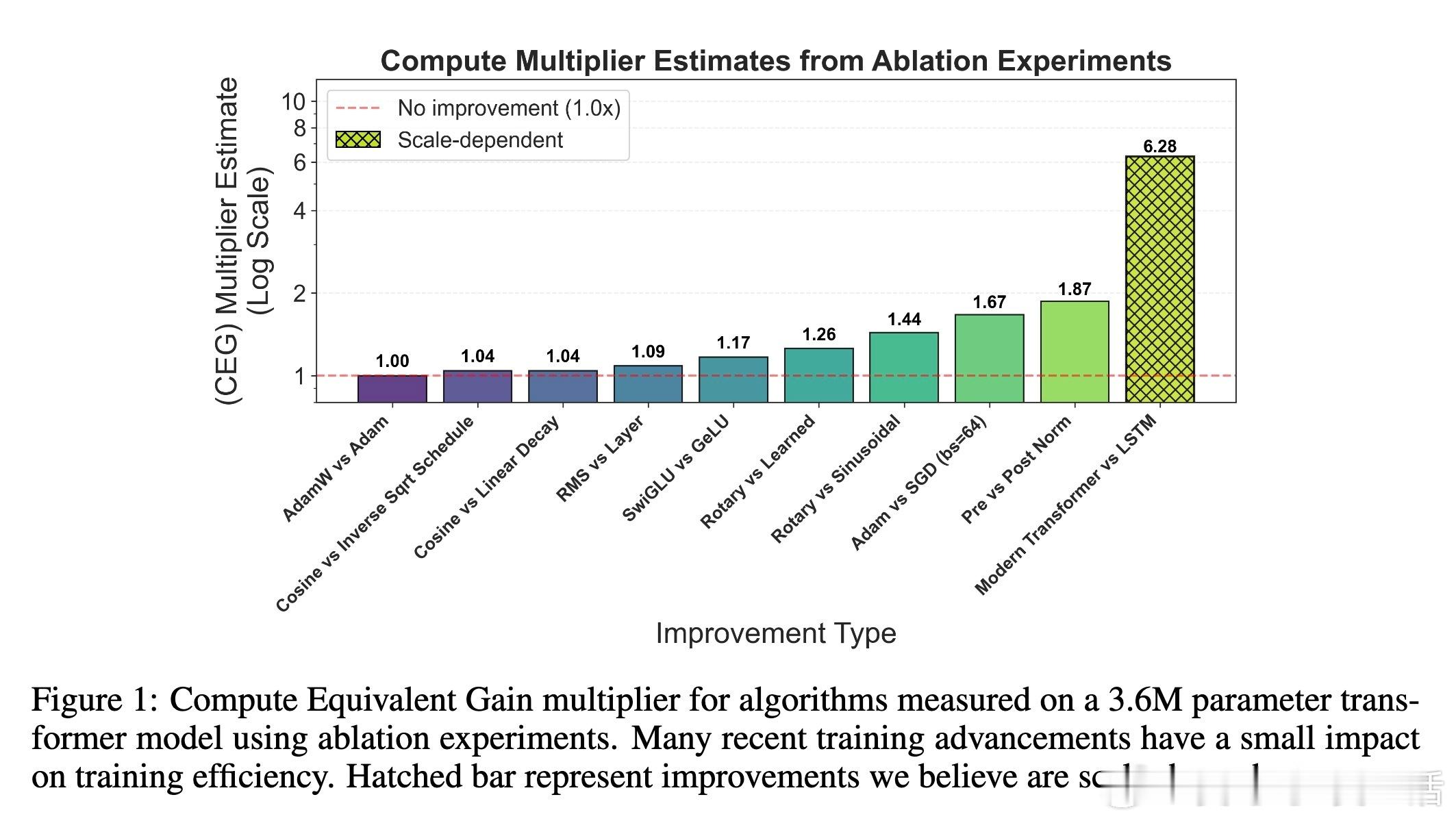
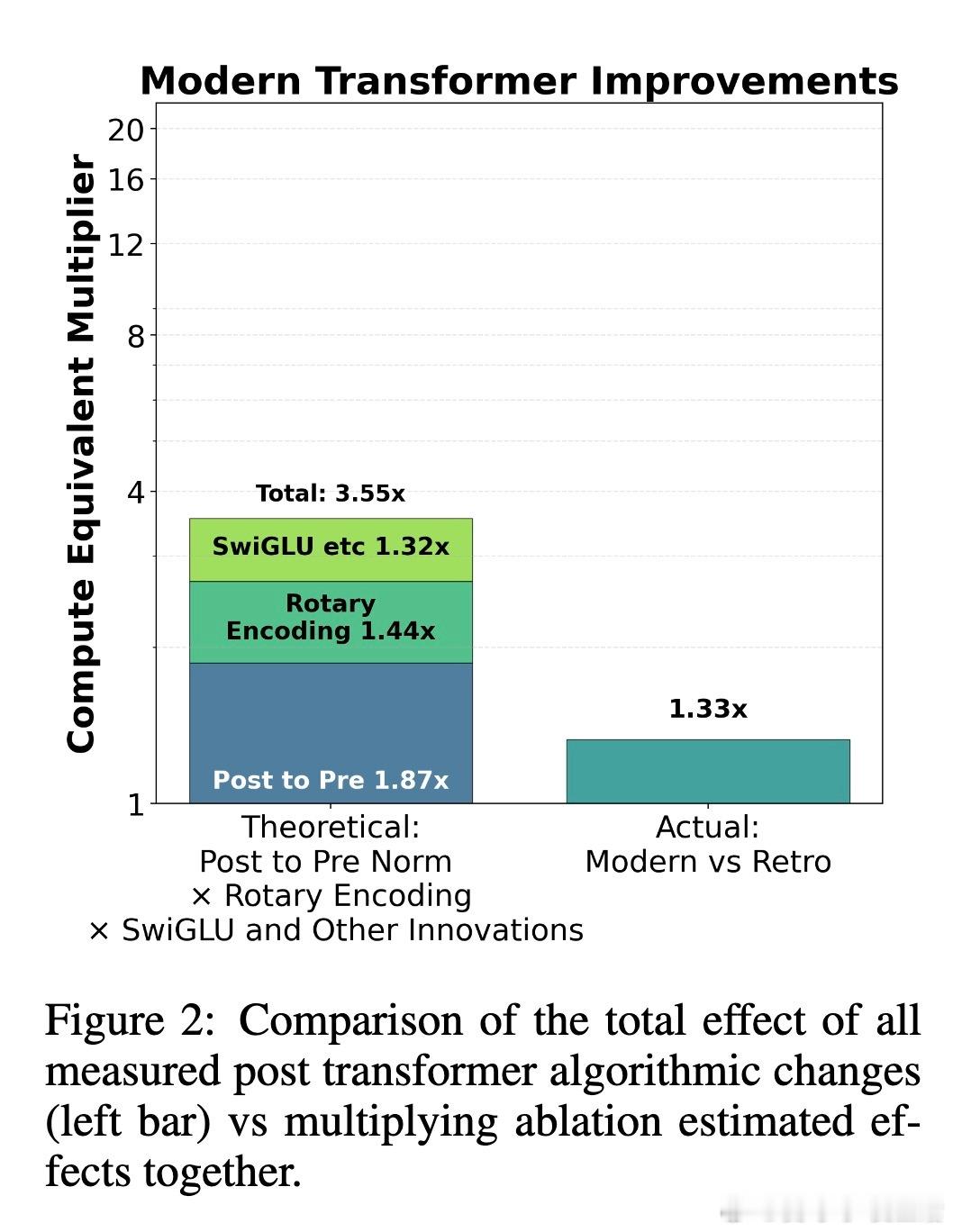
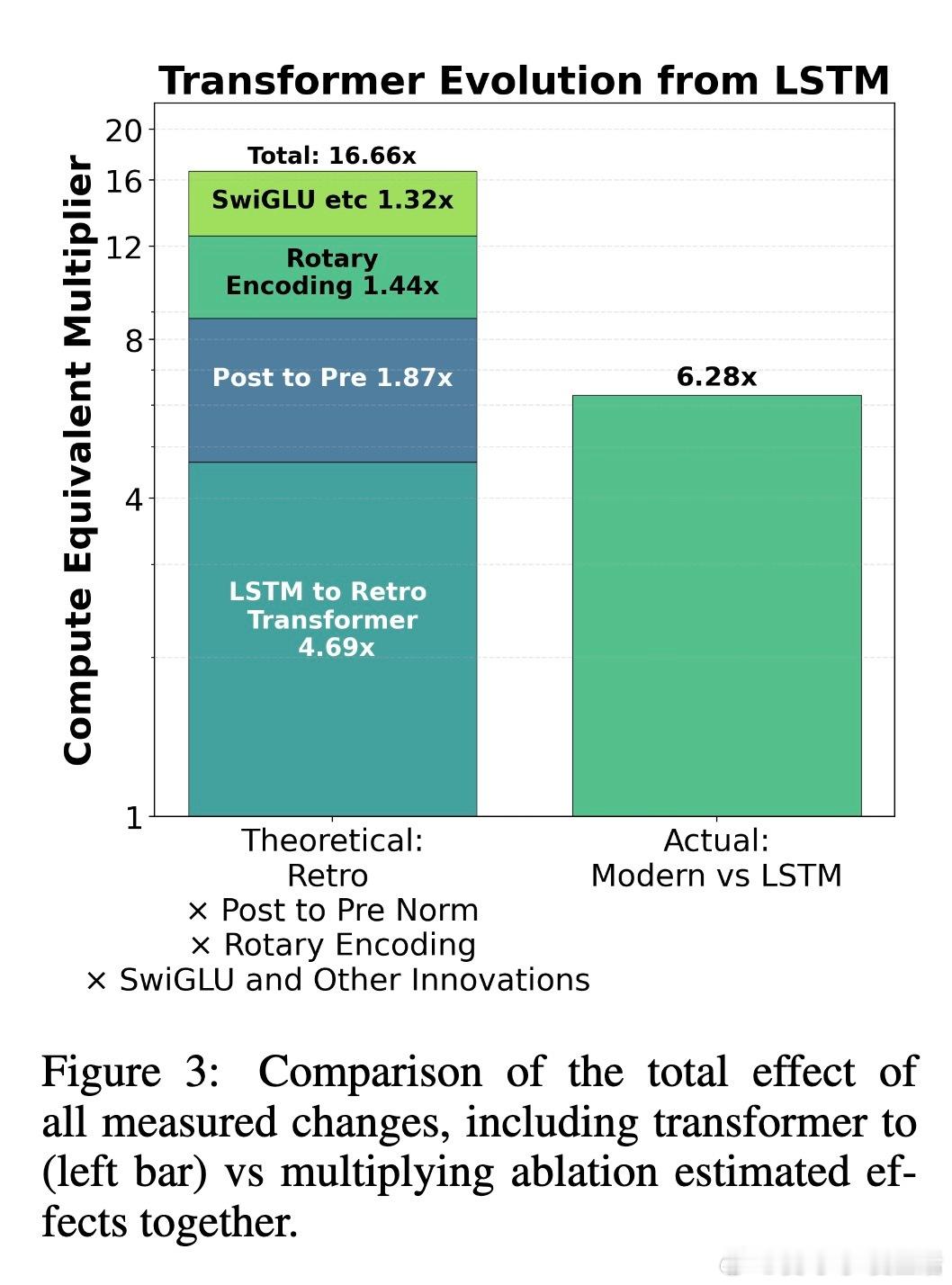
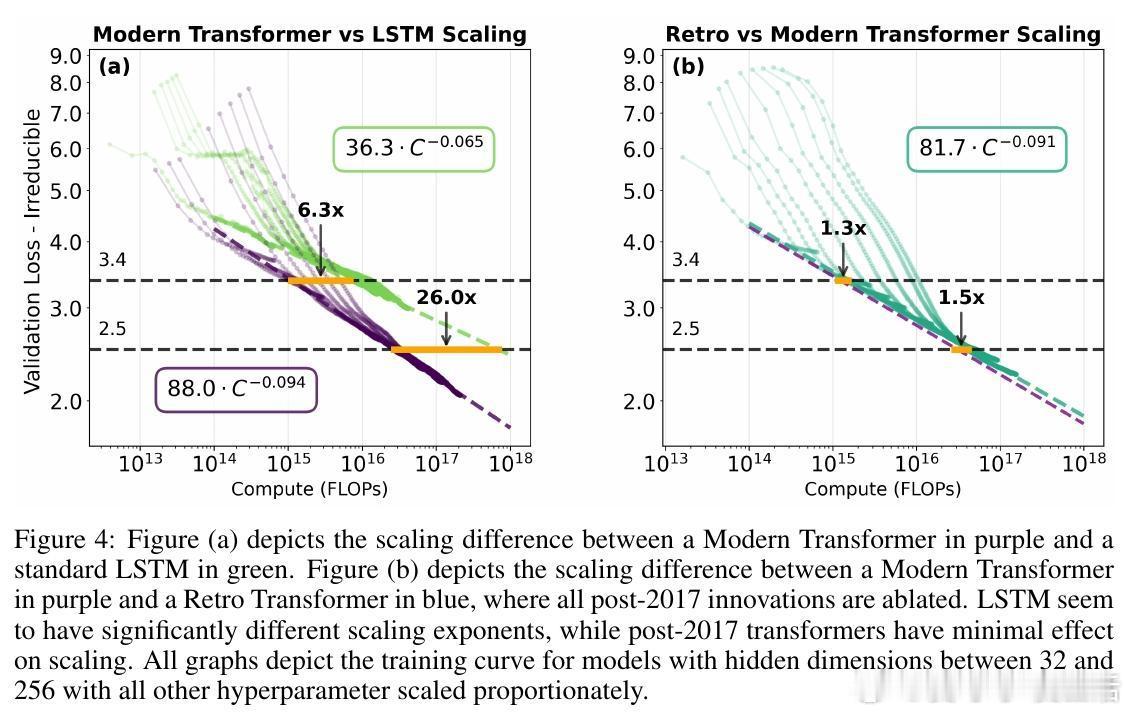
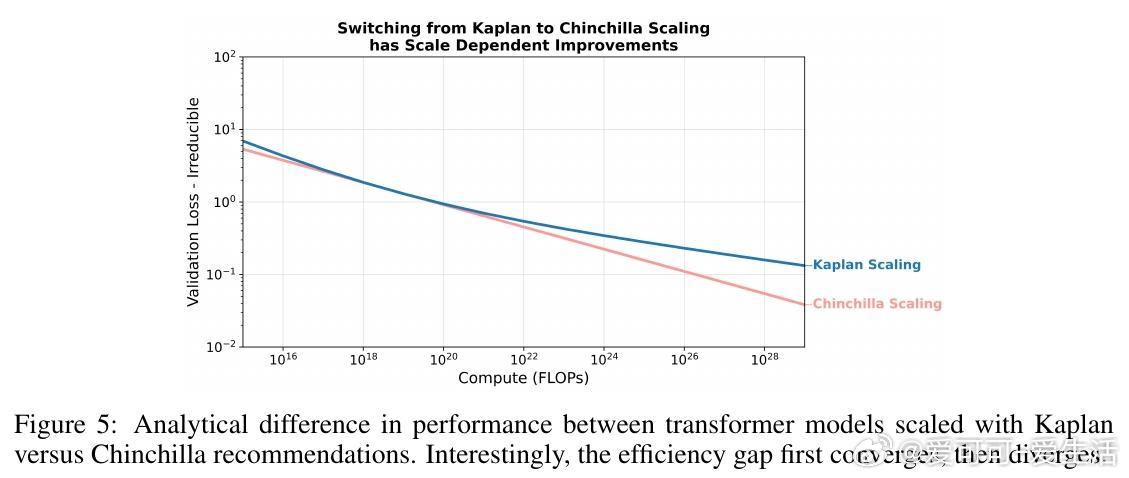
