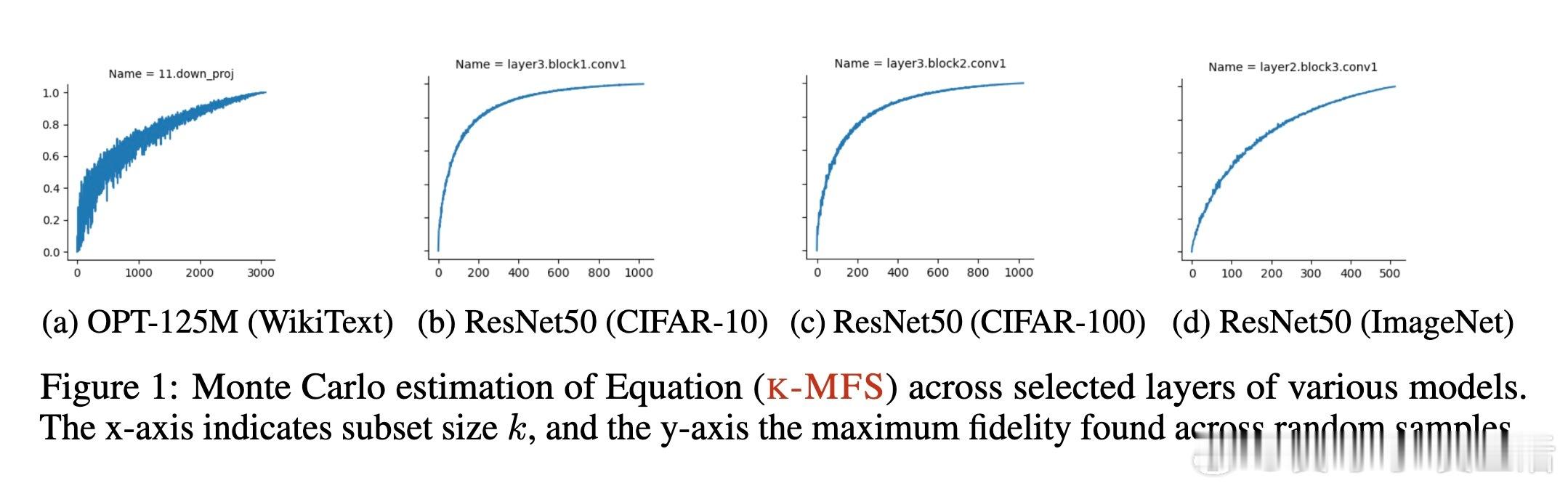
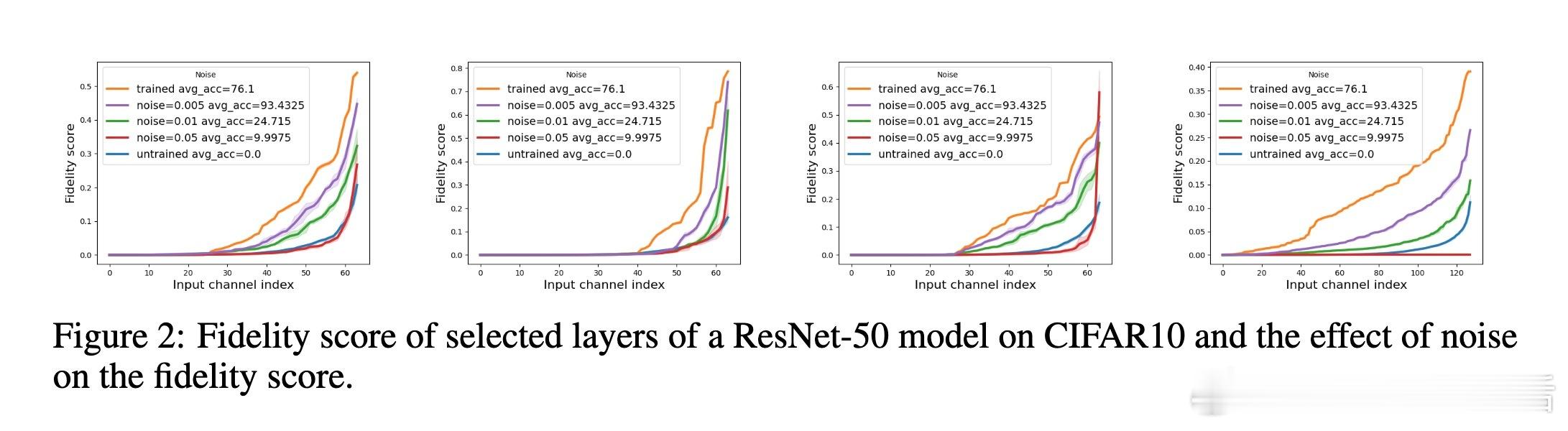
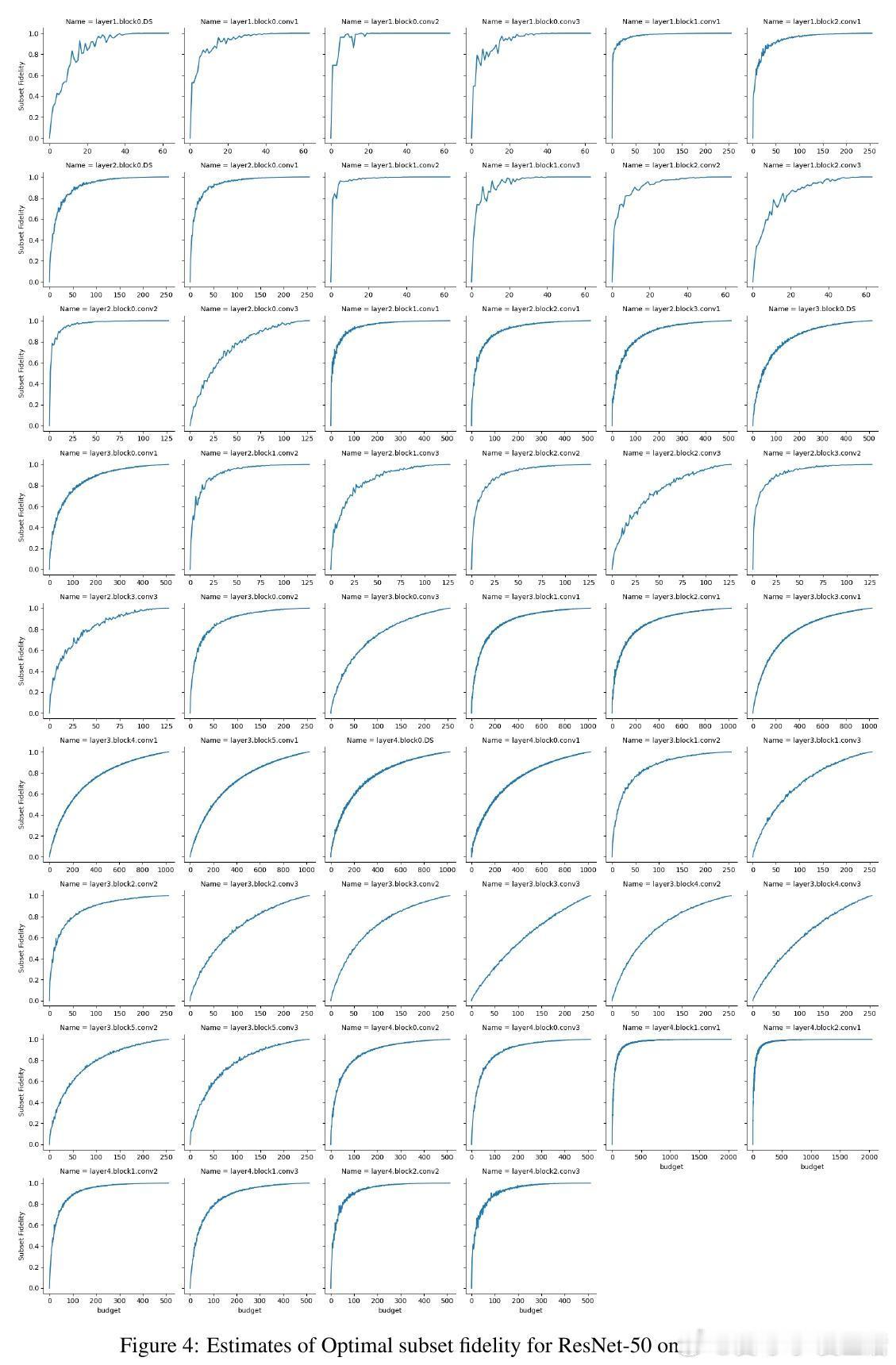
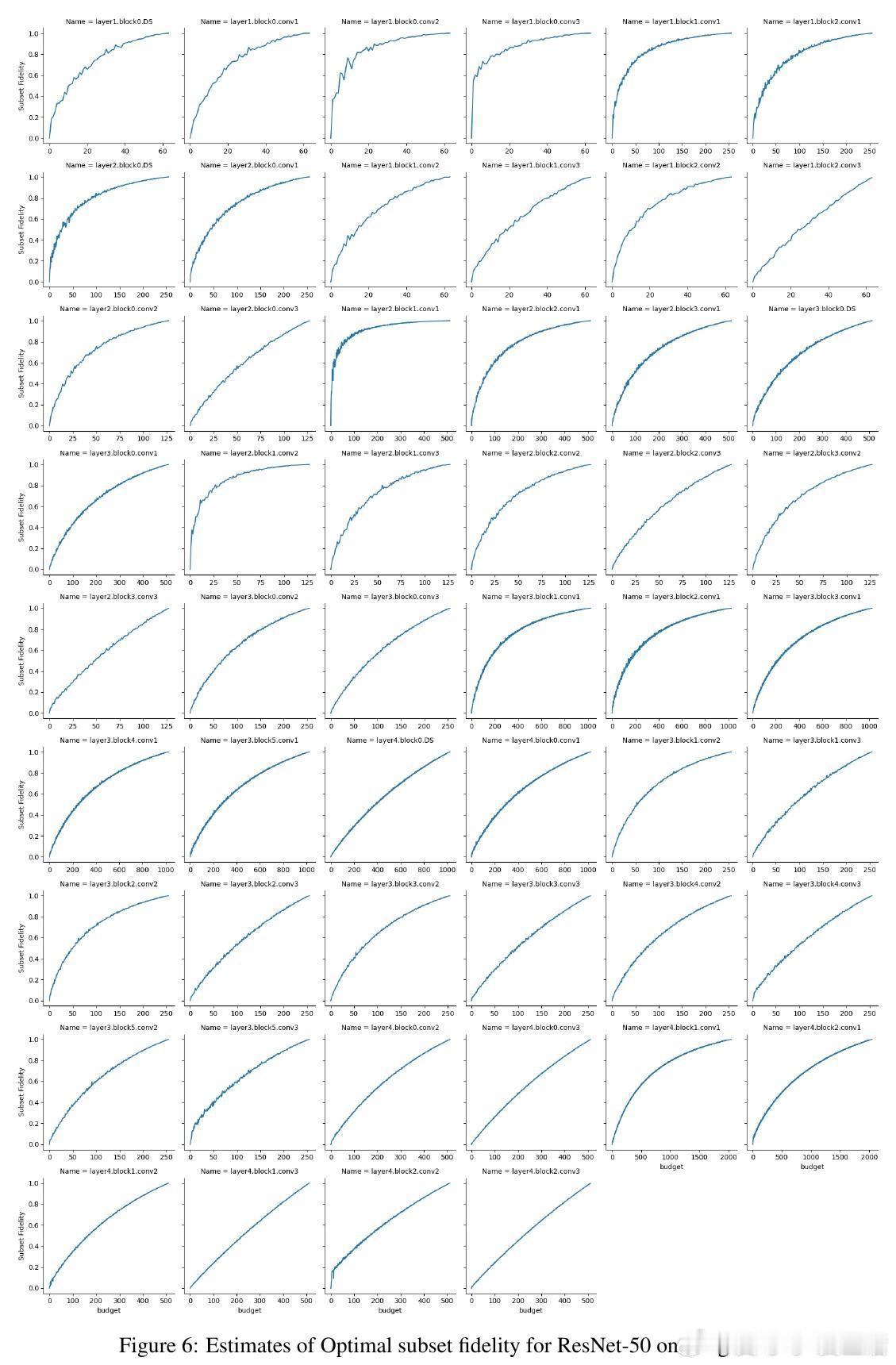
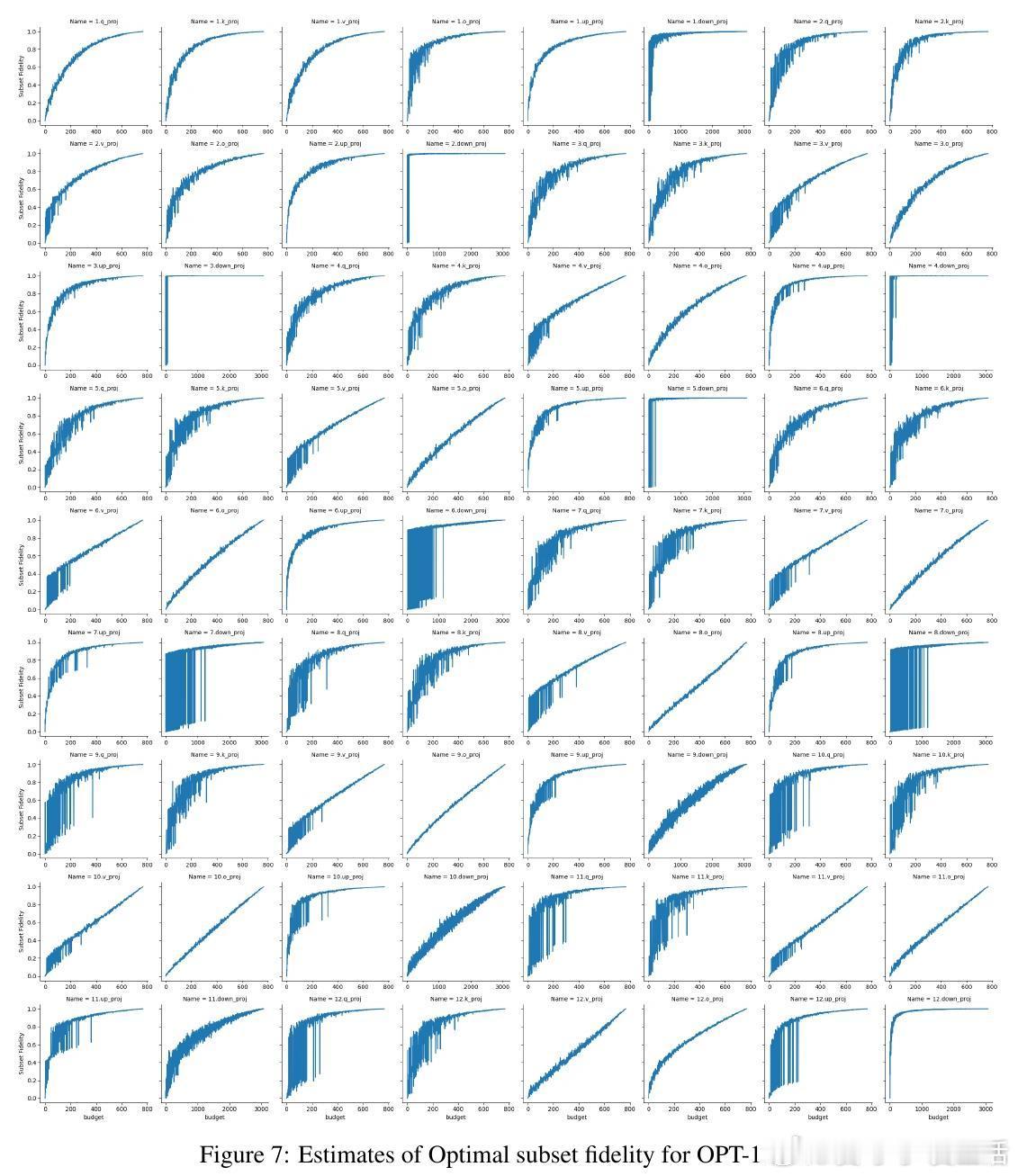
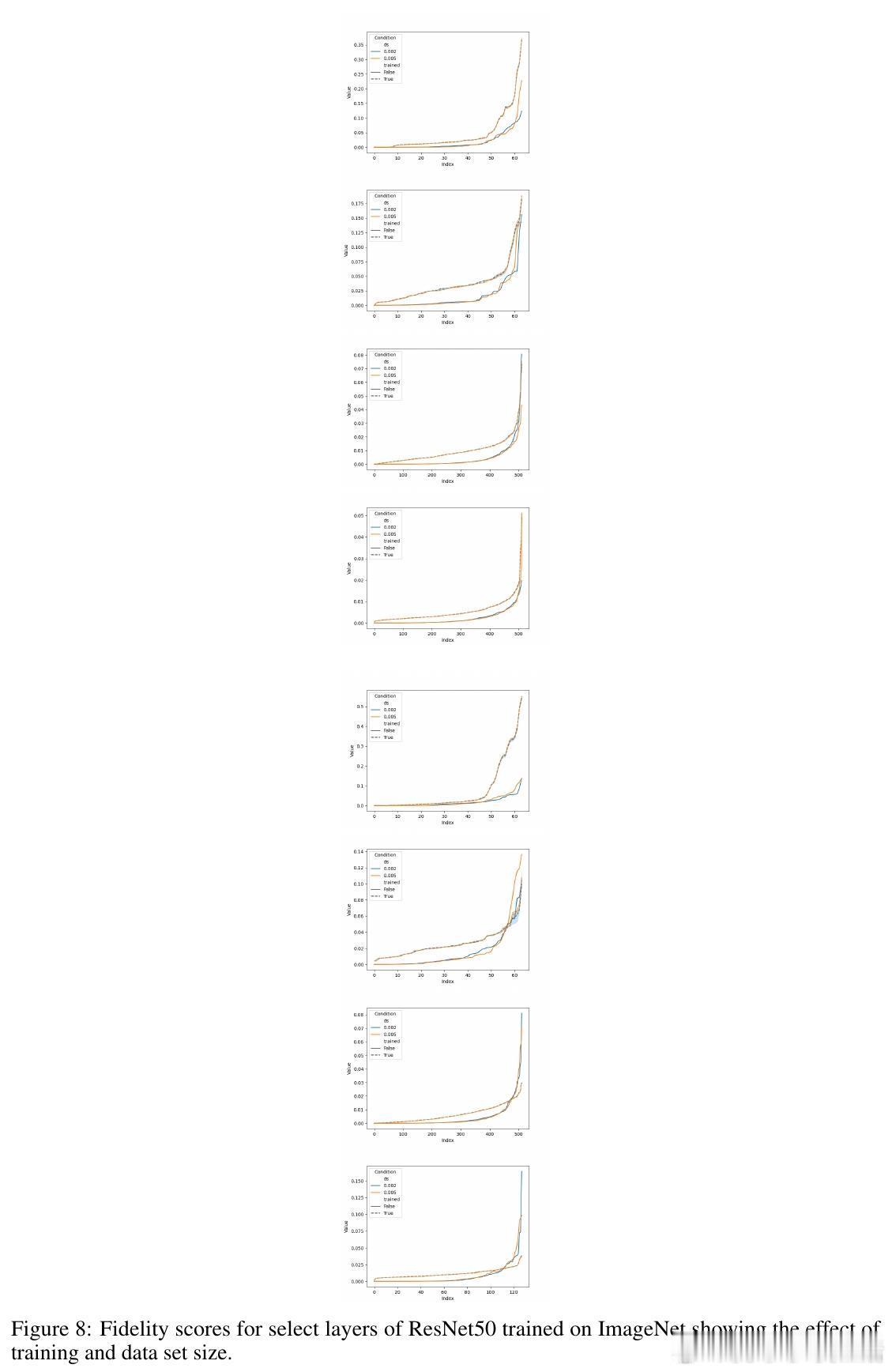
