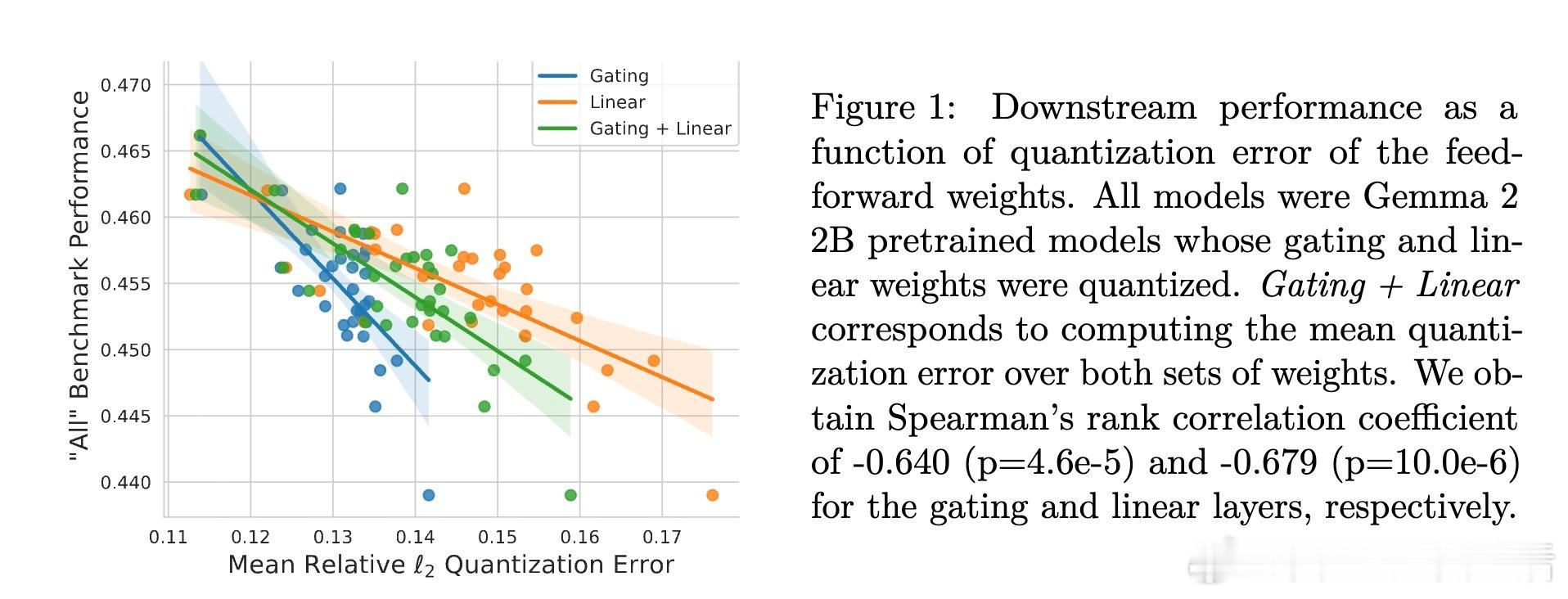
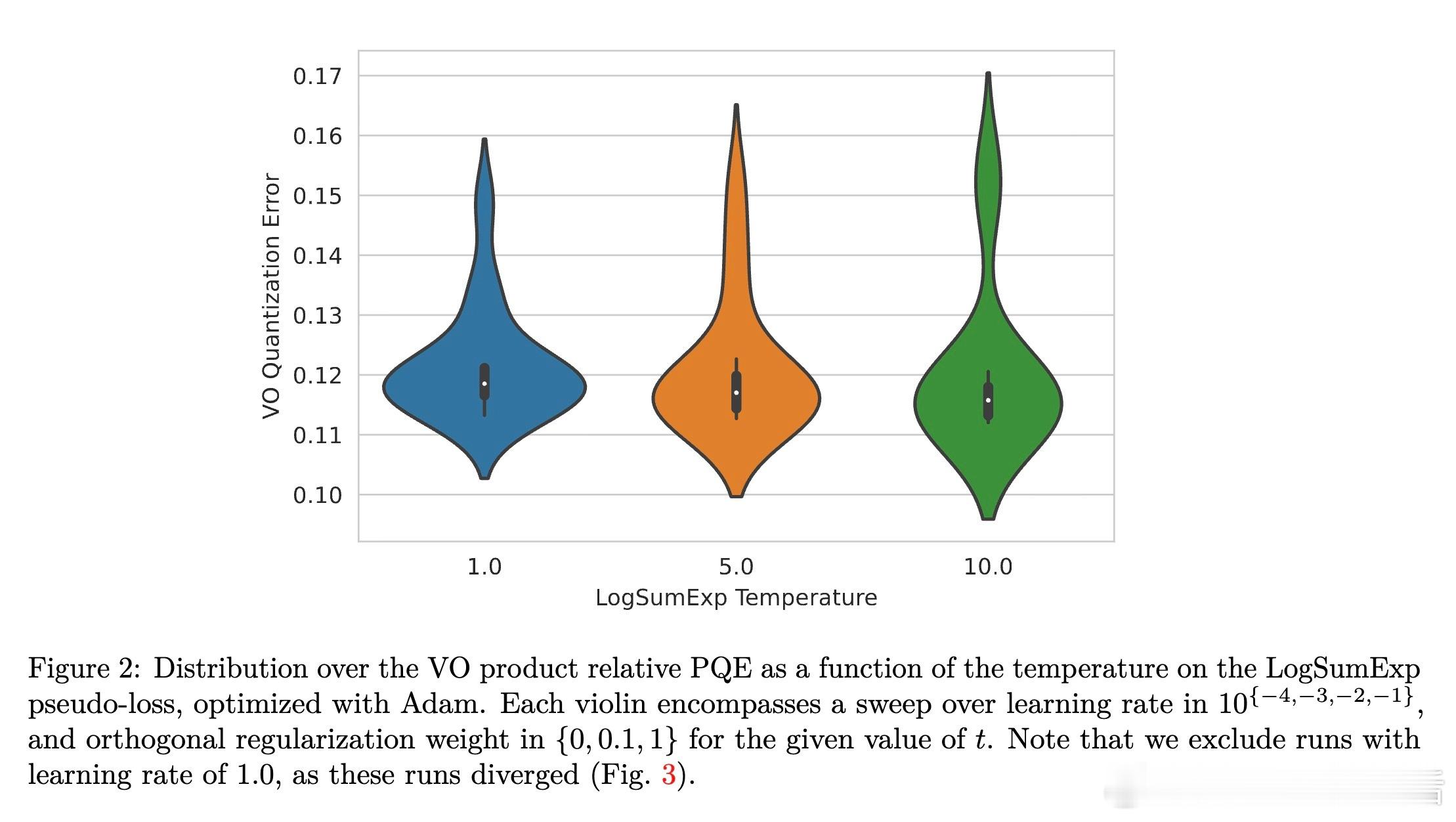
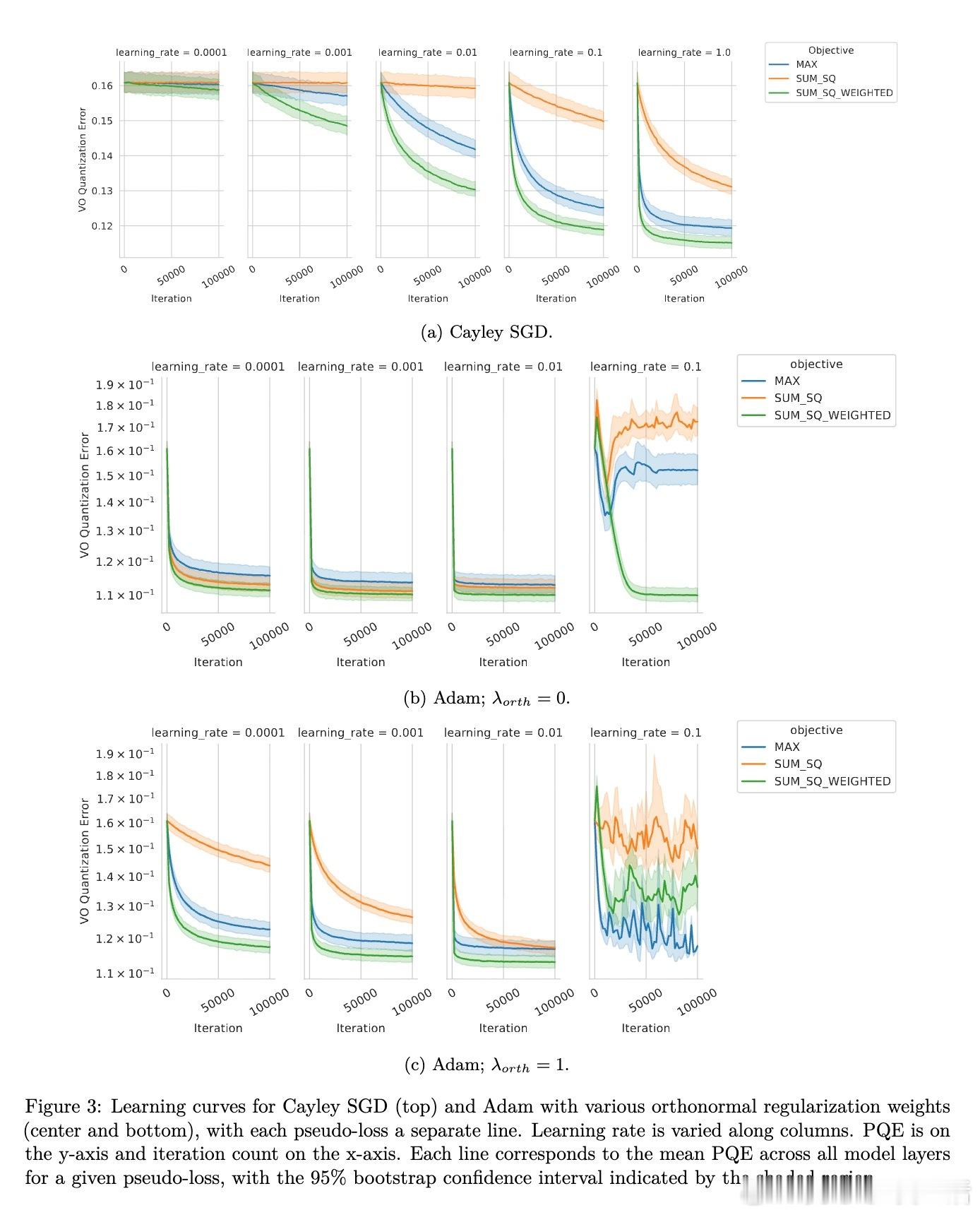
[LG]《CafeQ: Calibration-free Quantization via Learned Transformations and Adaptive Rounding》Z Sun, A Benton, S Kushnir, A Trockman... [Google] (2025) 大型语言模型(LLM)参数庞大,存储和推理成本高昂,后训练量化(PTQ)是减轻负担的有效手段。传统均匀量化因权重中的离群值导致误差较大,常依赖校准数据进行调优,但现实应用中校准数据往往不可得或受隐私限制。