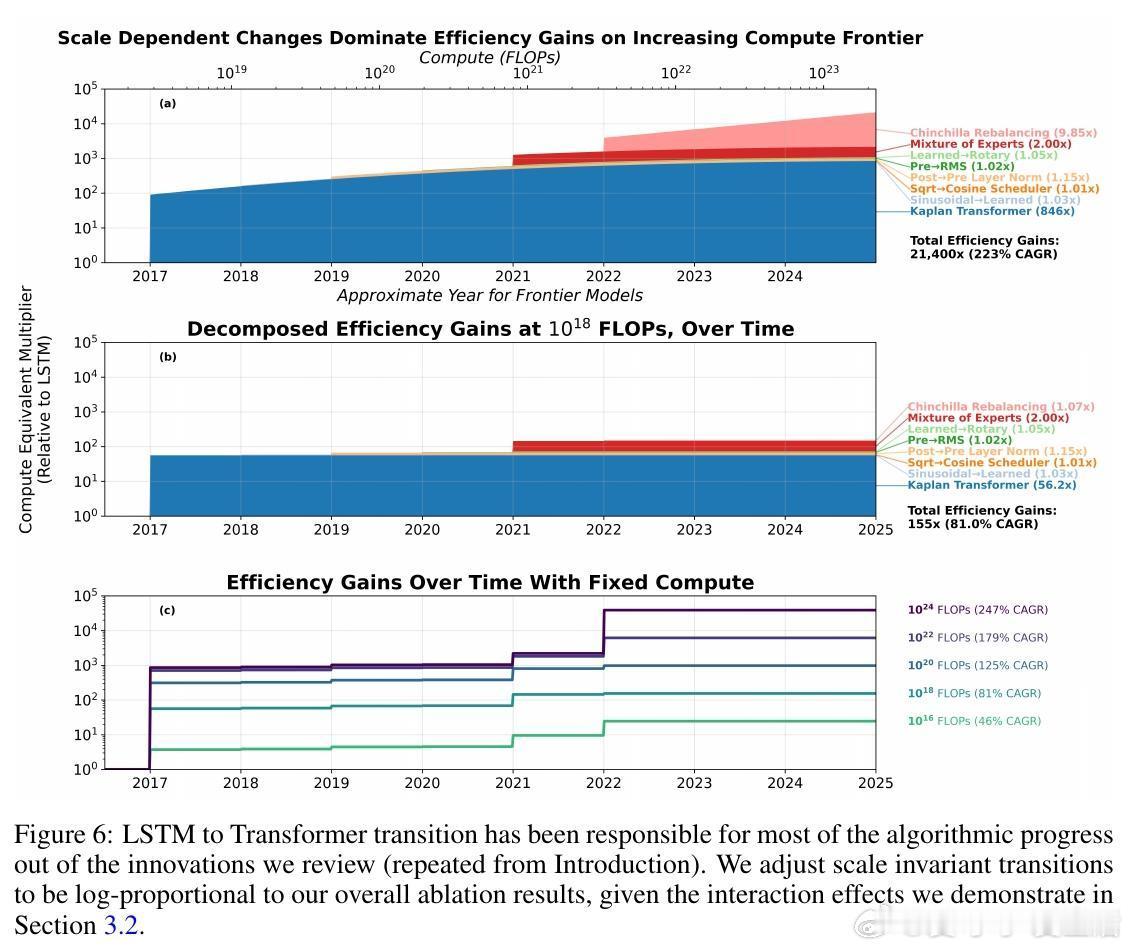
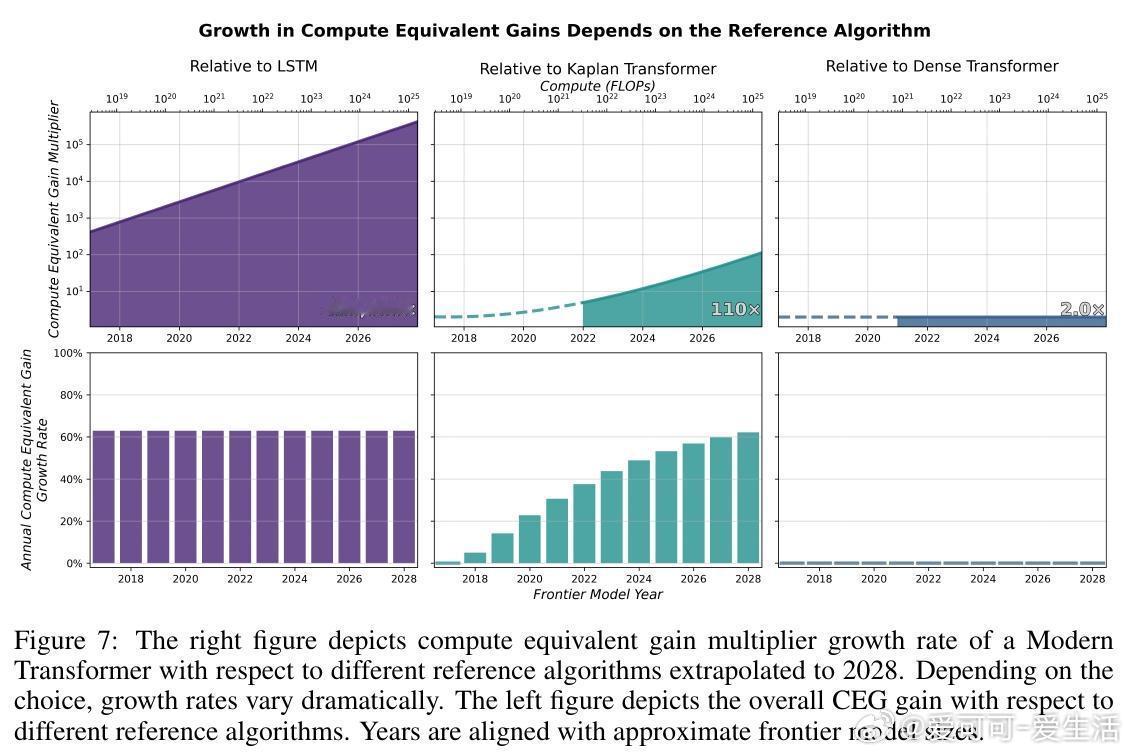
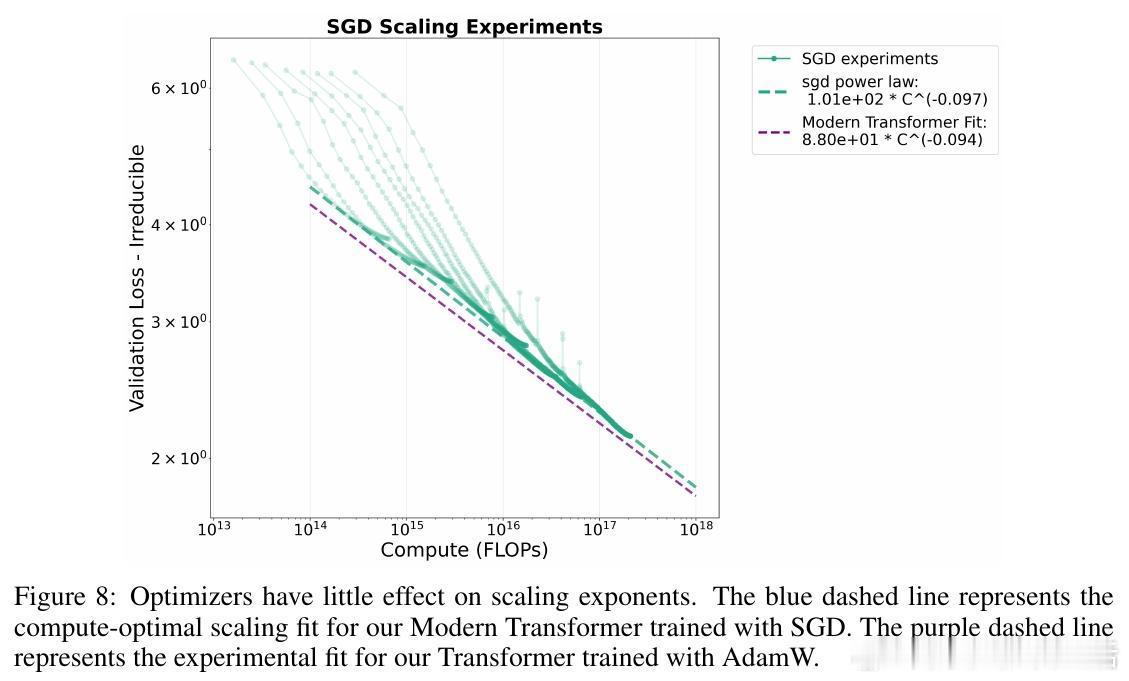
[LG]《On the Origin of Algorithmic Progress in