在英伟达 GTC 2026论坛上,理想团队讲得很直接,VLA不仅可以用来控制车辆,也能够扩展到机器人。
这相当于是对自动驾驶的重新定位,智驾不再是终点,而是整个物理世界AI体系里的一个起点。
以前大家做自动驾驶更像是在做一道专项题,现在开始有人想做一套通用能力。
如果换个角度看,车本身就是一个标准化程度最高的大号机器人,
有传感器、有执行系统、环境相对可控,很像一个训练场。
先把能力在这里练出来,再往更复杂的世界扩展。
理想最近在讲的具身智能,其实核心就是这件事,
不再是单独只做一辆会开车的司机,而是在搭一个可以迁移到不同「身体」上的大脑,具备物理世界的通用能力。
从车,到人形机器人,再到更多物理载体,本质是同一套能力的延伸。
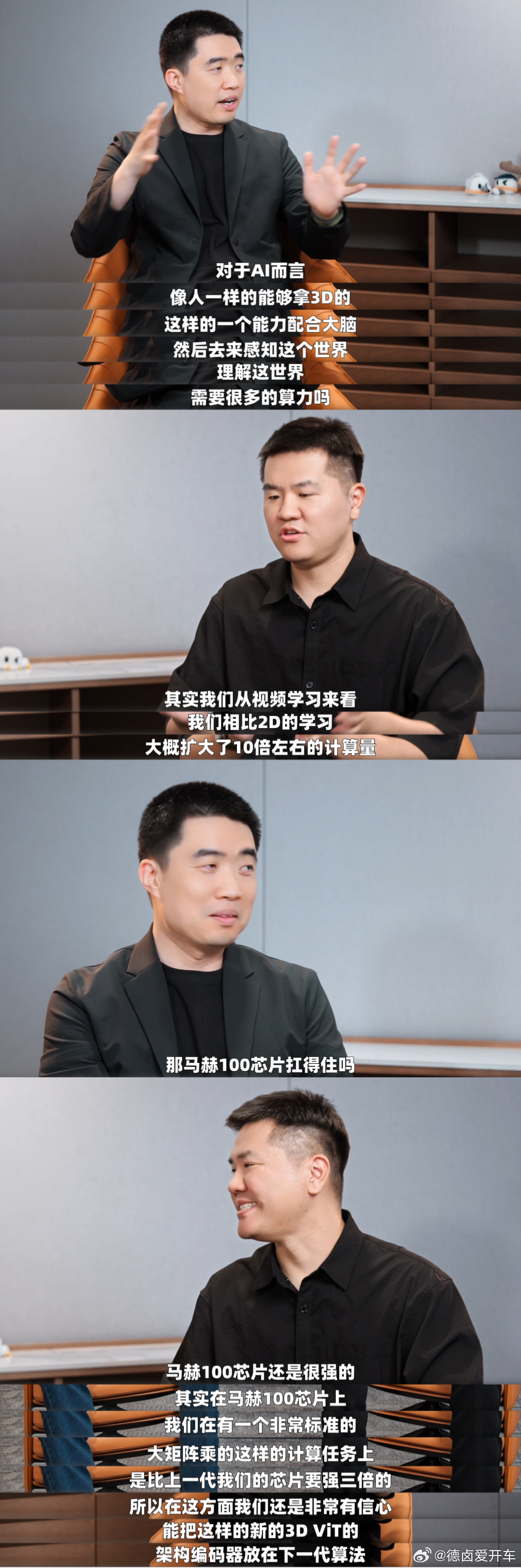
这一代 MindVLA-o1 的核心变化,就在补这块基础能力,而不是只追求某个场景下的性能提升。
重点放在3D世界理解上,让模型从看2D图像,走向真正理解空间结构。
可以理解为,从看平面视频,变成脑子里有一个立体世界。
通过3D ViT去还原空间、语义和动态信息,再叠加多模态思考和隐空间里的世界模型,
系统开始具备一种更接近人的能力,在脑子里预演未来。
就像人走路时,会下意识判断地面高低、障碍物位置,而不是每一步都临时计算。
这一步的意义在于,一旦模型建立的是统一的三维认知,
而不是为驾驶特化的一套表达,它就具备了天然的迁移能力。
开车和做人形机器人的动作,本质差别只是一个在控制方向盘,一个在控制四肢,但背后的判断逻辑是共通的。
这也是为什么理想会把VLA往人形机器人延展。
模型不只是为「开车」服务,而是为「在物理世界行动」服务。
当数据引擎、模型结构、仿真体系和强化学习框架被打通之后,这套系统就不再局限在车上。
车上积累的数据可以训练机器人,机器人在复杂环境中的经验也可以反过来优化自动驾驶。
从工程角度看,这条路线更重,但一旦跑通,将会形成自动驾驶和具身智能的垂直整合的局面。
最终用一套基础模型,来驱动不同形态的具身智能。
所以从长期来看自动驾驶只是理想的第一站,而具身智能将会是理想的下一站。
真正的目标,是一个可以在不同物理载体之间迁移的通用智能体。
因此看待各家的技术范式路线时,更要看到背后的战略发展方向。
李想称机器人也用VLA李想称机器人也用VLA理想全能辅助驾驶来了理想发布下一代自动驾驶基础模型