清一色美国榜单里,文心悄然跻身全球AI前十
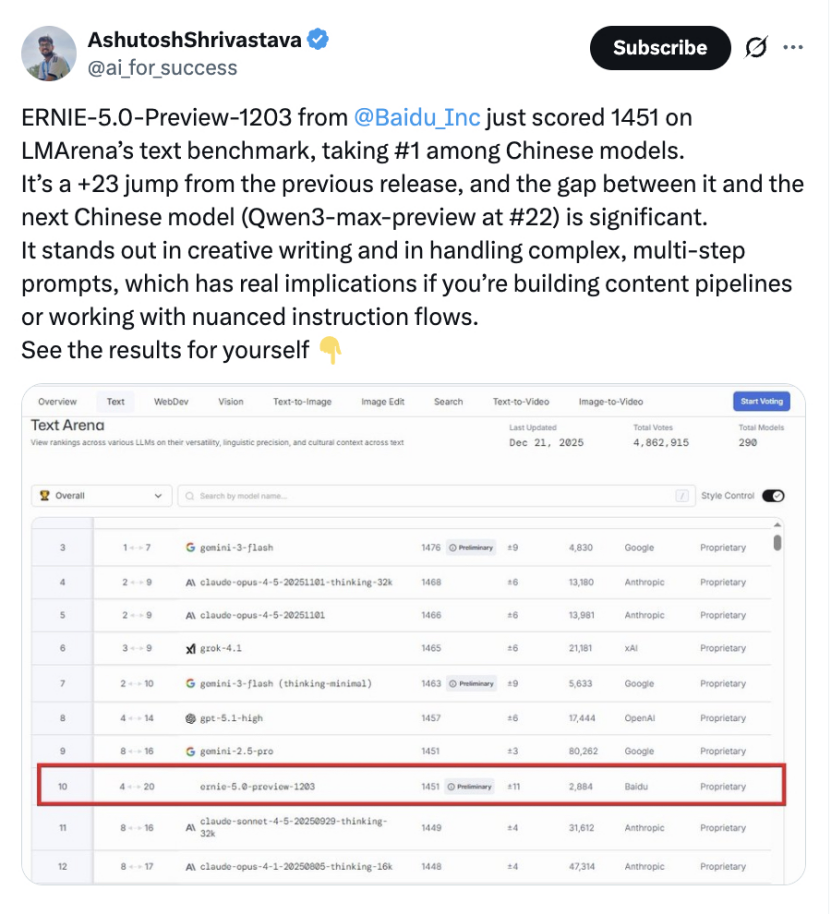
国际AI竞技场近日传来一个颇具象征意义的信号——在LMArena最新发布的全球大模型文本能力排行榜上,百度文心5.0预览版以1451分位列全球前十,成为该榜单前20名中唯一的非美国模型。
这个看似简单的排名变化,背后折射的却是全球AI竞争格局的深层演变。过去几年,当我们谈论顶尖AI模型时,话题几乎总是围绕OpenAI、谷歌、Anthropic等美国公司展开。国内模型虽然发展迅速,但在国际公认的评测体系中,往往被放在“中国区”或“其他”的类别中讨论,鲜有直接与美国顶尖模型同台较量的机会。
LMArena这一轮的排名更新,悄然改变了这种叙事逻辑。文心5.0不仅进入了主榜单前十,更在具体评分上超越了Claude Sonnet 4.5、GPT-5.2等国际知名模型。这意味着在国际评测体系中,中国模型已经从“能否参与国际竞争”的阶段,进入了“在国际竞争中能达到什么位置”的新阶段。
这种变化背后是评测逻辑的转变——LMArena采用的不是传统的标准化测试,而是基于真实用户匿名对战、聚焦实际应用场景的评估方式。模型需要在创意写作、复杂指令理解、逻辑推理等高度贴近实际使用的任务中接受考验。文心在这些维度上的突出表现,特别是超越国际主流模型的能力点,说明中国大模型的技术突破已经进入了“深水区”。
当我们仔细分析榜单结构,会发现一个更加耐人寻味的现象:排名前20的模型中,19个来自美国科技公司,只有文心5.0这一个“异类”。这种“清一色美国阵容中出现中国选手”的局面,在一年前的国际AI评测中几乎是不可想象的。
这不仅仅是百度一家的突破,更代表着中国AI研发整体实力的提升。从“中国版GPT”的标签,到在国际舞台上拥有独立的技术身份和竞争力坐标,中国大模型正在完成一次重要的身份转变。
更深层的意义在于标准话语权的演变。长期以来,国际AI评测的话语权主要掌握在美国机构和研究者手中。中国模型能够在美国主导的评测体系中取得突破性成绩,不仅证明了自身的技术实力,也开始参与到国际AI能力标准的构建过程中。
值得注意的是,此次登榜的还是文心5.0的“预览版”。据行业消息,正式版将于明年1月发布。这让人不禁期待:预览版已经能在国际赛场上取得如此成绩,正式版将会带来怎样的表现?
从全球AI发展的大背景看,这种多极化趋势正在加速形成。当中国模型开始稳定出现在全球顶尖模型名单中,当国际评测不再只是美国模型的“内部排名”,全球AI创新生态将变得更加多元和富有活力。
对于国内AI行业而言,这不仅仅是一次排名的提升,更是一个重要的里程碑。它标志着中国大模型已经具备了与国际顶尖水平同台竞技的技术底气,也为接下来的技术突破和应用落地提供了更强的信心支撑。
全球AI竞技场正在从“单极引领”向“多极竞争”演变,而文心5.0在LMArena上的这次亮相,或许正是这一转变开始加速的标志性事件。接下来的悬念是:中国模型能否在这个新格局中,从“参与者”转变为“定义者”?这将是观察2026全球AI竞争态势的重要视角。
#百度# #文心一言# #文心# #文心大模型# #AI# #AI大模型# #科技# #AI技术# #干货分享#