AI》H Gundlach, A Fogelson, J Lynch, A Trisovic... [MIT FutureTech, CSAIL] (2025) 过去十年,AI算法效率被估计提升了2.2万倍,但我们的实验发现,关键创新的直接贡献不足10倍,文献中其他创新估计加起来也不到10倍,总计远低于此前预期。通过规模实验,我们发现大部分效率提升源自“规模依赖”算法,尤其是从LSTM到Transformer的架构转变,以及Kaplan到Chinchilla的规模重平衡,这两者合计解释了超过90%的效率跃升。本文提出了“计算等效增益函数”(CEG函数)概念,强调算法进步的效果强烈依赖于计算规模和参考算法。简单叠加小创新往往高估效益,且算法进步在小规模模型上表现缓慢,真正的飞跃出现在大规模时,这意味着大玩家从算法进步中获益更大。具体来看:- 绝大多数小规模模型上的算法改进(激活函数、位置编码、学习率调度、归一化、优化器)带来的效率提升有限,且相互作用并非乘法叠加。- LSTM与Transformer的比较显示,Transformer具有更优的计算扩展指数,规模越大优势越明显。- Kaplan到Chinchilla的训练数据与参数比例调整带来了显著的规模依赖性效率提升。- 不同参考点导致对算法进步的测量结果差异巨大:相对于LSTM,现代模型进步显著,但相对于现代Transformer,进步则微乎其微。- 算法效率提升不能脱离计算投入单独看,计算资源增长驱动了大部分所谓的算法进步。- 数据选择、Tokenizer改进、混合专家模型等也贡献了一定提升,但受限于实验规模难以精确量化。这意味着,未来AI算法进步可能更多依赖于新的大型架构突破,而非持续的小改进;同时算力限制可能阻碍算法进步的实现。算法创新对大规模模型开发者尤为关键,可能加剧玩家间差距。我们也提醒不要简单依赖单一的FLOP效率指标,而应综合考虑稳定性、泛化能力和部署成本等多维度因素。总之,算法进步的真相是:规模改变游戏规则,真正的质变在于“规模依赖”的架构跃迁,而非线性叠加的微小优化。这为AI未来的发展路径和资源投入提供了新的视角和警示。全文详见:arxiv.org/abs/2511.21622