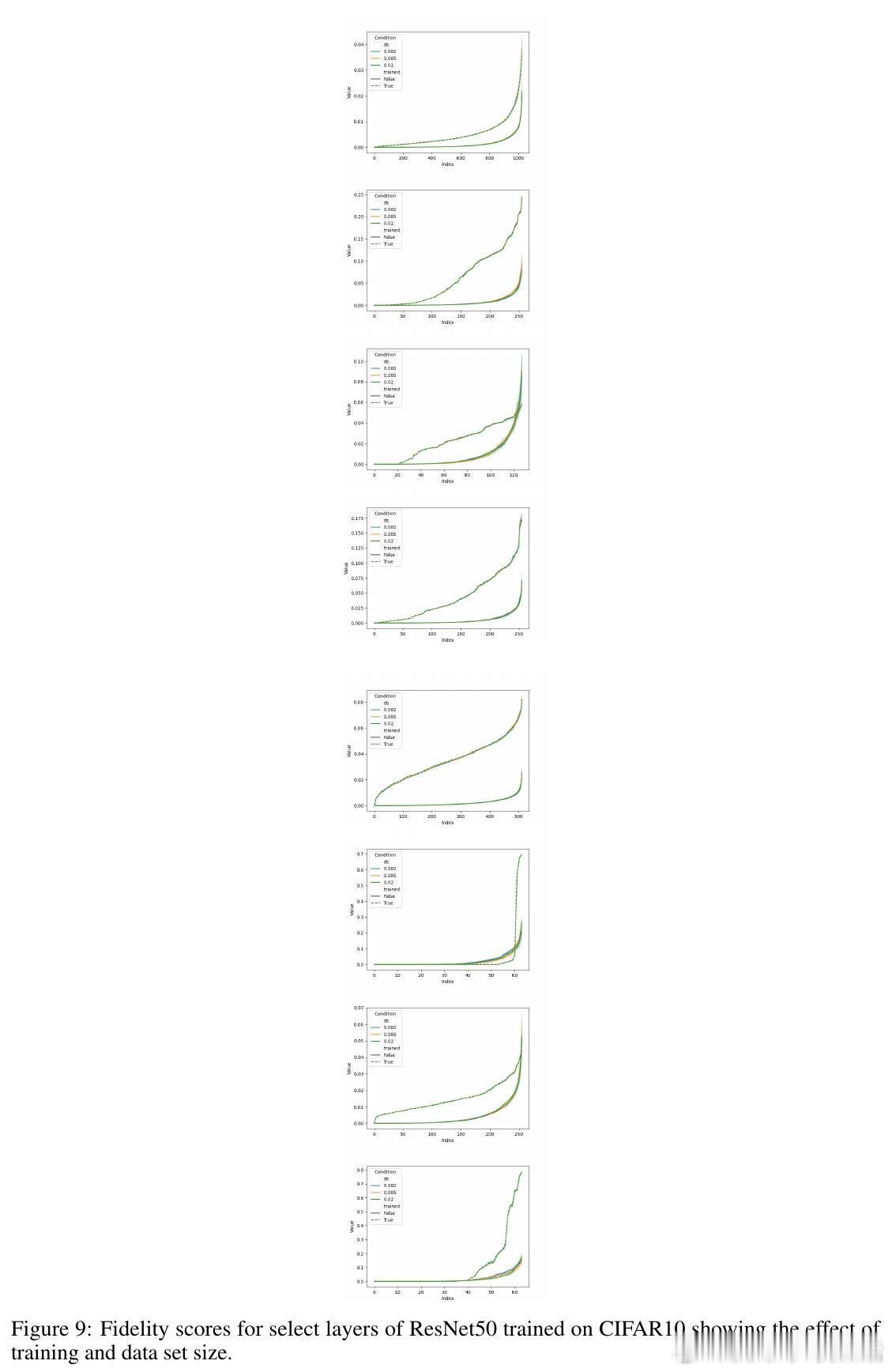
[LG]《ModHiFi: Identifying High Fidelity predictive components for Model Modification》D Kashyap, C Murti, P K Nayak, T Narshana... [CSA, IISc & HP Inc. AI Lab & Google] (2025) 在当今深度学习模型广泛应用的背景下,如何在缺乏原始训练数据与损失函数的情况下,有效地修改预训练模型成为一个重要且具有挑战性的问题。