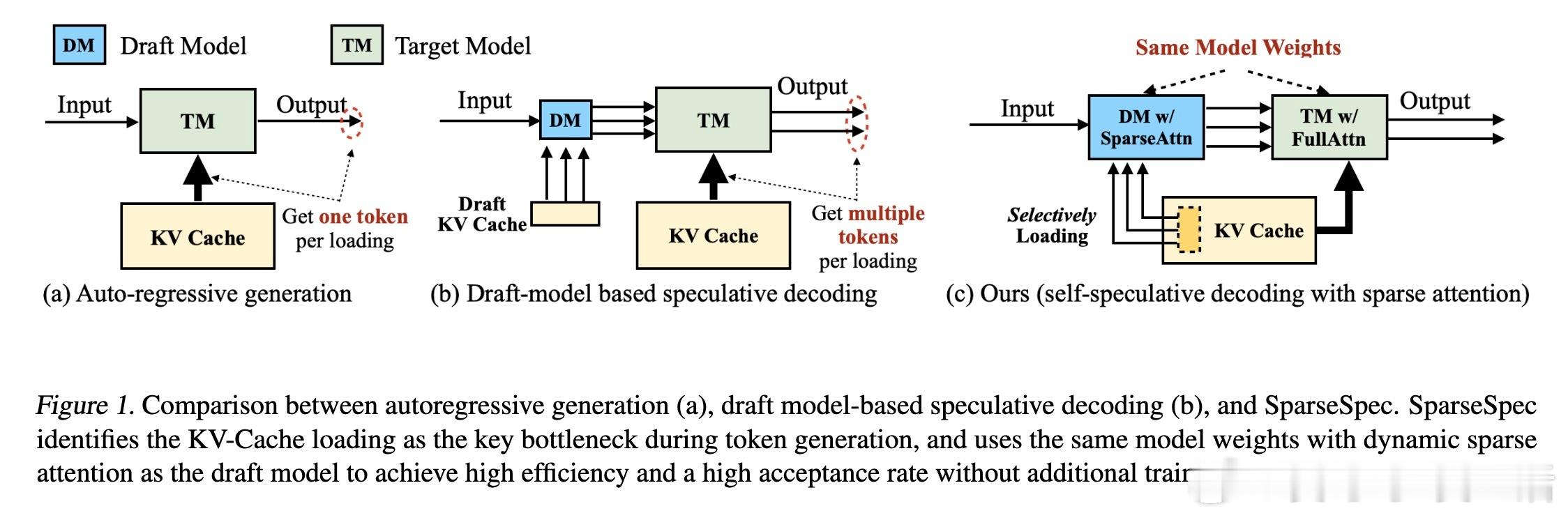
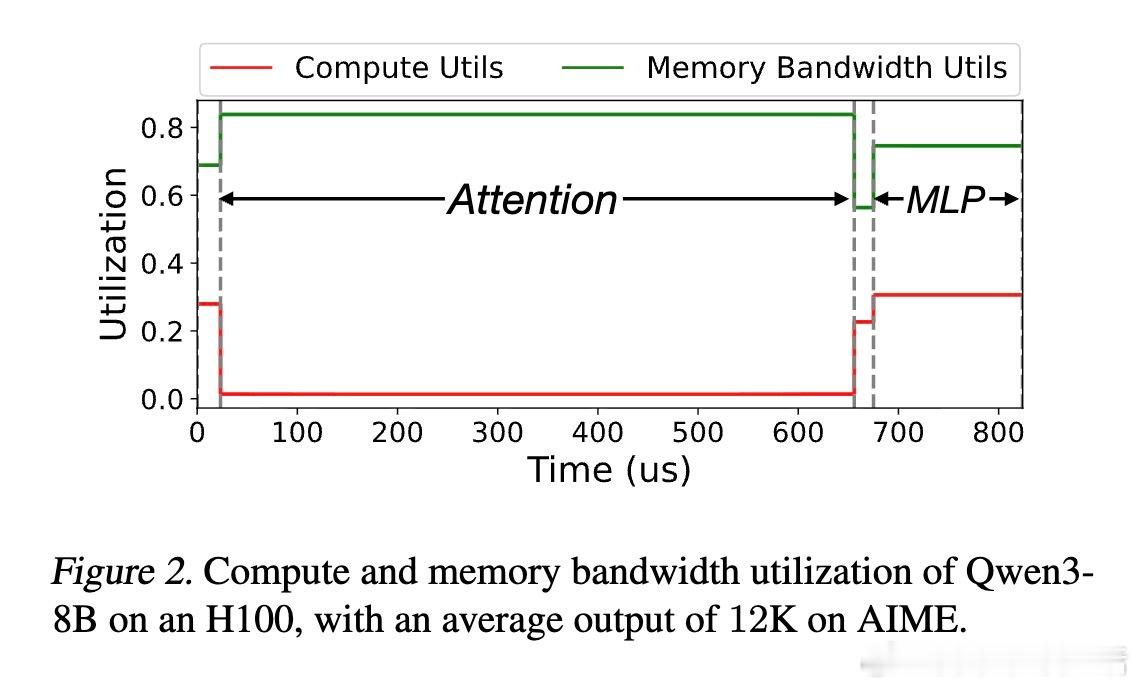
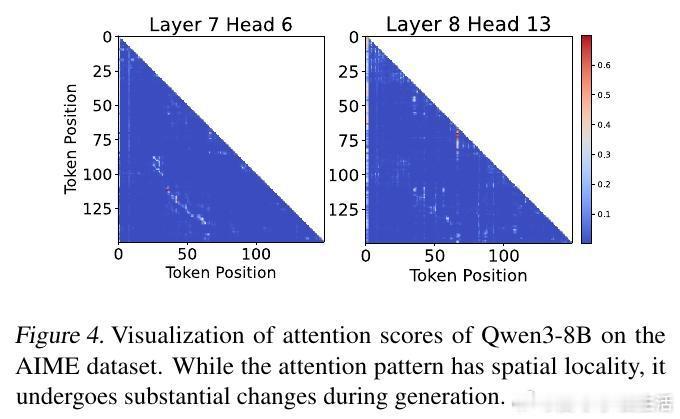
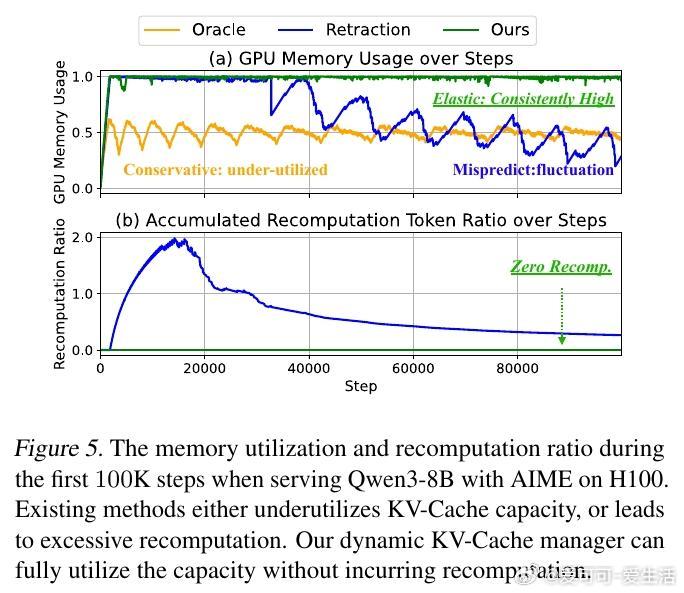
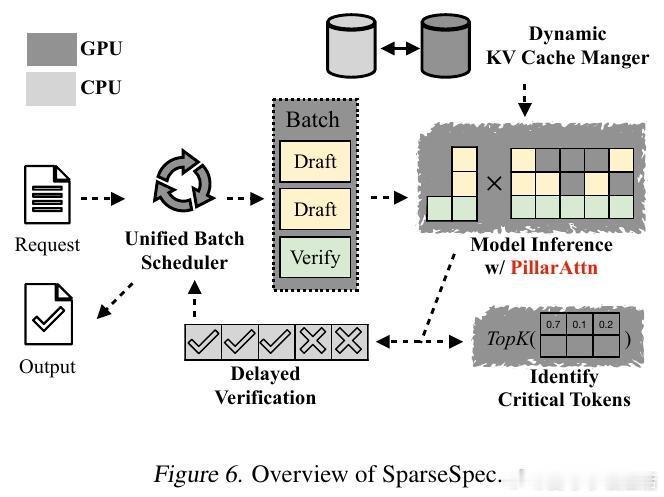
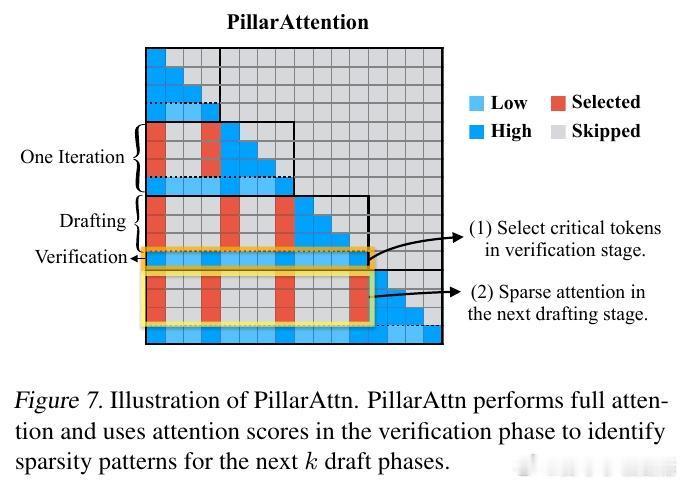
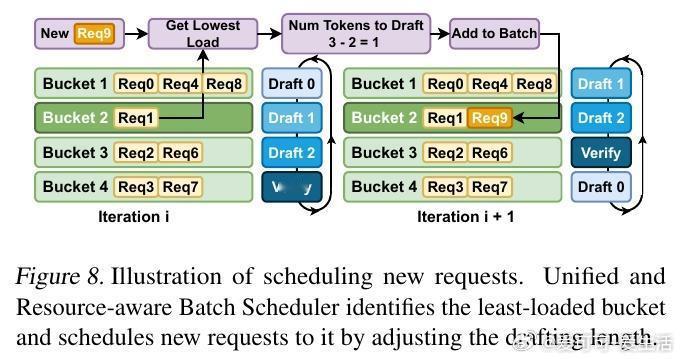
[LG]《Accelerating Large-Scale Reasoning Model Inference with Sparse Self-Speculative Decoding》Y Zhao, J Tang, K Zhu, Z Ye... [UC Berkeley & MIT & University