本文提出CafeQ,一种无需校准数据的量化方法,通过学习线性变换矩阵和自适应舍入技术来降低量化误差。核心思想包括:1. 离群值处理:设计代理损失函数,利用权重矩阵量化误差的Frobenius范数作为下游任务性能的良好代理指标,转化为可优化的目标函数,避免依赖真实校准数据。2. 单矩阵结构化变换:对单个权重矩阵学习块对角线结构的变换矩阵,兼顾减少离群值影响和推理时的计算效率,实验表明较大块尺寸(如128)能显著降低量化误差,且计算开销仅增加3%左右。3. 耦合矩阵联合量化:针对计算图中连续相乘的矩阵对(如Transformer中价值与输出矩阵Wv、Wo),学习一个可逆变换M,使得量化后矩阵乘积近似原矩阵乘积,无需额外在线计算,保证计算结果不变。4. 自适应交替舍入:提出一种迭代舍入算法,交替调整耦合矩阵的量化值,弥补单个矩阵独立量化引发的误差,进一步降低量化误差。在Gemma 2系列模型上,CafeQ在3-bit和4-bit量化场景均显著优于传统均匀量化及随机旋转方法,3-bit量化时平均基准分数从52.0提升至60.6,4-bit从61.9提升至62.4,且远超同类无需校准数据方法,性能接近需要校准数据的GPTQ。迭代优化算法复杂度合理,实际推理时计算开销极低。此外,研究表明:- 代理损失与下游任务性能高度相关,证实该无数据量化策略的有效性。- 变换矩阵不必严格为正交矩阵,放宽约束能获得更优解。- 不同Transformer子模块(前馈层、注意力矩阵对)均可受益于该方法。- 该方法具备良好的领域鲁棒性与隐私保护优势。总结来说,CafeQ突破了依赖校准数据的限制,实现了高效、精度优异的LLM后训练量化。未来可探索与校准数据方法结合,进一步提升性能。详细阅读请见:arxiv.org/abs/2511.19705