本文针对这一难题,提出了一套创新性的理论与算法框架,助力模型剪枝与类忘记(classwise unlearning)等任务,且仅需合成数据的分布访问权限,无需梯度或标签信息。核心贡献包括:1. 局部到全局误差界定的理论基础 作者证明了,对于具有Lipschitz连续性的神经网络(包括卷积神经网络和经过充分训练的Transformer模型),模型整体的重构误差可以被层内局部重构误差的线性组合有效上界。这一重要发现为利用局部层级信息估计全局预测性能提供了理论支持。2. 高保真(HiFi)组件及子集保真度(Subset Fidelity)指标 论文定义了“子集保真度”指标,用以评估模型中某一组件子集在重构当前层输出时的能力。理论上,在输入贡献彼此不相关的理想情况下,选取单个组件的保真度分数最高的集合即为最优选择。该指标不仅为组件重要性提供了量化标准,也支持贪心算法的有效性。3. ModHiFi算法框架 基于上述指标,论文提出ModHiFi算法,分别针对结构化剪枝(ModHiFi-P)和类忘记(ModHiFi-U)任务。该方法通过计算单组件保真度分数,识别关键组件,再根据任务需求有选择地保留或移除这些组件。实验证明,ModHiFi-P在ImageNet视觉任务上实现了11%的速度提升,且在大型语言模型剪枝中表现竞争力;而ModHiFi-U在CIFAR-10数据集上的类忘记任务无需微调即可实现完全忘记,且在Swin Transformer上表现优异。4. 广泛的实验验证 通过对ResNet、VGG、Swin Transformer以及Llama-2-7B等多种模型的实验,系统展示了HiFi组件的存在性、重要性与修改效果。特别地,实验表明仅需合成数据即可准确估计保真度,验证了算法在无原始训练数据场景下的实用性。5. 实用性与通用性 ModHiFi算法架构无模型架构限制,支持卷积网络与Transformer,适应视觉与自然语言处理任务,且无需访问训练标签或损失函数,极大地拓展了模型修改的应用场景,尤其适合隐私保护与合成数据驱动的现代部署环境。深刻启示:模型预测能力往往集中于少数“高保真”组件,这种稀疏而关键的结构不仅启示了更高效的模型压缩路径,也为定向的模型行为编辑提供了理论与实践基础。在没有原始数据和损失函数的限制下,依赖于合成数据的分布式访问,仍能实现精准且高效的模型修改,揭示了深度模型内部表达的分布式与可解释特性。本工作为模型修改领域开辟了新思路,尤其是其理论对Lipschitz连续性的重新审视,纠正了现有关于Transformer非Lipschitz性质的误解,推动了统一的模型分析框架的发展。论文代码已开源,支持研究者复现与扩展:github.com/DhruvaKashyap/modhifi详细阅读请见论文全文:arxiv.org/abs/2511.19566