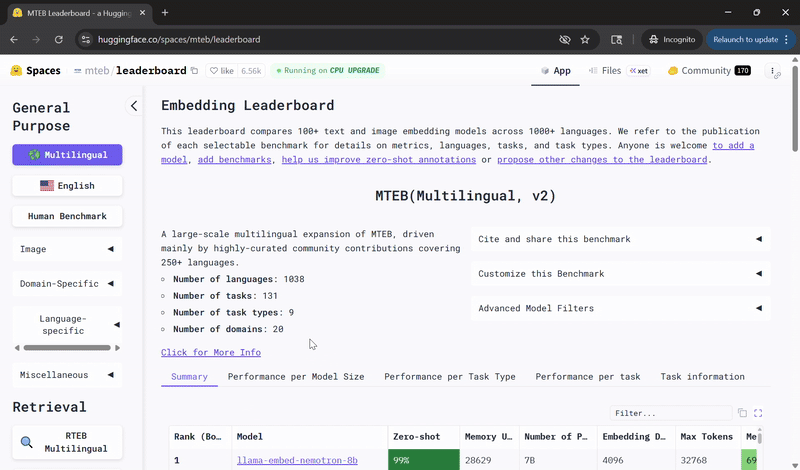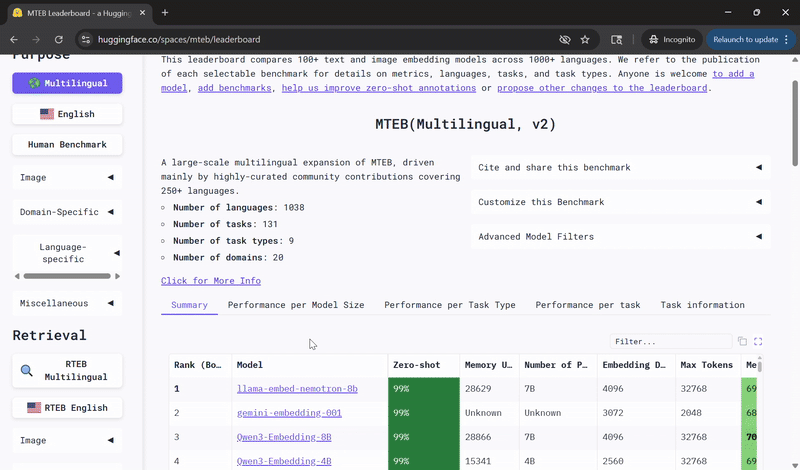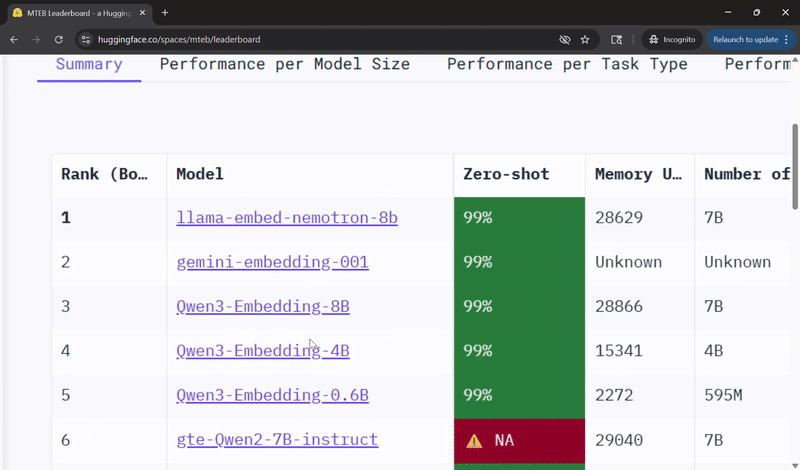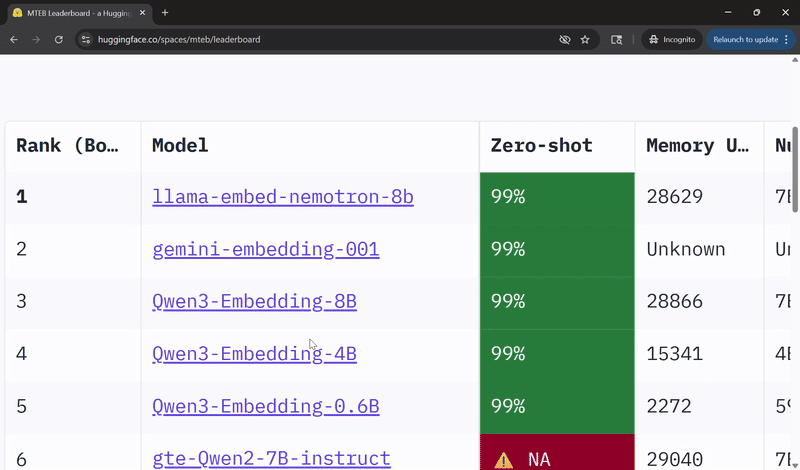
Llama-Embed-Nemotron-8B 文本嵌入模型现已位列 Hugging Face MMTEB 开放且可移植模型排行榜榜首! 为何能领跑榜单? 1. 在检索、重排序、分类和双语文本挖掘任务中性能表现出色 2. 能有效处理低资源语言检索任务及跨语言设置 3. 基于 1600 万组查询-文档对训练而成,其中 800 万组来自公开数据,另 800 万组为合成数据 4. 通过结合模型融合与精细化难负样本挖掘技术,进一步提升准确率 完整榜单地址: 下载试用:-embed-nemotron-8b