of Washington] (2025) 随着推理语言模型(RLMs)在复杂任务中展现出卓越能力,其自动回归生成的长序列输出使推理瓶颈从计算转向内存带宽。每生成一个新词元,模型必须访问一个不断扩大的KV-Cache,导致内存访问呈二次方增长,严重制约了批量推理性能。为解决这一瓶颈,本文提出SparseSpec,一种无需额外训练、基于自我推测的稀疏注意力推理加速框架。SparseSpec创新设计了动态稀疏注意力机制PillarAttn,利用验证阶段(全注意力计算)中获得的注意力分数动态选取关键词元,实现高精度草稿生成。该机制不仅极大减少了KV-Cache访问量,还保持了极高的草稿接受率。除此之外,SparseSpec还联合设计了三大系统优化:统一批次调度器有效平衡草稿与验证阶段的资源使用,延迟验证机制打破CPU与GPU同步瓶颈,实现异步重叠计算,以及动态KV-Cache管理策略,允许高效地将缓存块异步卸载至主机内存,最大化GPU内存利用率。实测表明,SparseSpec在多个模型(包括Qwen3系列)和真实推理任务(如AIME、OlympiadBench、LiveCodeBench)上,较现有最优框架vLLM提升最高2.13倍吞吐量。与其他训练免费方法相比,吞吐率分别提升最高1.56倍至1.76倍。性能提升主要得益于PillarAttn精准的动态稀疏注意力和系统级的负载均衡设计。理论和实践均证明,稀疏自我推测能显著降低内存访问压力,提升长序列生成效率。SparseSpec的关键洞见在于充分利用推理模型自身的注意力分布动态,突破传统静态稀疏限制,实现“无训练开销”的高效加速。未来,SparseSpec可与多令牌预测等轻量级草稿方法结合,进一步推动推理模型在训练和部署阶段的性能极限。其设计理念和优化策略也对多专家模型(MoE)等架构具有良好适配性。总结一句话:在长序列推理时代,SparseSpec用动态稀疏自我推测开启了推理模型推理加速的新纪元,兼顾高效与无损,是推动大规模智能应用的关键技术突破。原文链接:arxiv.org/abs/2512.01278